1. JPA란
가. JPA란
1) 자바 진영 ORM 기술 표준
•
ORM(Object-relational Mapping): 객체 관계 매핑
→ 핵심: OOP와 RDB의 패러다임의 불일치를 해결
→ 개발자는 객체지향 패러다임에 따라 객체 설계
→ 관계형 데이터베이스의 원리에 따라 DB 설계
→ ORM 프레임워크는 중간에서 객체와 관계형 데이터베이스를 맵핑
2) JDBC와 어플리케이션 사이에서 SQL 명령 생성
•
JPA는 JDBC API를 활용해서 SQL 명령을 RDB에 보낸다
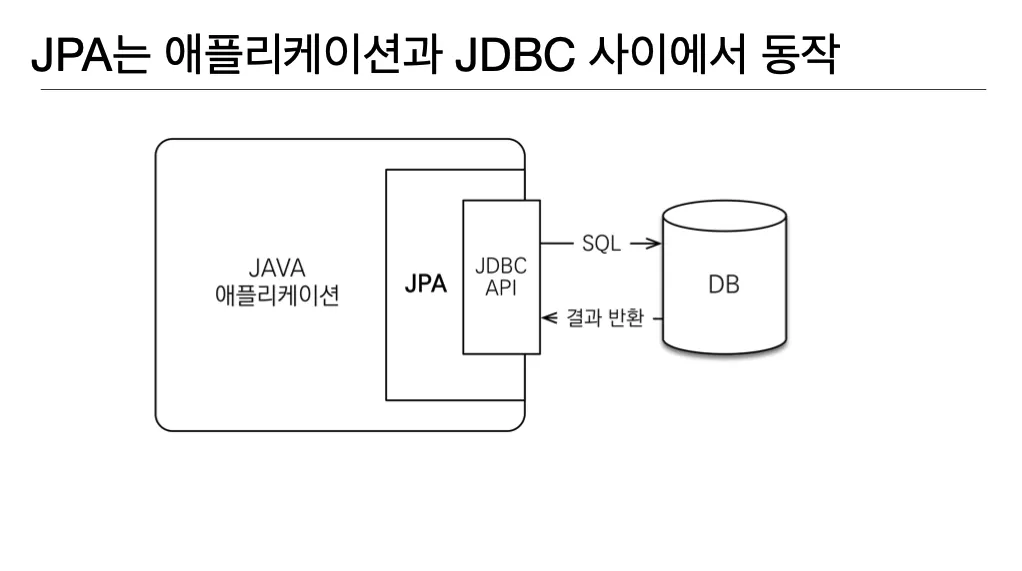
•
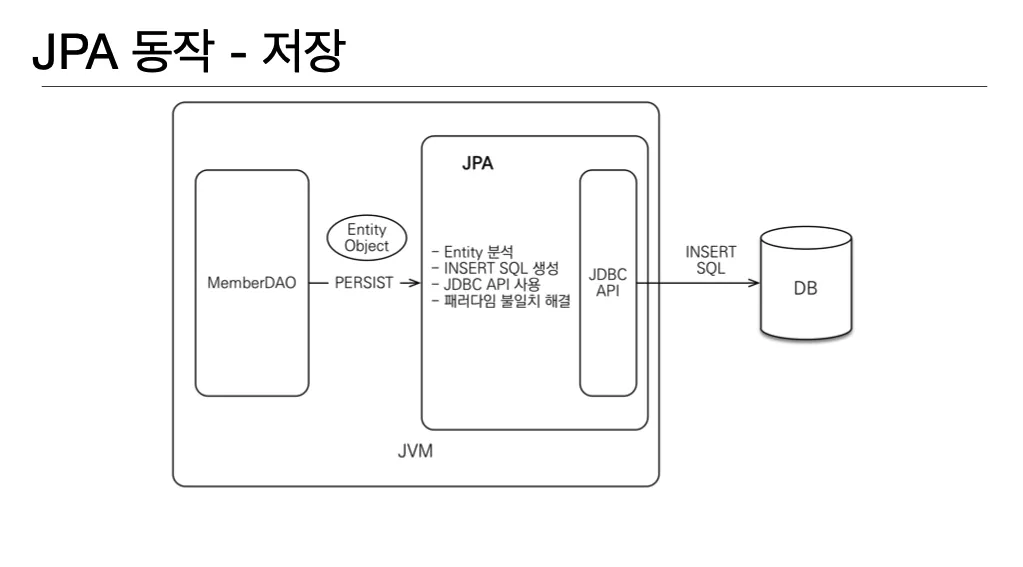
JPA는 전달 받은 Entity를 분석해서 적절한 SQL 명령을 생생한다
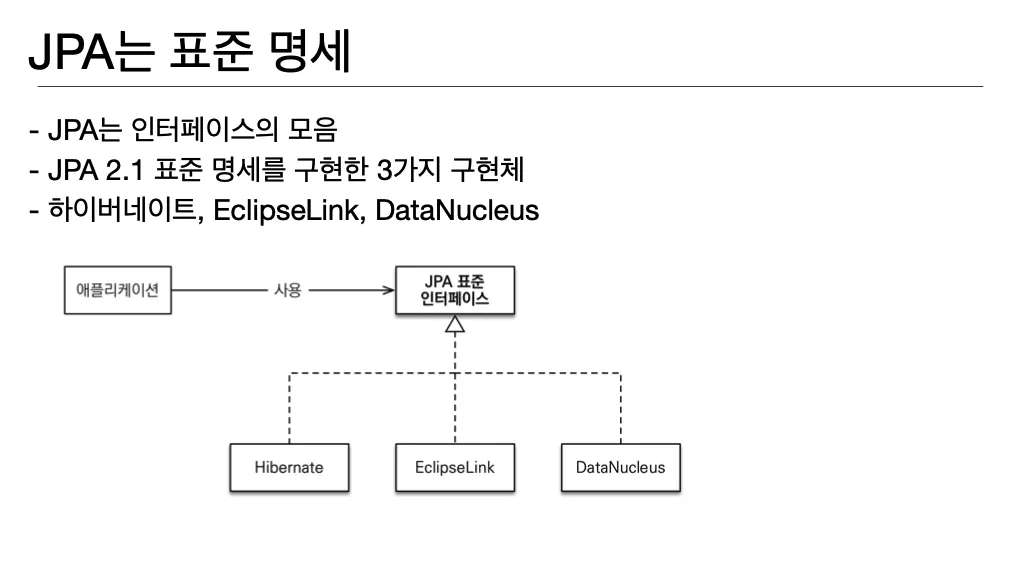
3) Hibernate를 포함한 구현체의 인터페이스
•
세 가지 구현체 중에서 대부분 하이버네이트를 사용함
4) JPA 동작 원리
•
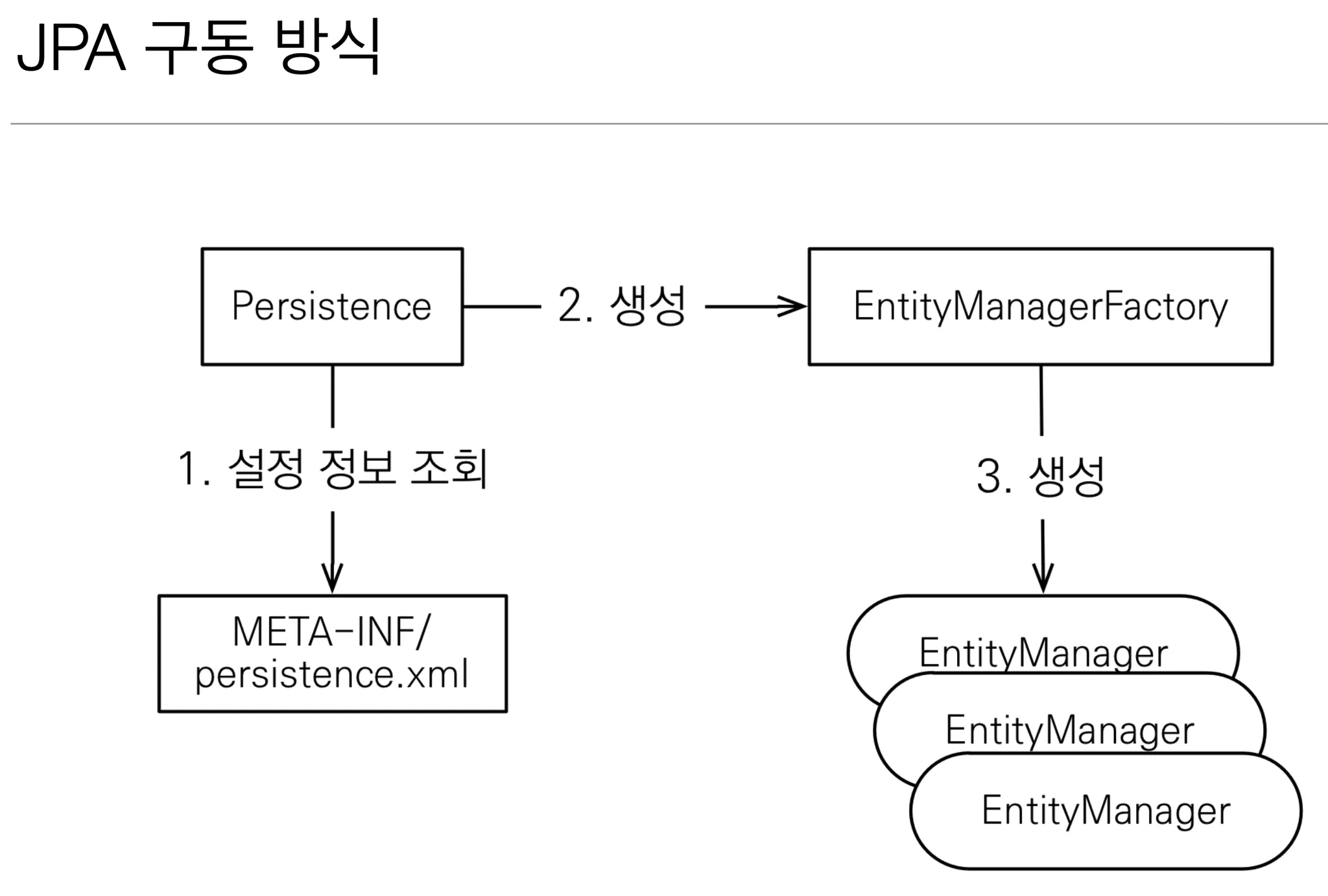
Persistence 클래스에서 persistence.xml 파일의 설정 정보를 조회함
•
설정 정보를 참고하여 EntityManagerFactory 생성
•
EntityManagerFactory에서 EntityManager 생성
•
EntityManager를 통해서 Transaction이 발생함
→ 일반적으로 하나의 Transaction이 종료되면 해당 EntityManager는 삭제됨
