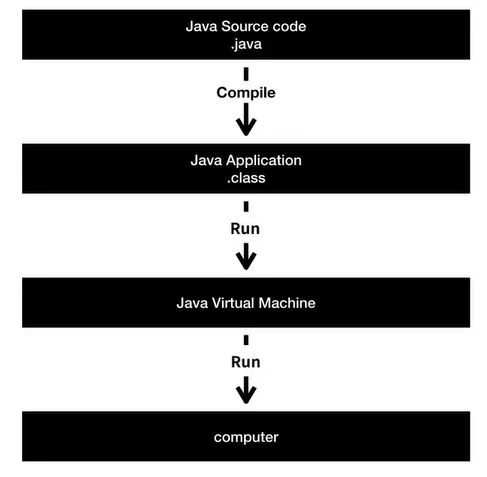
1. Java 동작원리
가. 전체적인 동작 원리
1) compile
•
.java 파일을 컴파일하면 .class(byte 코드) 파일로 변환
2) interpret
•
.class(byte 코드) 파일은 JVM의 인터프리터에 의해 기계어로 변환됨
(image from 생활코딩 egoing)
나. 세부적인 동작 원리
1) 컴파일 타임 환경
2) 런타임 환경
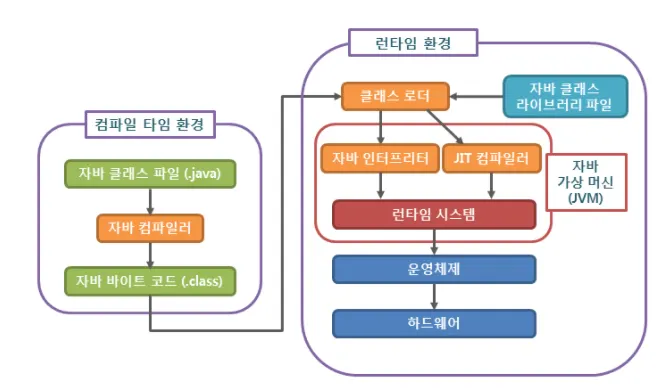
image from TCPschool.com
다. Call by Value vs Call by Reference

Call by value: 매개변수의 값 그 자체를 전달함. 기본형 매개변수의 값(int 10)을 전달하면 함수에서 내부에 값 변경이 반영 X. 하지만 참조형 매개변수의 값(Object object)을 전달하면 함수에서 본문의 변수를 바라볼 수 있으므로 변경이 반영됩니다.
•
java는 call by value 방식을 지원함.
•
Call by value vs Call by reference
: Call by value란 함수 호출 시 매개변수를 전달할 때, 매개변수의 값을 전달함
: 반면 Call by reference의 경우, 변수의 주소(메모리 상 위치)를 전달함
•
Call by Value의 경우 기본 타입에 대해 혼선이 없지만 참조 타입의 경우 헷갈릴 수 있습니다.
: 객체를 매개변수로 전달할 경우, 매개변수에 대한 참조‘값’을 기준으로 객체 내부의 변경이 함수 외부에도 반영됩니다. 하지만 참조는 값이기 때문에 함수 내부에서 해당 값에 다른 객체를 대입하면 더이상 기존 객체에 대한 변경이 외부에 반영되지 않습니다.
•
Call by Reference의 경우, 주소(reference, 메모리 상 위치)를 매개변수로 전달합니다. 함수 내부에서 해당 매개변수에 다른 객체를 대입하면 더이상 기존 객체가 아니라 새로운 객체를 가리키게 됩니다. 따라서 함수 외부의 변수도 함수 내부에서 새로 할당한 객체를 참조하게 됩니다.
•
예제: Java(call by value) vs C++(call by reference)
// Call By Value
class Car {
String color;
}
public class Test {
public static void changeCarColor(Car car) {
car.color = "Red"; // This change will reflect outside the method
car = new Car(); // This will not reflect outside the method, because we're changing the reference, not the object it points to
car.color = "Blue";
}
public static void main(String[] args) {
Car myCar = new Car();
myCar.color = "Green";
changeCarColor(myCar);
System.out.println(myCar.color); // Prints "Red", not "Green" or "Blue"
}
}
Java
복사
#include <iostream>
#include <string>
struct Car {
std::string color;
};
void changeCarColor(Car*& car) {
car->color = "Red"; // This change will reflect outside the function
car = new Car(); // This change will also reflect outside the function
car->color = "Blue";
}
int main() {
Car* myCar = new Car();
myCar->color = "Green";
changeCarColor(myCar);
std::cout << myCar->color << std::endl; // Prints "Blue", not "Green" or "Red"
delete myCar;
return 0;
}
C++
복사
라. 인스턴스 멤버와 클래스 멤버 간 호출
•
같은 클래스 내 멤버 간에는 인스턴스를 생성하지 않아도 상호 참조 및 호출 가능
•
인스턴스 멤버가 클래스 멤버를 참조 및 호출할 때 에러 발생하지 않음
•
반대로 클래스 멤버가 인스턴스 멤버 참조 및 호출 시에는 문제 발생
→ static으로 선언된 메소드나 변수가 클래스 멤버의 생성 시점은 인스턴스 멤버의 생성 시점 보다 빠르기 때문에 인스턴스 멤버에 대해 참조 및 호출 시에 해당 멤버는 존재하지 않으므로 에러 발생
2. 변수 타입
가. 정수형 타입
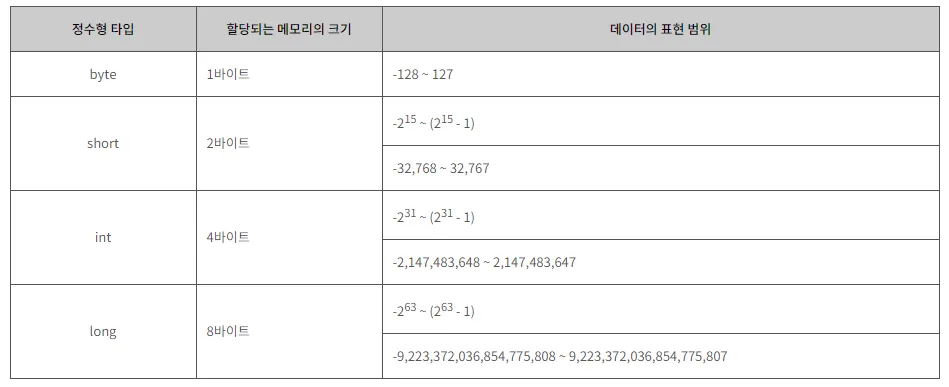
image from TCPschool.com
나. 실수형 타입
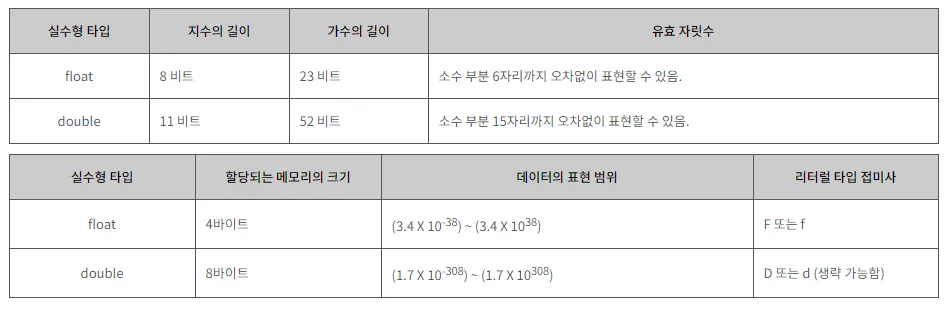
image from TCPschool.com
다. 문자형 타입

image from TCPschool.com
라. 논리형 타입

image from TCPschool.com
3. 자바 API 클래스
가. Arrays Class
1) Array 복사: Arrays.copyOfRange(복사할 배열, 복사시작점, 복사끝점)
•
복사끝점의 경우 자신의 위치는 포함하지 않음
ex) Arrays.copyOfRange(arry, 1, 3): arry의 1번요소부터 2번요소까지 복사
2) 오름차순 정렬: Arrays.sort(정렬할 배열)
3) 내림차순 정렬: Arrays.sort(정렬할 배열,Collections.reverseOrder());
import java.util.Arrays;
import java.util.Collections;
public class ReverseStr {
public String reverseStr(String str){
String[] arry = str.split("");
Arrays.sort(arry, Collections.reverseOrder());
StringBuffer sb = new StringBuffer();
