
1. 현상 조사

요약: 현상 조사 결과, 서비스 오작동의 원인은 운영환경의 오설정에 따른 메모리 이슈일 가능성이 높다
가. 일부 API 간헐적 동작이상
•
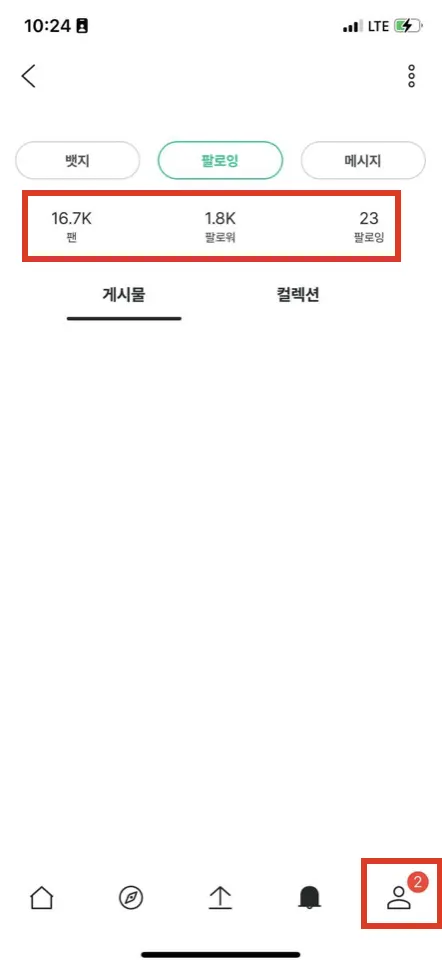
‘콘텐츠 목록 조회 API’가 간헐적으로 멈추는 현상이 발생했다. 대부분의 다른 API는 정상 동작했다. 참고 이미지에서 확인할 수 있듯이 게시물란의 콘텐츠는 출력되지 않는다. 반면 팔로워, 팔로잉 및 알림은 정상적으로 출력되고 있다.
참고) 제품 내 현상 이미지
나. 로그 확인
•
일부 API에 한정하여 간헐적으로 발생한 이슈였기 때문에 연관 로그를 특정하기 어려웠다. 이슈가 발생한 시간대에는 OutOfMemory(이하 OOM) Error 로그 외에도 원인으로 의심할만한 로그가 다수 있었다. 하지만 메모리 소요가 큰 ‘컨텐츠 목록 조회 API’의 동작이상에 OOM Error 로그가 더해지니 해당 현상은 OOM 이슈일 가능성이 제일 높다고 판단했다.
참고) OutOfMemoryError Log

다. 재현 실패
•
‘콘텐츠 목록 조회 API’의 간헐적 멈춤 현상을 재현하기 위해 로컬 환경에서 부하 테스트를 시도했다. 부하 테스트는 Jmeter를 활용하여 주요 API를 다수 호출하는 방향으로 진행했다. 테스트 결과, GC에 의해 Heap Memory가 정상적으로 관리되고 있었기 때문에 동일 현상은 발생하지 않았다. 로컬 환경에서 재현이 실패함에 따라 OOM 이슈의 원인은 운영환경에 있을 것이라고 의심했다.
참고) 로컬 환경 부하테스트 결과

2. 원인 추정: QueryPlanCache 오설정
요약: Heap Dump 분석 결과, QueryPlanCache의 메모리 점유율은 높지만 OOM의 원인일 가능성은 낮다
가. Heap Dump 생성
1) Fargate 내 SSH 접속 포인트 생성
•
Docker 이미지 내 ssh connector 설치 후, SSH Connectinon을 생성하여 Heap Dump를 Fargate에서 로컬로 가져왔다. 참고로 ECS Exec 활용하여 Fargate에 접속할 수도 있지만, 작업 정의 및 IAM 권한 일부 수정 작업 필요하여 의도치 않게 서비스 운영에 영향을 줄 수 있다. 실제로 ECS Exec 설정 중 Staging 서버가 멈췄다. DevOps 담당자가 없는 관계로 인프라 영향을 최소화할 수 있는 방향으로 작업하기 위해 Docker Image 내 Open SSH를 설치하는 방법을 선택했다.
•
참고로 WAS 직통 커넥션 포인트를 생성하는 것은 보안상 문제가 될 수 있으므로 heap dump를 얻은 후 위의 설정은 모두 리셋해야 한다.
참고) AWS CLI Configuration Command
AWS CLI 설치: apt install awscli
AWS Configure: aws configure
Plain Text
복사
참고) SSH Traffic
◦
SSH 트래픽을 허용하기 위해 보안그룹의 인바운드 규칙에서 22번 포트의 내 IP를 허용했다.