•
JPA의 모든 데이터 변경은 Transaction 안에서 발생
5) JPQL vs SQL
•
JPQL: 객체를 대상으로 검색하는 객체 지향 쿼리
•
비교
◦
JPQL: 엔티티 객체 대상으로 쿼리 작성
→ RDBMS마다 SQL이 다르지만 JPQL을 사용하면 설정 정보(dialect)만 바꿔주면 JPQL은 변경하지 않고 사용 가능(생산성 향상)
◦
SQL: 데이터베이스 테이블을 대상으로 쿼리 작성
나. JPA가 필요한 이유
•
SQL 중심의 개발에는 다음과 같은 문제점이 존재함
→ 대부분의 웹 개발의 DB는 관계형 데이터베이스를 사용하므로 SQL 중심의 개발이 이루어짐
→ 관계형 데이터베이스의 성능, 트랜잭션 등의 특징을 대체할 만한 DB가 없음
1) 객체 CRUD와 SQL 중복 작업 제거
•
Member라는 객체에 String phoneNumber 필드를 추가하면 관련 있는 모든 SQL 명령(Insert, Select, Update)에 대해 일일이 해당 필드를 추가하는 작업을 해야 함
•
JPA 사용에 따라 Member 객체에 phoneNumber 필드만 추가하고 다른 SQL 명령을 수정할 필요가 없음. JPA가 알아서 해당 필드를 반영한 SQL 명령을 작성함
2) 패러다임의 불일치 해소
•
객체지향 프로그래밍과 관계형 데이터베이스의 패러다임에는 큰 차이가 존재
→ 상속, 연관관계, 데이터 타입, 데이터 식별 방법 등의 차이
•
객체를 관계형 데이터베이스에 맵핑하는 것을 개발자가 일일이 작업해야 함
•