for( String s : arry )
{
sb.append(s);
}
return sb.toString();
}
Java
복사
4) 일부 구간만 정렬: Arrays.sort(arr, 0, 4); // Index 0 ~ 4 범위에 해당하는 값에 대해 정렬
나. String vs StringBuffer vs StringBuilder
•
String 사용에 적절한 경우
→ 변하지 않는 문자열을 자주 읽고 멀티 스레드 환경일 경우
→ String은 immutabe(불변)하기 때문에 + or concat을 사용할 시, 새로운 String instance를 생성
→ 기존 instance를 Heap 영역에 임시 가비지 영역이 생성되므로 성능에 치명적인 영향을 줌
•
StringBuffer 사용에 적절한 경우
→ 문자열 추가, 수정, 삭제 등의 연산이 빈번히 발생하고 멀티 쓰레드 환경에서 사용하는 경우
→ mutable하기 때문에 기존 인스턴스에 대해 변경되더라도 추가적으로 메모리를 할당받지 않음
→ 동기화를 지원하기 때문에 멀티 쓰레드 환경에서 안정함
•
StringBuilder 사용에 적절한 경우
→ 문자열 추가, 수정, 삭제 등의 연산이 빈번히 발생하고 싱글 스레드 환경에서 사용하는 경우
→ mutable하기 때문에 기존 인스턴스에 대해 변경되더라도 추가적으로 메모리를 할당받지 않음
→ 동기화를 지원하지 않지만 싱글스레드 환경에서 StringBuffer 보다 뛰어난 성능을 보임
•
String, StringBuffer, StringBuilder 비교

다. String Class
1) String 기본 함수
가) charAt(): 매개변수로 전달된 index에 해당하는 문자(char)을 반환
나) compareTo(): 비교할 문자열을 매개변수로 전달하여 비교함. 대소문자를 구분하며 두 문자열이 같을 시 0을 반환함. 기준 문자열이 매개변수로 전달한 문자열 보다 사전 편찬 순으로 비교했을 때 작으면 음수를, 크면 양수를 반환함
다) compareToIgnoreCase(): 대수문자 구분없이 두 문자열을 비교할 때 사용하며 반환 값 및 인자는 위와 같음
라) concat(): 기준 String 뒤로 인자로 전달한 String을 추가해서 반환함
→ concat 대신 + 연산자를 활용해서 붙일 수 있음
마) indexOf(): 문자열 중 특정 문자를 인자로 전달하여 최초로 등장하는 위치의 인덱스를 반환함
바) trim(): 기준 문자열의 모든 공백을 제거함
2) 문자열 활용
가) char[] → String 변환: String.valueOf() 메소드에 매개변수로 char[]를 넣으면, String으로 변환
나) toString: 객체를 String으로 표현
다) substring
•
매개변수 1개 전달하는 메소드: string.substring(a), a index를 포함하여 나머지 문자열에 대해 반환함
•
매개변수 2개 전달하는 메소드: string.substring(a, b) 해당 String 중 a와 b 범위 사이의 문자열에 대해 반환함
라) String 요소 하나하나에 접근하여 순회하는 방법
•
(String → char[])Char 배열 접근(추천)
•
String 배열 접근(각 요소에 대해 비교 시 에러 발생... 미해결)
// 1. char[], toCharArray 활용
String testString = "1234abc";
char[] testCharArray = testString.toCharArray();
// 2. String[], split("") 활용
String testString = "1234abc";
String[] testStringArray = testString.split("");
Java
복사
마) String → Integer: Integer.parseInt(), 첫번째 매개변수로 String을 전달하면 정수로 변화된 값이 반환됨
라. StringBuffer
1) StringBuffer append(String str): 매개변수를 문자열로 변환 후, 문자열 마지막에 추가함
•
StringBuffer append(boolean b)
•
StringBuffer append(char c)
•
StringBuffer append(char[] str) 등등
2) int capacity(): 현재 인스턴스의 버퍼의 크기를 반환
3) StringBuffer delete(int start, int end): 인덱스에 해당하는 부분의 문자열을 삭제함
•
StringBuffer deleteCharAt(int index): 인덱스에 해당하는 문자를 삭제함
4) StringBuffer insert(int offset, String str): 매개변수를 문자열로 변환 후, 지정된 offset에 추가함
5) StringBuffer reverse(): 해당 문자열의 인덱스를 역순으로 재배열함
4.. Collection 프레임워크
가. Map Collection Class
1) put(): 인자로 key와 value를 전달하여 hash 내 저장
2) get(): 인자로 key를 전달하여 해당하는 value값 반환 / key가 존재하지 않는 경우 null 반환
3) remove(): 인자로 key를 전달하여 해당 데이터 삭제 및 value 반환
4) isEmpty(): boolean 값으로 해시값 비어있는지 확인
5) containsKey(): 인자로 전달한 key의 존재유무에 따라 boolean 값 반환
6) containsValue(): 인자로 전달한 value의 존재유무에 따라 boolean 값 반환
7) keySet() : HashMap에 저장된 key 값들을 Set 객체로 반환
•
set 객체는 순서가 없으면 중복된 값도 없음
8) values(): value들은 Collection 객체로 반환
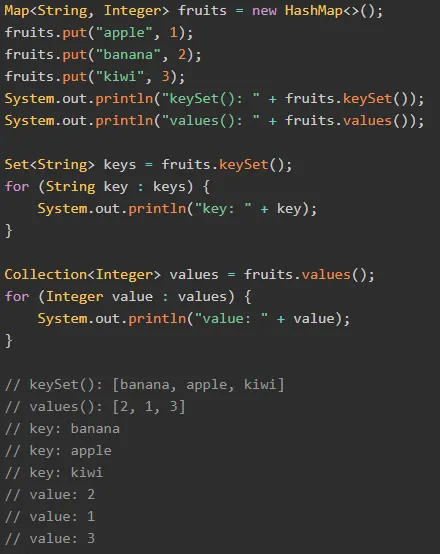
나. List Collection Class
2) ArrayList vs LinkedList
•
ArrayList
→ 배열 이용하여 요소 저장
→ 인덱스로 각 요소에 접근하므로 데이터 조회 시 성능 유리
→ 일부 요소를 이동해야 하므로 삭제 및 추가 시 성능 불리