2) Heap Dump 생성
•
인스턴스 생성부터 메모리 사용률의 변화양상에 따라 총 5번의 Heap Dump 생성했다.
참고) Heap Dump Creation Command
◦
java path가 등록되어 있지 않기 때문에 jdk directory 이하에서 jmap 경로를 찾아서 이하 명령을 실행했다.
java process id 확인: pgrep java
heap dump 생성: jmap -dump:file=<dump file name>.hprof <PID>
ex) /usr/local/openjdk-11/bin/jmap -dump:file=heap_dump.hprof 7
Plain Text
복사
3) Upload & Download Heap Dump
•
AWS CLI & S3 Bucket 활용하여 Heap Dump file을 서버에서 로컬로 가져왔다. 생성된 Dump file을 서버에서 S3 Bucket으로 업로드하고, S3 Bucket에서 로컬로 다운로드했다.
참고) AWS CLI S3 Command
업로드: aws s3 cp <file to move> <s3 bucket url>
ex) aws s3 cp heap_dump.hprof s3://om-public-storage/heap-dump/production/
다운로드: aws s3 cp <s3 object url> <local path to move>
ex) aws s3 cp s3://om-public-storage/heap-dump/production/heap_dump.hprof .
Plain Text
복사
나. Heap Dump 분석
1) Dominator Tree 분석
•
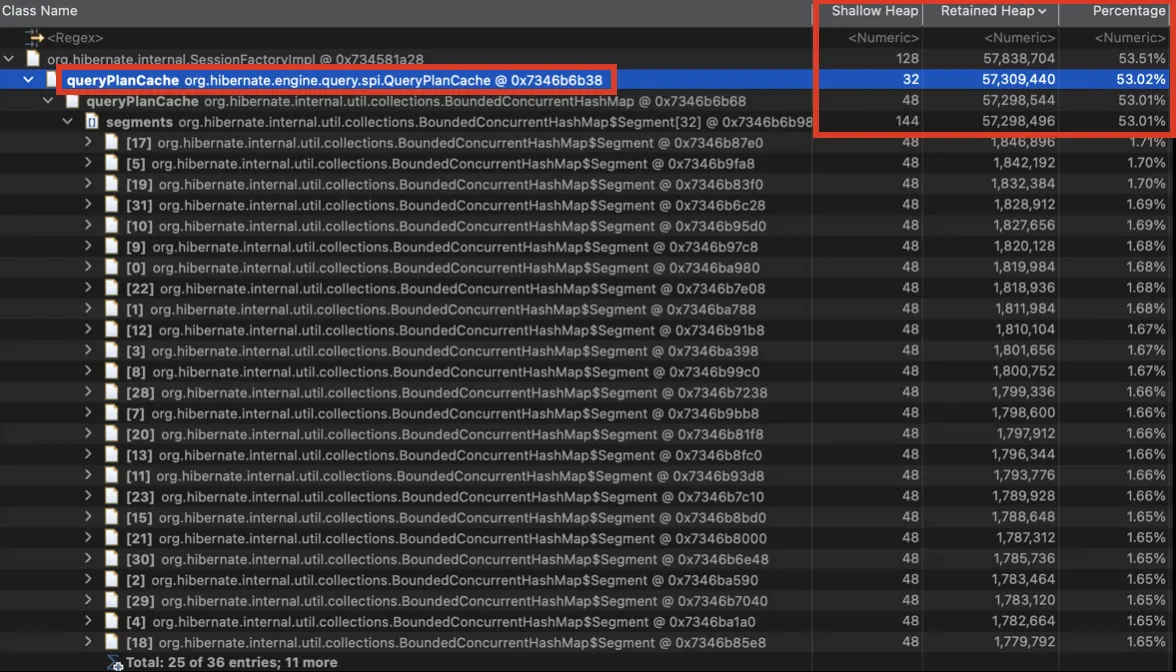
Dominator Tree 기능은 하나의 클래스가 메모리 누수의 원인일 경우에 분석하기 용이하다. Dominator Tree는 Class별로 메모리 점유율과 함께 하위 클래스를 확인할 수 있다. 메모리 점유율이 가장 높은 상위 클래스에서부터 하위 클래스를 추적할 수 있다. Shallow Heap 대비 Retained Heap 값이 높은 Class가 메모리 누수의 원인일 가능성이 높다.
•
Dominator Tree 분석 결과, 메모리 점유율이 높은 Class 중 QueryPlanCache가 가장 의심스럽다. Shallow Heap 대비 Retained Heap이 크고, 하위 HashMap 클래스에 50% 이상의 메모리가 할당되어 있다.