•
LinkedList
→ 이중 연결 리스트(doubly linked list) 이용하여 요소 저장
→ 참조값만 변경하므로 삭제, 추가 시 성능 유리
→ 첫번째 노드부터 순회해야 하므로 데이터 조회 시 성능 불리
3) Vector<E>
•
ArrayList와 같은 동작 수행(List 인터페이스 상속 및 사용 메소드 동일)
•
ArrayLlist에 비해 성능이 떨어지므로 Vector 보다 ArrayList 사용 권장
→ Vector의 경우 스레드가 1개일 때도 동기화를 하기 때문임. 반면 ArrayList의 경우 자동 동기화 기능이 없고 동기화 옵션이 존재함
•
기존 코드와의 호환성을 위해 남아 있음
4) List collection의 CRUD
•
클래스에 바로 CRUD 메소드를 적용하면 cannot resolve 에러 발생
•
CRUD에 맞는 메소드 생성할 것
→ ex) public void addItems(MenuItem item){ items.add(item) };
•
Create: boolean add(E e), void add(int index, E e)
•
Read: E get(int index)
•
Update: E set(int index, E e)
•
Delete: boolean remove(Object o), boolean remove(int index)
6) 순회방식
•
Enhanced For vs while(with Iterator)
→ Enhanced For: 순회하려는 리스트의 자료가 public 일 때
List<Student> studentList = new ArrayList<>();
for (Student st : studentList) { // 생략 }
Java
복사
→ while: 순회하려는 리스트의 자료가 private일 때
private ArrayList<Rental> _rentals = new ArrayList<Rental>();
Iterator<Rental> rentals = _rentals.iterator();
while (rentals.hasNext()) { // 생략 }
Java
복사
다. Iterator & ListIterator
1) Iterator<E> 인터페이스
가) Collection, List, Set 인터페이스에서 iterator() 메소드 사용
나) boolean hasNext(), E next() 활용하여 순회
2) ListIterator<E> 인터페이스
가) List 인터페이스에서만 listIterator() 메소드 사용
나) boolean hasPrevious() 메소드 활용하여 역방향 순회 가능
5. 제어자
가. 접근 제어자
•
public: 전체 사용 가능
•
protected: 같은 클래스, 같은 패키지, 자손 클래스에서만 사용 가능
•
(default): 같은 클래스, 같은 패키지 내에서만 사용 가능
•
private: 같은 클래스 내에서만 사용 가능
나. 그 외
•
static: 인스턴스 생성과 관계 없이 클래스 기반으로 생성되는 멤버에 붙음
→ 인스턴스 멤버를 사용하지 않는 메소드의 경우 static으로 선언하면 편리성과 성능면에서 유리
class CalculateArea {
static int width = 10;
static int height = 50;
static int getArea (int a, int b) {
return a * b;
}
}
Java
복사
•
final: 변경될 수 없는 대상에 붙여서 선언함
→ final 클래스: 확장이 불가하여 자손 클래스 생성 X
→ final 메소드: overriding이 불가하여 자손 클래스에서 변경할 수 없음
→ final 변수: 상수
•
abstract: 추상화에 사용
6. 상속
가. 상속이란
기존 클래스에 기능 추가 또는 재정의하여 새로운 클래스로 정의하는 것
•
상속의 장점
→ 기존에 작성된 클래스 재활용
→ 부모 클래스에 작성된 멤버를 자식 클래스에서 중복 작성 X
→ 클래스 간 계층적 관계 구성에 따라 다형성 구현
•
자식 클래스
→ 부모 클래스의 생성자와 초기화 블록 상속 X
→ 부모 클래스에서 private or default로 설정된 멤버는 자식 클래스에서 접근 X
→ 자식 클래스에는 부모 클래스의 필드와 메소드만 상속됨
나. super와 super()
•
this vs super
→ this: 인스턴스 변수와 지역 변수의 이름이 같을 경우, this를 활용해서 인스턴스 변수에 접근
→ super: 부모클래스의 멤버와 자식클래스의 멤버의 변수명이 같을 경우 부모 클래스의 멤버에 super를 붙여서 구분
→ this와 마찬가지로 super도 인스턴스 메소드에 참조 변수로 사용되지만 클래스 메소드에는 사용 X
•
super()
→ 부모 클래스의 생성자 호출에 사용됨
→ 자식 클래스의 인스턴스에는 부모 클래스의 고유 멤버도 자동으로 포함되므로, 자식 클래스의 생성자에 부모 클래스의 생성자가 자동으로 포함됨
다. 메소드 오버라이딩
•
오버라이딩의 조건
→ 메소드의 선언부는 동일해야 함
→ 반환 타입의 경우 부모 클래스의 반환 타입으로 변환할 수 있는 타입이라면 변경 가능
→ 부모 클래스의 접근 제어자 보다 더 좁은 범위로 변경 불가능
→ 부모 클래스의 메소드 보다 더 큰 예외범위 선언 X
7. 다형성
가. 다형성이란
하나의 객체가 여러 가지 타입을 갖는 것
나. 추상 클래스
•
추상 메소드: 자식 클래스에서 반드시 오버라이딩해야하는 메소드
→ 목적: 추상 메소드가 포함된 클래스를 상속 받는 경우, 해당 메소드를 반드시 구현할 것을 강제
→ 장점: 공통 부분에 대해 상속 받는 클래스에 필요한 부분만 재정의해서 사용할 수 있음으로 생산성 향상
→ 주의사항: 선언부만 작성, 구현부 X, 구현부를 자식 클래스에서 오버라이딩해서 작성
•
추상 클래스: 하나 이상의 추상 메소드를 포함한 클래스
→ 목적: 자식 클래스에서 반드시 추상 메소드를 구현하도록 강제
→ 주의사항: 추상 클래스는 구현부가 없기 때문에 인스턴스 생성 불가
→ 특징: 추상 메소드, 생성자, 필드, 일반 메소드 포함 가능
다. 인터페이스
클래스 작성의 기본틀 제공하고, 클래스 간 중간매개 역할을 담당하는 추상 클래스의 일종
•
인터페이스 탄생 배경: 출처의 모호성 때문에 하나의 클래스는 여러 부모 클래스로부터 다중 상속 받을 수 없음. 하지만 인터페이스 지원에 따라 다중상속의 이점을 얻을 수 있음
•
특징
→ 오직 추상 메소드와 상수만 포함 가능
→ 인터페이스의 모든 필드의 제어자는 public static final
→ 인터페이스의 모든 메소드는 public abstract
interface Animal { public abstract void cry(); }
interface Pet { public abstract void play(); }
class Cat implements Animal, Pet {
public void cry() {
System.out.println("냐옹냐옹!");
}
public void play() {
System.out.println("쥐 잡기 놀이하자~!");
}
}
Java
복사
라. 내부 클래스
하나의 클래스 내부에 선언된 또 다른 클래스
•
장점
→ 내부 클래스에서 외부 클래스의 멤버에 쉽게 접근 가능
→ 연관성이 있는 클래스를 묶음으로써, 코드의 캡술화 구현
→ 외부에서 내부 코드에 접근 불가하므로 정보의 은닉성 증가
•
내부 클래스 종류
8. 제네릭
가. 제네릭이란
•
제네릭: 컴파일 시에 타입체크를 해주는 기능
•
탄생 배경
1) 다양한 타입의 객체가 존재하기 때문에 의도하지 않은 타입의 객체를 사용하여 에러 발생할 수 있음
2) 1번을 해결하기 위해 객체에 대해 타입 체크 및 타입 변환을 하는 것은 매우 번거로움
•
장점
1) 타입 안정성 보장
2) 타입을 확인하는 코드를 생략하여 코드의 간결성 향상
나. 타입 변수 선언
•
타입 변수
1) 아래 예제에서 사용되는 'T'가 타입변수
2) 타입 변수는 '임의의 참조형 타입변수'를 줄인말
3) 객체 선언부에 임의의 참조형 타입변수를 활용해서 선언하고, 객체 생성 시 실제 타입을 대입함
class Box<T> {
T item;
void setItem(T item) { this.item = item; }
T getItem() { return this.item; }
}
class Box {
String item;
void setItem(String item) { this.item = item; }
String getItem() { return this.item; }
}
Box<String> b = new Box<>(); // 타입추론 기능에 따라 new 키워드 뒤에는 타입 생략 가능
b.setItem("ABC")
Java
복사
•
다양한 타입 변수 활용
1) <T>: Type의 줄인말, 일반적으로 임의의 참조형 타입변수를 지칭
2) <E>: Element의 줄인말, Collection 객체 등 특정 객체의 요소로 사용되는 타입변수를 지칭
3) <K, V>: Key, Value의 줄인말, Map 객체체의 키 밸류 쌍의 타입변수를 지칭
•
제네릭스 용어
1) Box<T>: 제네릭 클래스, T의 box 또는 T box라고 부른다
2) T: 타입 변수 또는 타입 매개변수
3) Box: 원시 타입(raw Type)
다. 제네릭 사용의 제한
•
static 멤버에 제네릭 사용 불가
→ 타입 매개변수(T)는 일종의 인스턴스 변수로 지역적으로 사용되는 반면, static 멤버는 해당 객체 외에서도 사용되므로 제네릭을 사용할 수 없음
•
배열 생성에 제네릭 사용 불가
→ 배열 생성 시, new를 활용함으로써 컴파일 타임에 실제 타입이 입혀져야 하지만 제네릭 사용 시 그러한 동작을 할 수 없으므로 사용 불가
라. 제네릭 타입의 제한
•
extends 키워드를 사용해서 특정 타입을 상속하는 타입에 대해서만 실제 타입을 입힐 수 있도록 제한
// 타입변수로 Fruit의 자식 클래스까지 받을 수 있음
class FruitBox<T extends Fruit> {
ArrayList<T> list = ~~
}
Java
복사
•
상속 관계가 아니라 인터페이스의 타입을 사용할 경우, implements가 아니라 extends를 사용함
interface Eatable {}
class FruitBox<T extends Eatable> {
ArrayList<T> list = ~~
}
Java
복사
마. 와일드 카드
•
타입변수만 다르고 내용은 같은 메소드의 경우, 메서드 중복 정의로 인해 에러가 발생함
→ 와일드 카드를 사용하여 넓은 범위의 타입변수를 받을 수 있음
•
<? extends T>: T와 그의 자손 객체까지 허용
•
<? super T>: T와 그의 조상 객체까지 허용
•
<?>: 제한 없음
Java
복사
바. 제네릭 메소드
•
static 메소드에는 클래스의 제네릭을 사용할 수 없지만, 메소드 내부의 타입을 지정할 때는 사용할 수 있음
•
제네릭 클래스의 타입과 제네릭 메소드의 타입은 별개의 것으로 취급됨
→ 제네릭 클래스의 타입과 제네릭 메소드의 타입변수가 같더라도 별개의 타입이기 때문에 구분 가능
class FruitBox<T> {
static <T> void sort<List<T> list, ~~){ }
}
Java
복사
•
제네릭 메소드의 타입 생략
→ 아래의 예제와 같이 제네릭 메소드에 대해 타입 생략이 가능하지만, 대입된 타입을 생략할 수 없는 경우 클래스나(static일 경우) 참조변수와 타입을 붙여서 사용해야 함
static <T extends Fruit> Juice makeJuice(FruitBox<T> box) {
// == static Juice makeJuice(FruitBox<T extends Fruit> box)
return new Juice();
}
FruitBox<Fruit> fruitBox = new FruitBox<Fruit>();
FruitBox<Apple> appleBox = new FruitBox<Apple>();
Juicer.<Fruit>makeJuice(fruitBox); // Juicer.makeJuice(fruitBox);
Juicer.<Apple>makeJuice(appleBox); // Juicer.makeJuice(appleBox);
Java
복사
사. 기타
•
컴파일러의 제네릭 타입의 제거: 컴파일러는 .java 파일의 코드에 대해 제네릭 문법에 따라 형변환을 하고 .class 파일에는 제네릭 문법을 제거한다.