참고) 용어 정리
◦
QueryPlanCache: JPQL을 Native Query로 변환하기 전 Caching에 사용되는 클래스
◦
Shallow Heap: 객체 자체에 할당된 Heap Memory
◦
Retained Heap: Shallow Heap을 포함하여 객체에 할당된 모든 Heap Memory
참고) Histogram 분석 자료
2) Histogram 분석
•
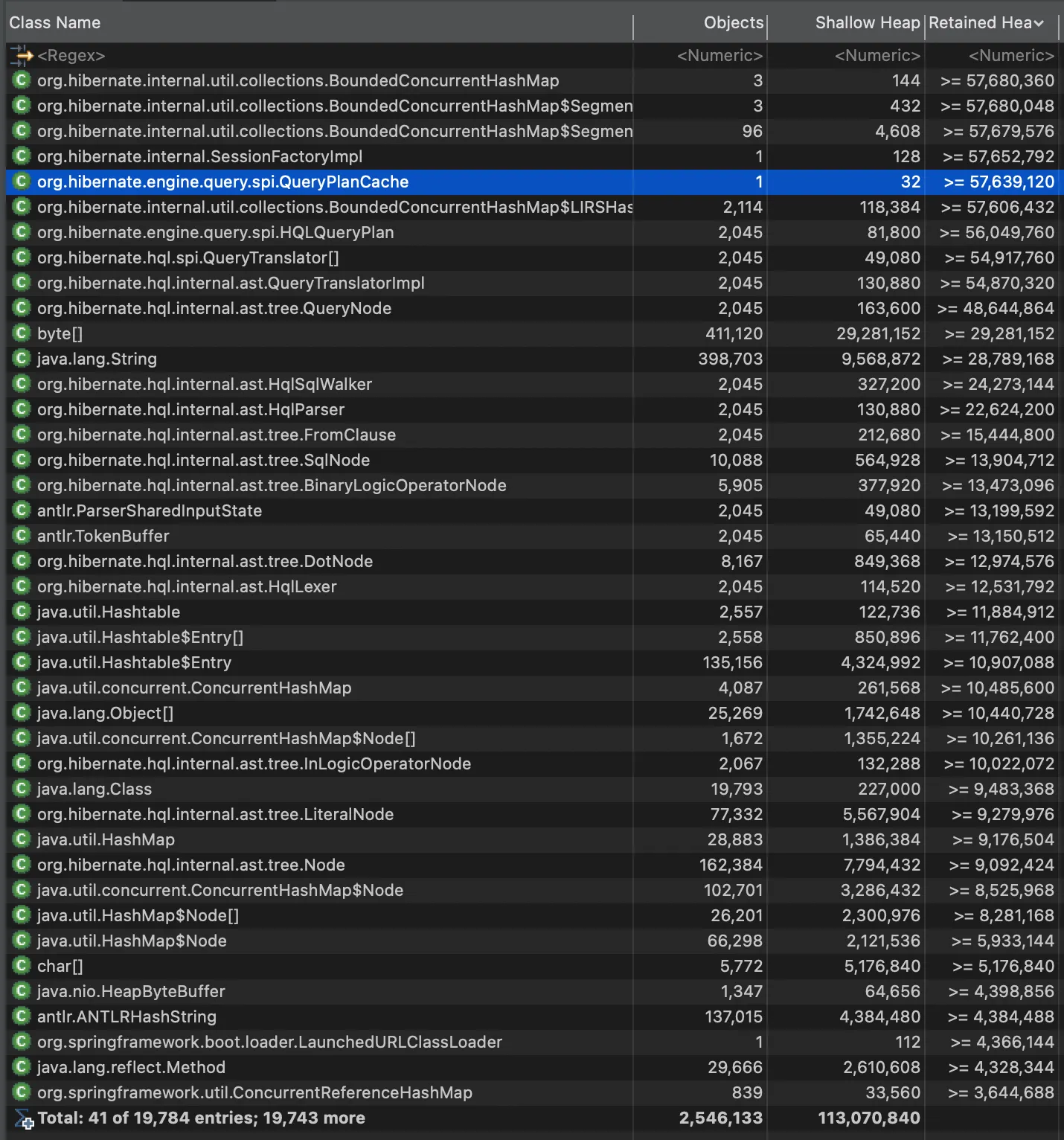
Histogram 기능은 여러 클래스가 메모리 누수의 원인일 경우 유용하게 사용할 수 있다. Histogram은 Class별로 생성한 인스턴스 개수와 Shallow Heap과 Retained Heap 값을 확인할 수 있다. 인스턴스의 개수가 적지만 Shallow Heap 대비 Retained Heap 값이 큰 Class가 메모리 누수의 원인일 가능성이 높다.