→ 제네릭 등장 전의 자바 코드와의 호환성 유지
9. 메소드와 생성자
가. 메소드의 개념
나. 생성자
다. this와 this()
라. 메소드 오버로딩
마. 재귀호출
바. Builder
사. SuperBuilder
•
상속 관계에서 부모 클래스의 빌더 메소드를 자식 클래스의 빌더 메소드에서 활용할 때 사용함
→ 자식 클래스와 부모 클래스에 모두 @SuperBuilder 어노테이션을 붙여야 한다
참고) 코드
10. 입력과 출력(I/O)
가. 용어 정리
•
입출력(I/O): 컴퓨터 내부에서 또는 컴퓨터 외부로 프로그램 사이의 데이터를 주고 받는 것
•
스트림: 프로그램 사이의 데이터를 입출력하는 연결통로
→ 마치 물이 단방향으로 흐르는 것과 같이 하나의 스트림도 한 방향으로만 흐름
→ 송신 스트림, 수신 스트림을 따로 생성해야 함
→ 스트림을 통해 데이터를 주고 받을 때, FIFO(선입선출) 방식을 따름
•
바이트기반 스트림: 바이트(1byte = 8bit) 기반으로 데이터를 송수신하는 연결통로
→ 바이트기반 스트림의 최상위 객체는 InputStream, OutputStream
→ 입출력 대상(파일, 메모리, 프로세스, 오디오장치 등)에 따라 최상위 객체를 상속하는 자손 객체를 선택하여 사용함
•
보조스트림: 기반 스트림의 기능을 향상시키거나 및 새로운 기능을 추가하는 스트림
→ 기반 스트림의 인스턴스를 받아서 보조 스트림 인스턴스 생성
→ 보조스트림 자체적으로 데이터를 송수신하는 기능은 없음
•
문자기반 스트림: 문자(2byte) 기반으로 데이터를 송수신하는 연결통로
→ 자바의 char 자료형은 2byte로 정의되어 있으므로 바이트기반 스트림으로 처리하기 어려움
→ 문자기반 스트림의 최상위 객체는 Reader, Writer
→ 전체적인 사용법은 바이트기반 스트림과 유사함
나. 바이트기반 스트림
•
ByteArrayInputStream, ByteArrayOutputStream: 바이트 배열(메모리) 데이터 입출력 시에 사용됨
→ 임시로 데이터를 바이트배열로 보관했다가 변환하여 다른 곳에 입출력하는데 사용됨
→ 바이트배열은 메모리에만 사용되므로 close()가 생략되어도 GC가 자동으로 닫아줌
→ 아래 예제의 while 반복문에서 1회 동작 시 1byte만 처리하므로 굉장히 비효율적
byte[] inScr = {0,1,2,3,4};
byte[] outScr = null;
ByteArrayInputStream input = new ByteArrayInputStream(inScr);
ByteArrayOutputStream output = new ByteArrayOutputStream();
int data = 0;
// read(): 더이상 읽어올 데이터가 없으면 -1 반환
// -> data에 마지막으로 들어온 값이 -1이면 반복 중단
while((data = input.read()) != -1) {
output.write(data);
}
// 스트림을 byte[]로 변환
outScr = output.toByteArray();
Java
복사
→ 아래 예제와 같이 배열을 이용하면 입출력의 성능이 향상되므로 입출력의 대상에 따라 배열 크기를 지정하여 사용
byte[] inScr = {0,1,2,3,4,5,,7,8,9};
byte[] outScr = null;
byte[] temp = new byte[4];
ByteArrayInputStream input = new ByteArrayInputStream(inScr);
ByteArrayOutputStream output = new ByteArrayOutputStream();
// available(): 스트림으로부터 읽어올 수 있는 데이터의 크기를 반환
while(input.available() > 0) {
int len = input.read(temp); // 새롭게 입력받은 데이터의 수를 반환함
output.write(temp, 0, len); // 배열 temp에서 새롭게 입력 받은 데이터의 수만큼만 stream에 할당
}
// 스트림을 byte[]로 변환
outScr = output.toByteArray();
Java
복사
•
FileInputStream, FileOutputStream: 파일을 대상으로 입출력하기 위한 스트림
→ 실무에서 많이 사용됨
다. 바이트기반 보조스트림
•
FilterInputStream, FilterOutputStream: 보조스트림의 최상위 객체
•
BufferedInputStream, BufferedOutputStream: byte[](버퍼)를 활용하여 한 번에 여러 바이트를 입출력할 수 있도록 보조
→ 스트림의 성능을 향상시키므로 대부분의 입출력에 사용됨
→ 입력 대상에 따라 한 번에 최대로 가져올 수 있는 데이터의 크기를 버퍼의 크기로 지정하여 사용 ex) 입력 대상이 파일인 경우, 4096 byte을 버퍼의 크기로 지정함
→ 아래 예제를 보면, bufferedOutputStream.close()를 호출하면 버퍼 내부의 데이터가 출력됨
→ 보조스트림의 close 내부에 기반스트림의 close가 포함되어 있으므로 기반스트림 close를 생략할 수 있음
try {
FileOutputStream fileOutputStream
= new FileOutputStream("123.txt");
// buffer의 크기를 5byte으로 지정함
BufferedOutputStream bufferedOutputStream
= new BufferedOutputStream(fileOutputStream, 5);
for(int i = '1'; i <= '9'; i++){
bufferedOutputStream.write(i);
}
bufferedOutputStream.close();
}catch (IOException e){
e.printStackTrace();
}
Java
복사
•
DataInputStream, DataOutputStream: 8가지 기본 자료형을 기반의 입출력 스트림 지원
→ 기본 자료형 값을 4byte(16진수) 기반으로 입출력 지원
•
SequenceInputStream: 여러 개의 입력스트림을 연결해서 마치 하나의 스트림으로부터 데이터를 처리하는 것과 같음
→ 큰 파일을 여러 개의 작은 파일로 나누었다가 하나의 파일로 합치는 작업 등에 사용됨
•
PrintStream: 데이터를 적절한 문자로 출력하는 스트림 지원
→ System 클래스의 static method인 out이 대표적인 예.(System.out.println 등)
→ 문자기반 스트림의 PrintWriter과 같은 기능을 갖고 있지만 PrintWriter가 더 다양한 언어의 문자를 지원하므로 PrintStream 보다 PrintWriter 사용을 권장
라. 문자기반 스트림
•
Reader, Writer: 문자기반 스트림의 최상위 객체로써 char[] 기반의 입출력 연결통로
→ 문자기반 스트림은 2byte 기반으로 데이터를 입출력함
→ 입출력의 대상이 되는 데이터에 대해 자동 인코딩 기능을 지원함
→ Reader: 특정 인코딩 → 유니코드(UTF-16) 자동 변환
→ Writer: 유니코드 → 특정 인코딩 자동 변환
•
FileReader, FileWriter: 파일 대상으로 사용되는 입출력 기반통로
→ 바이트기반의 파일 대상 스트림과 사용법은 유사함
•
PipedReader, PipedWriter: 쓰레드 간 데이터를 입출력 할 때 사용되는 연결통로
→ 스트림 생성 후 한쪽의 쓰레드에서 connect 메소드를 활용하여 입출력 스트림을 연결함
•
StringReader, StringWriter: 메모리 대상 입출력 스트림
→ char[]가 아니라 String을 기반으로 입출력을 지원함
→ 스트림 내부에서 StringBuffer가 동작하여 String을 처리함
마. 문자기반 보조스트림
•
BufferedReader, BufferedWriter: 버퍼를 도입하여 문자를 효율적으로 처리
→ 데이터를 라인 단위로 처리할 수 있음
•
InputStreamReader, OutputStreamWriter: 바이트기반의 스트림을 지정된 인코딩의 문자데이터로 변환
→ JDK 1.5부터 Scanner 등장에 따라 같은 기능을 간편하게 사용 가능
BufferedReader br = new BufferedReader(new InputStreamReader(System.in));
String userId = br.readLine();
// Scanner scanner = new Scanner(System.in));
// String userId = scanner.nextLine()
Java
복사
바. 표준입출력과
•
표준입출력: 콘솔창을 통한 데이터 입력과 콘솔창에 데이터를 출력하는 것
•
표준입출력을 위한 3가지 스트림: System.in, System.out, System.err
→ 자바 어플리케이션 실행과 동시에 관련 스트림이 자동으로 생성되기 때문에 스트림을 따로 생성할 필요가 없음
사. 직렬화(Serialization)
•
직렬화: 객체에 저장된 데이터(인스턴스 변수)를 스트림에 사용하기 위해 연속적인 데이터로 만드는 것
•
역직렬화: 직렬화에 따라 스트림으로 만들어진 데이터를 반대로 객체로 만드는 것
•
ObjectInputStream, ObjectOutputStream: 객체의 데이터를 직렬화/역직렬화
→ 인스턴스변수의 타입이 참조형인 경우(ex) 배열)에도 참조변수가 가리키는 실제 값을 직렬화/역직렬화할 수 있음
아. File
•
추후 반드시 학습할 것
11. 열거형(enums)
가. 정의
•
다음과 같이 정의
public enum Operation {
LIST, CREATE, UPDATE, REMOVE
}
Java
복사
나. Return in String
•
name() vs toString()
LIST.name(): enum으로 정의된 값을 final 형태의 문자열 타입으로 반환함. overriding이 불가능하여 확장성 면에서 떨어짐.
LIST.toString(): enum으로 정의된 값을 문자열 타입으로 반환함. overriding 가능하여 추후 반환값을 자유자재로 수정 가능하므로 확장성면에서 name() 보다 낫다
다. Check if Enum contains certain
•
문자열의 입력값을 기준으로 이넘에 해당 입력값이 존재하는 지 확인
private Operation getOperationInput(String command) {
Operation result = null;
for (Operation operation : Operation.values()) {
if (operation.toString().equalsIgnoreCase(command)) {
result = operation;
break;
}
}
return result;
}
Java
복사
13. 예외처리
가. 기초 용어 정리
•
프로그램 오류의 구분: 에러와 예외
→ 에러(Error): 심각한 오류, 발생 시 코드에 의해 수습불가
→ 예외(Exception): 덜 심각한 오류, 발생 시 코드에 의해 수습가능
•
에러의 종료: 컴파일 에러, 런타임 에러, 논리적 에러
→ 컴파일 에러: 컴파일 중에 발생하는 에러
→ 런타임 에러: 프로그램 실행 중에 발생하는 에러
→ 논리적 에러: 설계 의도와 다르게 동작하는 에러
•
예외처리: 프로그램 실행 중 발생할 수 있는 예외에 대비하여 코드를 작성하는 것
→ 예최처리 목적: 프로그램이 비정상적으로 종료되는 것을 막기 위함
나. 예외 클래스의 계층구조
•
예외 클래스의 최상위는 Exception 클래스
•
예외 클래스의 구분: Exception 클래스와 그 자손클래스(== Exception 클래스들), RuntimeException 클래스와 그 자손 클래스(== RuntimeException 클래스들)
→ Exception 클래스들: 프로그래머 실수 외적인 부분에서 발생하는 예외가 대부분
ex) FileNotFoundException, ClassNotFoundException, DataFormateExection 등
→ RuntimeException 클래스들: 프로그래머의 실수에 의해 발생하는 예외가 대부분
ex) NullPointerException, ClassCastException 등
다. 예외처리 - try-catch문
•
예외 발생 유무에 따른 try-catch문 내 코드의 실행순서
System.out.println(1);
try{
System.out.println(2);
System.out.println(0/0);
} catch (ArithmeticException e){
System.out.println(4);
e.printStackTrace();
}
System.out.println(5);
Java
복사
→ 예외 발생: try문 실행 중 예외가 발생하면, try문 내 예외가 발생하기 전까지 코드는 그대로 실행하고 catch문의 코드를 실행함
ex) 출력 결과: 1 2 4 5
→ 예외 미발생: 예외가 발생하지 않으면, try문 전체 실행하고 catch문의 코드는 건너뜀
ex) 출력 결과: 1 2 5
•
Exception 참조변수는 catch문의 모든 Excpetion 클래스들을 참조할 수 있음
→ catch문에 Exception 참조변수만 써도 됨
•
멀티 catch블럭: '|', 앞의 기호를 추가해서 여러 예외사항에 대비하여 코드를 작성할 수 있음
→ 다만, 자손관계의 예외의 경우, 부모 예외 클래스만 사용하여 처리할 수 있으므로 에러 발생함
try {
} catch (Exception | NullPointerException e) {
// 에러 발생: Exception e로 간결하게 대체 가능
}
try {
} catch (NullPointerException | ClassCastException e) {
// okay
}
Java
복사
라. 메서드에 예외 선언하기
•
메서드 선언부에 throws 키워드를 붙여서 함께 선언함
•
쉼표로 여러 개의 예외를 다룰 수 있음
public void method() throws Exception1, Exception2 {
// 내용
}
Java
복사
•
메서드에 선언하는 예외는 일반적으로 Exception 클래스들(RuntimeException 클래스들 X)임
•
메소드에 throws로 명시된 예외에 대해 개발자는 예외를 처리할 책임을 맡게 됨
마. 기타
•
finally 블럭: 예외 발생 유무와 관계없이 실행
→ 예외 발생: try → catch → finally
→ 예외 미발생: try → finally
•