•
Histogram 분석 결과, QueryPlanCache Class와 SessionFactoryImpl Class의 경우, 생성된 인스턴스는 1개지만 Shallow Heap 대비 Retained Heap이 매우 큰 것을 보아 충분히 의심스럽다.
참고) Histogram 분석 자료
3) Leak Suspect 분석
•
Leak Suspect 기능은 이미 빈번하게 발생한 이슈의 경우에 메모리 누수의 원인을 쉽게 파악할 수 있다. 하지만 빈번한 이슈가 아닌 경우 ‘Histogram’과 ‘Dominator Tree’을 확인해야 정확한 원인을 파악할 수 있다.
•
Leak Suspect 분석 결과, SessionFactoryImpl Class와 LaunchedURLClassLoader Class를 메모리 누수의 원인으로 지목한다. 하지만 Historgram 및 Dominator Tree를 확인해보면 QueryPlanCache가 더욱 의심스럽다는 것을 확인할 수 있다.
다. 검증
1) 검증 방법
•
OOM 이슈의 추정 원인에 대한 검증은 논리적 연관성을 확인하는 방향으로 진행했다. 엔지니어링 관점에서 검증은 추정 원인을 변수화해서 이슈의 재현여부를 확인하는 것이 이상적이다. 하지만 비지니스 환경에서 빠른 대응을 위해 검증 과정을 간소화했다.
2) QueryPlanCache MaxSize 오설정에 따른 OOM 발생 가능성
•
QueryPlanCache와 OOM을 키워드로 검색해본 결과, QueryPlanCache가 전체 서버 메모리 할당값의 80% 이상을 차지하여 OOM 이슈가 발생한 사례를 확인했다. QueryPlanCache의 최대 크기에 대한 기본값은 2GB이기 때문에 서버 메모리 할당값이 2GB 내외로 설정된 경우 OOM 이슈가 발생한다는 것이다. 하지만 이슈 발생 시, 서버 메모리의 경우 Max Size 보다 두 배 가까이 할당했기 때문에 QueryPlanCache MaxSize 오설정에 따라 OOM이 발생할 가능성은 낮았다.
3) QueryPlanCache의 Cashing 비효율에 따른 OOM 발생 가능성
•
JPQL에 In절을 다수 사용하지만 비효율적으로 caching이 발생하여 OOM 이슈가 발생한 사례도 있었다. JPQL에 in절이 일부 사용되었지만 굉장히 드물게 사용하는 API에 적용되어 있었다. 더불어 padding 설정 전후 메모리 사용 양상을 확인하기 위해 로컬환경에서 부하 테스트를 해봤지만 설정 전후 큰 차이가 없었다.