try-with-resources: 사용 후 반환해야 하는 자원에 사용함
→ 주로 입출력 클래스에 사용됨
•
예외 되던지기(exception re-throwing)
•
연결된 예외(chained exception)
14. JAVA8 java.time
가. 날짜와 시간
•
Date, Calendar 객체와 java.time 패키지: Date → Calendar → java.time 패키지 순으로 제공되었고 자주 사용됨
→ 시간 관련해서 java.time 패키지를 많이 사용하지만 과거 Date, Calendar 객체를 많이 사용했고 지금도 일부 사용되기 때문에 가볍게 알아둘 필요가 있음
•
Calendar 객체 사용 예제
// getInstance 메소드는 static으로 사용
Calendar cal = Calendar.getInstance();
Java
복사
•
Date와 Calendar 간 변환: Calendar 등장에 따라 Date 관련 메소드는 대부분 Deprecated되었지만 일부는 사용됨
// Calendar -> Date
Calendar cal = Calendar.getInstance();
Date d = new Date(cal.getTimeInMillis());
// Date -> Calendar
Date d = new Date();
Calendar cal = Calendar.getInstance();
cal.setTime(d);
Java
복사
나. 형식화 클래스
•
형식화 클래스: 데이터를 정해진 패턴에 맞춘 형식으로 반환할 수 있고 역의 기능도 지원
→ 형식화 클래스는 java.text package에 포함되어 있음
•
DecimalFormat: 숫자 데이터(int, double 등)를 부동소수점, 금액 등의 특정 형식에 맞추어 문자열로 반환하며 역도 지원
// 숫자 데이터 -> 특정 형식의 문자열
double number = 123456.89
DecimalFormat df = new DecimalFormat("#.#E0");
String result = df.format(number);
// 특정 형식의 문자열 -> 숫자 데이터
Number num = df.parse("1.2E6");
Java
복사
•
SimpleDateFormat: 날짜를 원하는 형식으로 쉽게 출력할 수 있음
→ Date, Calendar를 사용하여 출력하는 것보다 간편함
→ 매개변수로 Date 객체의 인스턴스만 전달할 수 있으므로 Calendar 객체는 Date로 변환해야 함
Date today = new Date();
SimpleDateFormat df = new SimpleDateFormat("yyyy-MM-dd");
String result = df.format(today);
Java
복사
•
ChoiceFormat: 연속적이거나 불연속적인 데이터가 혼합되어 있는 경우, 특정 범위에 속한 데이터를 문자열로 반환함
•
MessageFormat: 데이터가 들어갈 전체적인 포맷을 만들어 놓은 상태에서 다수의 데이터를 입력하여 같은 포맷으로 데이터를 처리할 수 있음
String msg = "Name: {0} \nTel: {1} \nAge: {2} \nBirthDay: {3}";
Object[] arguments = {
"배만진", "02-123-1234", "27", "07-09"
};
String result = MessageFormat.format(msg, arguments);
Java
복사
다. java.time 패키지
•
java.time 패키지 특징: 본 패키지에서 사용되는 메소드에 의해 반환되는 값은 항상 새로운 값을 생성함
→ 불변성(like String)에 따라 멀티 쓰레드 환경에서 쓰레드 safe
•
핵심 클래스
→ LocalTime, LocalDate, LocalDateTime: 각각 시간, 날짜, 시간날짜 표현 객체
→ ZonedDateTime: 시간대에 따른 날짜, 시간 표현
→ Instant: 타임스탬프(time-stamp), 날짜와 시간을 하나의 정수(나노초)로 표현
→ 타임스탬프는 날짜와 시간의 차이 계산과 순서 비교에 많이 사용됨. 특히 DB에 자주 사용됨
→ Period, Duration: 각각 날짜와 날짜 사이의 간격, 시간과 시간 사이의 간격 표현
→ now(): 현재 날짜와 시간을 저장하는 객체 생성
→ of(): 매개변수로 String 형태의 값을 받아서 날짜 또는 시간 형태로 저장
→ Temporal, TemporalAmount: 인터페이스로 위의 핵심클래스가 구현체
Temporal: 날짜, 시간 저장 객체(LocalDate 등)의 인터페이스
TemporalAmount: 차이 계산 객체(Period 등)의 인터페이스
•
LocalDate, LocalTime
◦
특정 필드 값 가져오기: get(), getXXX()
◦
필드의 값 변경하기: with(), plus(), minus()
◦
날짜와 시간 비교: isAfter, isBefore, isEqual
•
Instant
→ Instant와 Date 사이 변환: Instant 객체는 Date 객체를 대체하기 위해 등장하였으며 두 객체간 변환 메소드가 추가됨
→ static Date from(Instant instant) // Instant → Date
→ Instant toInstant() // Date → Instant
•
파싱과 포맷
→ 파싱: 원하는 형식으로 출력하고 해석
→ DateTimeFormatter 활용
15. JVM 메모리 구조
가. Call Stack Area
•
메소드의 호출에 따라 실행에 필요한 만큼의 메모리를 할당받아서 저장되는 영역
•
Call Stack Area에서 각각의 메소드는 선입후출(FILO)의 순서로 실행됨
•
현재 시점에서 Call Stack 가장 위에 있는 메소드가 현재 실행 중인 메소드임
•
각 메소드는 실행완료에 따라 자신을 호출한 메소드(stack 구조에서 바로 아래 메소드)에게 반환값을 넘겨주고, 할당 받은 메모리를 반환함
•
각 메소드가 호출됨에 따라 메소드만의 메모리가 할당되고 그 메모리에는 메소드 내부에서만 사용되는 지역변수가 포함됨
나. Method Area(Static, Class Area)
•
클래스 변수(Static 메소드 포함)가 저장되는 영역
•
프로그램이 실행되면 JVM에 의해 .class에 저장된 클래스 변수가 Method Area에 할당됨
•
Method Area에 클래스 멤버가 저장되는 순서는 객체의 인스턴스 멤버의 순서 보다 빠름
•
저장 순서의 차이로 인해 클래스 멤버는 인스턴스 멤버를 내부적으로 사용할 수 없음
다. Heap Area
•
객체의 인스턴스 변수가 저장되는 영역
•
프로그램 실행 중 생성되는 객체의 인스턴스는 Heap Area에 저장됨
16. VO(Value Object)
•
배경
→ 기본 자료형(정수형, 문자 등)이나 일반적인 Class(String 등)로 특정 프로그램의 기본 단위를 만드는 것은 여러 문제를 야기할 수 있음
→ 기본 자료형으로 기본 단위를 설계할 때, 값의 제약조건이 설계의도와 일치하지 않음
ex) '나이'라는 기본 단위는 반드시 1보다 커야 한다. 하지만 기본 자료형 중에 이와 같은 제약조건을 만족하는 것은 없다. 물론 Age라는 Class로 만들어서 위와 같은 제약 조건을 삽입할 수 있다.