•
참고) QueryPlanCaching 중 IN 절의 인자에 대한 캐싱 전략 효율화 설정
jpa:
hibernate:
query:
in_clause_parameter_padding: true
YAML
복사
3. 원인 추정: Linux User Limit 오설정
요약: 서버 메모리 대비 User Limit이 과설정 됐지만, 실제 요청수는 수용 가능한 수준이었기 때문에 OOM의 원인일 가능성은 낮다
가. Linux User Limit 분석
1) 메모리 스펙 비례 ulimit 설정
•
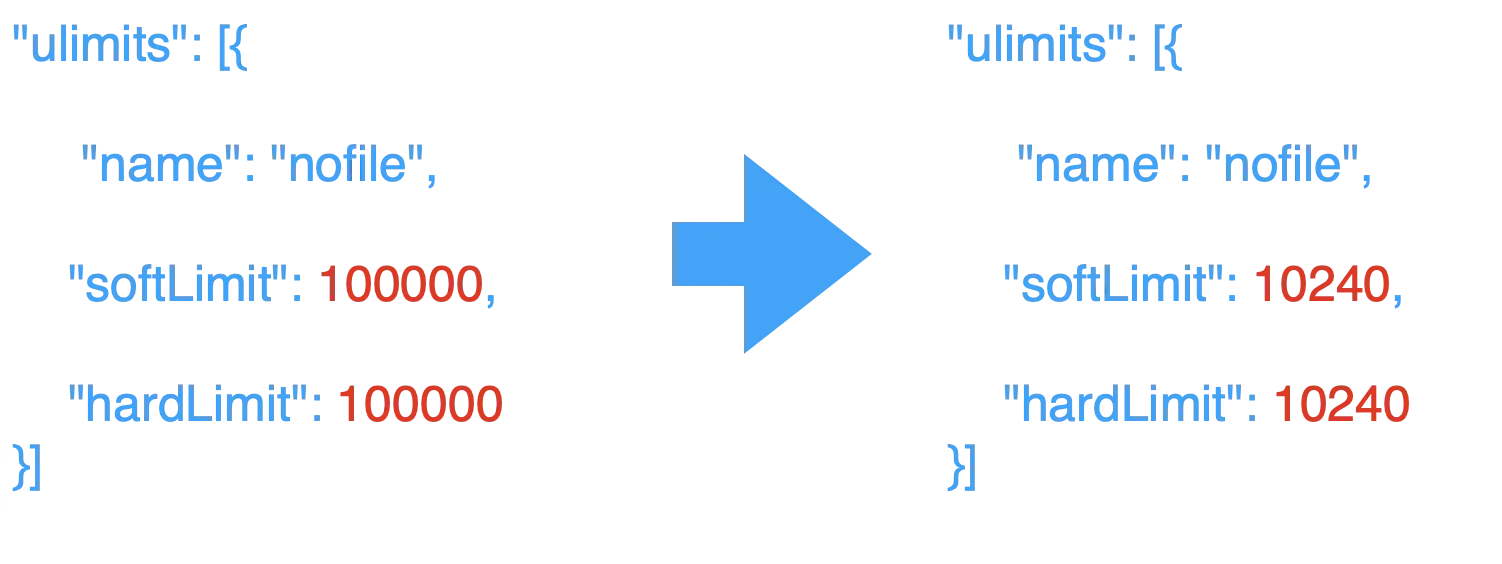
동료 개발자로부터 Linux ulimit(User Limit) 오설정에 따라 OOM 이슈의 발생 가능성이 있다는 조언을 들었다. ulimit은 HTTP API Sever에서 한 번에 호출할 수 있는 API 호출 제한이다. 하나의 API 호출이 발생하면 해당 호출을 담당할 쓰레드를 배정해야 한다. 쓰레드는 작업할 때 개별적인 메모리가 필요하기 때문에 ulimit 설정값은 서버 전체 메모리와 비례관계가 되어야 한다. AWS EC2의 설정값을 참고하면 서버 메모리에 4GB를 할당 시 ulimt 값은 10,240 정도가 적절하다. 하지만 기존 설정값은 100,000으로 설정되어 있었다. 만약 메모리가 4GB 할당된 서버에서 API 호출이 10,240을 넘어 5만, 10만에 달했다면 OOM 이슈가 발생할 가능성은 높다.
2) ulimit 설정값 수정
•
hardLimit과 softLimit의 값을 모두 10,240으로 수정했다. softLimit을 hardLimit과 동일하게 설정한 이유는 어플리케이션의 작업이 대부분이 Memory Bound 작업이기 때문이다. 만약 CPU Bound 작업이 주가 되었다면 sofLimit과 hardLimit을 별개로 설정하여 유연하게 자원을 할당하도록 수정했을 것이다. 참고로 Memory Bound 작업이 주라고 판단한 이유는 모니터링 지표에 따르면 CPU 사용률 대비 Memory 사용률이 앞도적으로 높기 때문이다.
참고) ulimit 설정 수정
참고) 용어 정리
•
nofile(Number of File): 하나의 프로세스가 한 시점에 다룰 수 있는 파일의 개수. 참고로 UNIX의 ‘everything is file’이라는 관점에서 socket interface는 file interface와 동일하게 볼 수 있다.
•
softLimit: nofile의 기본값
•
hardLimit: softLimit에서 최대로 높일 수 값
나. 검증
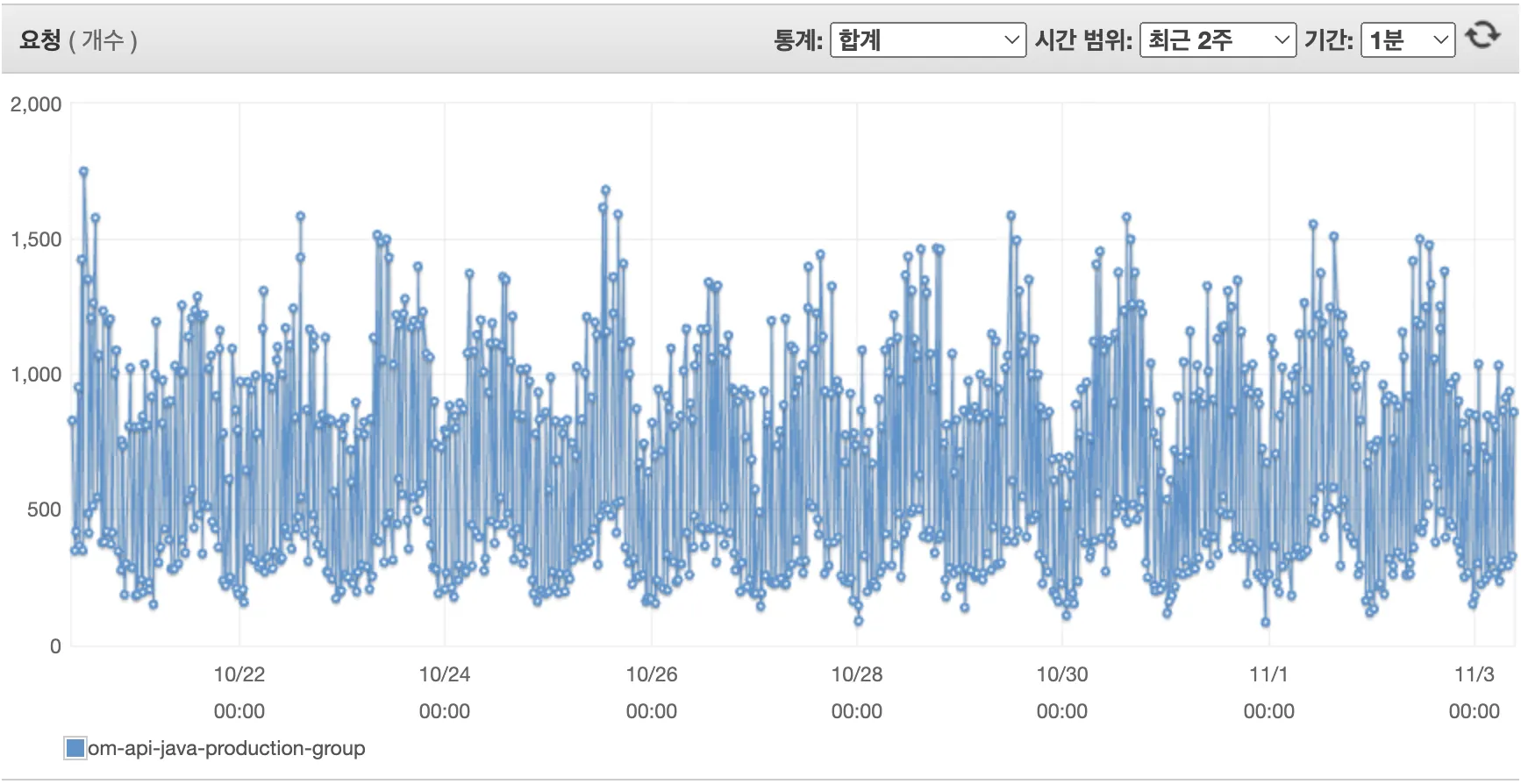
1) 상용 서버의 분당 최대 요청수 분석
•
과설정된 ulimit(100,000)으로 인해 OOM 이슈가 발생했다면, 이슈 발생 시점의 최대 요청수는 10,240(메모리 할당량에 따라 적절하게 설정된 ulimit)에 가깝거나 그 이상이어야 했다. 하지만 API 요청수애 대한 지표를 보면 분당 최대 요청수는 10,240은 커녕 2,000 미만이었다. 따라서 ulimit에 과설정 부분이 있었을 지라도, 이로 인해 OOM 이슈가 발생할 가능성은 낮았다.