→ 제약조건을 삽입해서 'Age'라는 일반적인 Class로 기본 단위를 설계하면, 값 비교가 어려워지는 단점이 있다. 왜냐하면 각 Class의 인스턴스는 같은 값의 인스턴스 변수를 가지고 있더라도 그 자체는 참조변수이기 때문이다. 물론 equals를 overriding하면 같은 값의 인스턴스 변수를 가지고 있으면 값 비교가 가능하다.
→ 하지만 'Age'를 일반적인 Class의 기본 단위로 해도, 여러 이슈가 여전히 존재한다.
1) Age의 제약조건 처리는 어떻게 하는 것이 효과적인가?
2) 여러 클래스멤버(또는 properties)를 외부에서 수정한다면?
→ 이러한 이슈들에 대해 고민 끝에 나온 개념이 바로 VO(Value Object).
•
주요개념 1) Value Equality(값 동등성): 다른 Value Object와 비교 가능
→ 무분별하게 equals와 hashCode를 overridng해서 사용하는 것보다 이렇게 다른 비교 메소드를 만들 것을 권고
final class Card {
private Rank rank;
private Suit suit;
public Card(Rank rank, Suit suit) {
this.rank = rank;
this.suit = suit;
}
public boolean sameAs(Card anotherCard) {
return rank.sameAs(anotherCard.rank) &&
suit.sameAs(anotherCard.suit);
}
}
Java
복사
•
주요개념 2) Immutability(불변성): 최초 생성시점에서 주입된 값 외에 어떤 방법으로도 값이 변경될 수 없음
VO를 생성하는 방법 세 가지 by keeping principle of immutability
1) 정적 팩토리 메소드: 생성자를 private으로 설정하고 정적 팩토리 메소드 패턴 활용
final class ComplexNumber {
private float realPart;
private float complexPart;
// create a new instance via static method
public static ComplexNumber zero() {
return new ComplexNumber(0, 0);
}
// create a new instance via constructor
private ComplexNumber(float realPart, float complexPart) {
this.realPart = realPart;
this.complexPart = complexPart;
}
}
Java
복사
2) public 생성자로 인스턴스 생성
3) 현재 객체의 속성을 활용해서 새로운 인스턴스 생성
final class ComplexNumber {
private float realPart;
private float complexPart;
// create a new instance via constructor
public ComplexNumber(float realPart, float complexPart) {
this.realPart = realPart;
this.complexPart = complexPart;
}
// create a new ComplexNumber by addition
public ComplexNumber add(ComplexNumber anotherComplexNumber) {
return new ComplexNumber(
realPart + anotherComplexNumber.realPart,
complexPart + anotherComplexNumber.complexPart
);
}
// extract internal data and convert to String
public String toString() {
return String.format("%f + %f i", realPart, complexPart);
}
}
Java
복사
•
주요개념 3) Self Validation(자가 유효성 검사)
→ 유효성 검사 시 예외발생에 따라 throw처리를 할 것
→ validateValue()와 같이 내부 메소드를 사용하면 if문 없이 보다 명시적으로 제약 조건을 표현할 수 있음
→ 클래스 멤버 변수에 값 할당 후 유효성 검사 실행(방어적 복사 기법)은 Muli-Thread에 안전함
** 유효성 검사를 먼저하게 되면, 그 찰나의 순간에 다른 쓰레드가 클래스 멤버변수의 값을 변경할 가능성이 있기 때문이다.
public class Age {
private int value;
private Age(int value) {
this.value = value;
validateValue();
}
public static Age createAge(int value) {
return new Age(value);
}
private void validateValue() {
if (this.value < 1) {
throw new IllegalArgumentException("1 이상의 값만 허용합니다");
}
}
}
Java
복사
•
사용 관습
→ 메소드는 필요할 때만 생성(불필요한 메소드 생성 지양)
ex) Getter, Setter의 경우, 꼭 필요성을 느끼는 멤버변수에 대해서만 작성할 것. Getter, Setter를 남발하면 객체에 담긴 설계의도가 왜곡된 채로 타 개발자의 의해 엉둥하게 사용될 수 있음
17. 기타
가. IntelliJ 활용
1) 단축키 활용
Reference
가. 전반에 걸쳐 참고
•
남궁성, 자바의 정석 3rd Edition
나. 부분 참고
•
•
자바 세부 동작 원리, http://tcpschool.com/java/java_intro_programming
•
Map Collection, http://tech.javacafe.io/2018/12/03/HashMap/
•
List Collection, https://programmers.co.kr/learn/courses/17/lessons/805
•
Enum check, https://www.baeldung.com/java-search-enum-values