참고) 분당 최대 요청수
4. 원인 추정: Scale In & Out 정책 오설정
요약: 메모리 소요가 높은 상황에서 CPU 사용률 기준으로 서버 인스턴스를 자동감소시켜 OOM 이슈가 발생했다
가. 모니터링 지표 분석
1) 모니터링 지표 분석
•
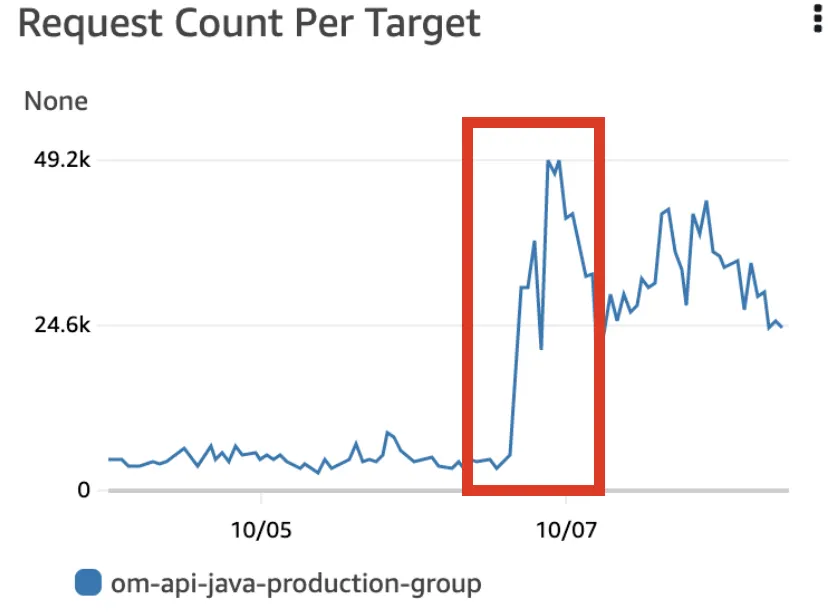
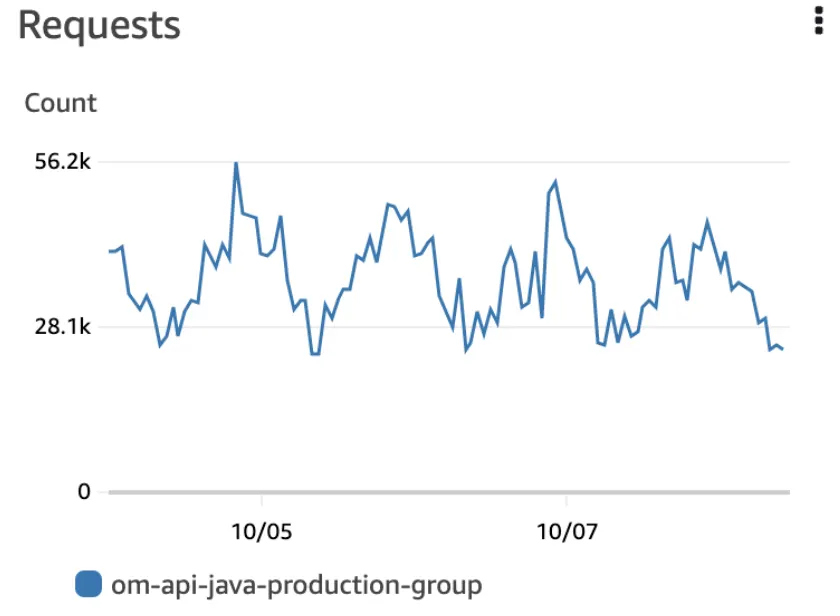
Scale In & Out 정책 오설정을 원인으로 추정한 이유는 모니터링 지표 상 특이사항이 있었기 때문이다. ‘Requests’ 지표는 균일한 형태를 보이지만 ‘Request Count Per Target’과 ‘Target Response Time’ 지표는 전혀 균일하지 않은 형태를 보이고 있다. 지표를 해석하자면, 로드 밸런서의 ‘대상그룹’에 전달되는 트래픽은 동일하지만 ‘대상 그룹’ 내 서버 인스턴스별로 전달되는 트래픽은 크게 상승했다. 그 이유는 Scale In & Out 정책에 있었다.
참고) 모니터링 지표 이미지

참고) 용어 정리
•
Requests: 로드 밸런서의 ‘대상 그룹’ 전체에 대한 요청 수, 집계 기준은 한 시간 기준으로 요청에 대한 합계
•
Request Count Per Target: 로드 밸런서의 ‘대상 그룹’ 전체가 아닌 서버 인스터스별 요청 수, 집계 기준은 Requests 지표와 동일
•
Target Response Time: 로드 밸런서의 ‘대상 그룹’ 내 서버 인스터스별 요청에 대한 응답 시간, 집계 기준은 한 시간 기준으로 요청에 대한 응답 시간의 평균
나. 검증
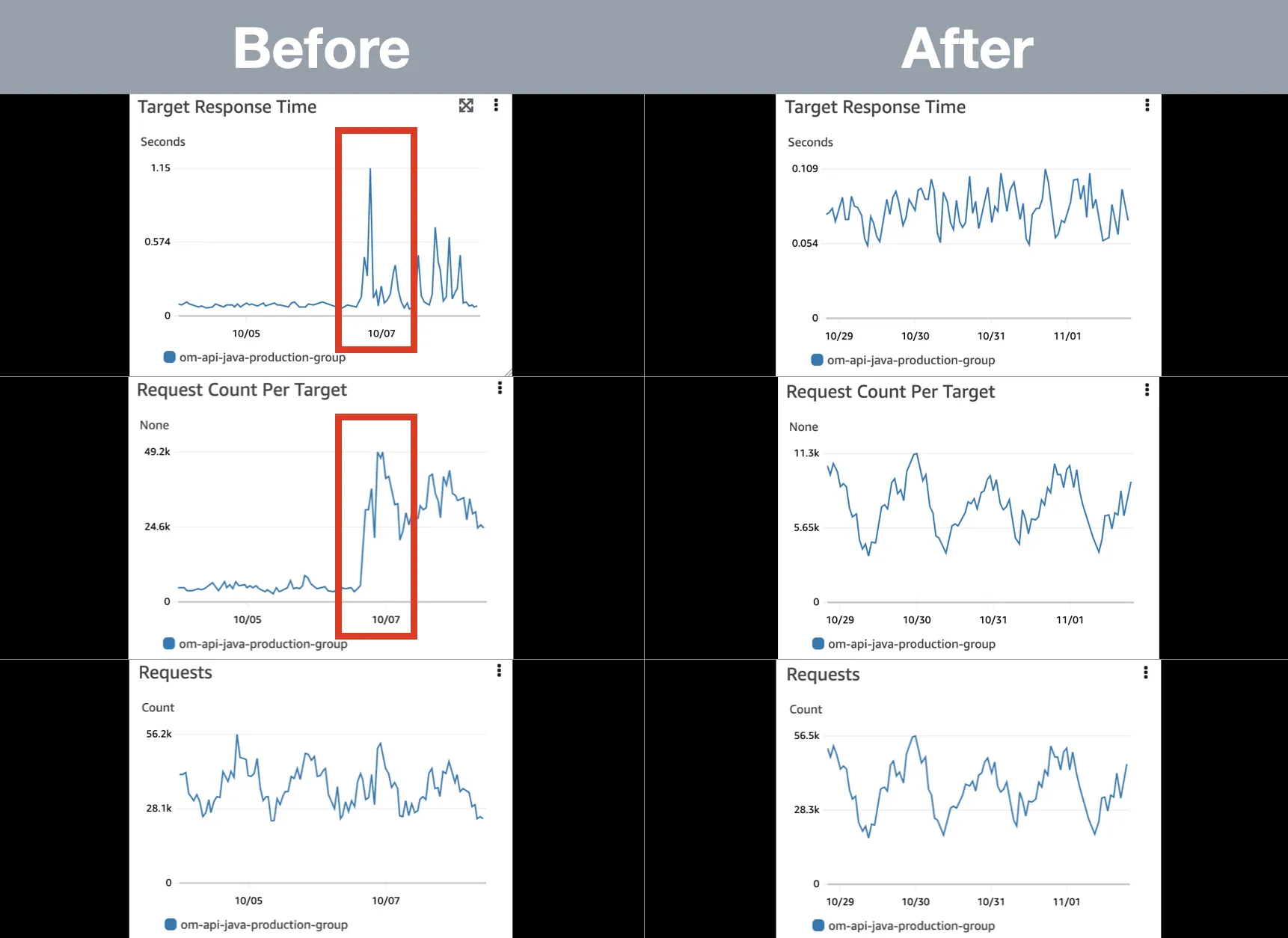
1) 서버 인스턴스 증가 후 모니터링 지표 변화
•
서버 인스턴스 개수를 기존 최대치에서 2배 늘려 고정 운영했다. 그 결과 ‘Target Response Time’과 ‘Request Count Per Target’ 지표가 균일한 형태로 변했다.
2) OOM Error Log 미발생
•
더이상 OOM Error Log가 발생하지 않았다. 서버 인스턴스를 고정 운영한 후 2주일 지난 시점에도 단 한 건의 관련 Log가 발생하지 않았다. OOM 이슈가 일단락되었다.
참고) 서버 인스턴스 증가 후 모니터링 지표 변화
5. 향후 계획
가. 모니터링 지표의 다양화
•
OOM 이슈를 계기로 다양한 모니터링 지표를 확보하기 위해 Cloud Watch Agent를 서버 인스턴스에 심었다. 기존 모니터링 지표 외에도 다양한 지표를 확보해서 추후 운영환경 이슈 발생 시 보다 빠르게 대응할 것이다.
나. Scale In & Out 기준 재정립
•
이슈 발생 후 운영 환경의 안정화를 위해 서버 인스턴스를 고정하여 운영하고 있다. 하지만 Scale In & Out 정책은 운영환경 효율화에 따른 비용절감을 위해 반드시 필요하다. CPU 사용률 외에도 여러 기준을 비교 분석해서 Scale In & Out 정책을 재정립할 것이다.
참고 자료
•
Setting User Limits
•
The Relation between Socket and Open Files