JPA를 사용하면 프레임워크가 객체와 RDB에 대해 직접 맵핑함에 따라 패러다임의 불일치로부터 고민해야하는 여러 문제를 신경쓰지 않아도 됨
•
참고) 학습 시 OOP vs RDB 어떤 것에 더 우선순위를 두어야 할까?
→ 영한님의 의견) RDB가 더 중요, 프로그래밍 트렌드가 DB 트렌드 보다 더 빠르고 쉽게 변화므로 보다 본질적인 RDB에 대한 이해에 더 우선순위를 두고 학습해야 함
다. JPA 기본 설정
•
JPA는 SQL 표준을 따르지 않는 각 RDBMS의 방언(dialect)을 배제하고 있음
•
특정 RDBMS의 방언을 JPA에 적용하기 위해 해당 RDBMS의 dialect를 아래와 같이 지정해야 함
# h2 문법을 mysql로 변경
spring.jpa.properties.hibernate.dialect=org.hibernate.dialect.MySQL5InnoDBDialect
spring.jpa.properties.hibernate.dialect.storage_engine=innodb
spring.datasource.hikari.jdbc-url=jdbc:h2:mem://localhost/~/testdb;MODE=MYSQL
JSON
복사
2. 영속성 관리 - 내부동작 방식
가. 영속성 컨텍스트
1) 영속성 컨텍스트란
•
"엔티티를 영구적으로 저장하는 환경"
•
EntityManager.persist(entity);
→ EntityManager에 해당 entitiy가 저장됨
→ 저장되는 곳은 DB가 아니라 영속성 컨텍스트에 저장됨
2) 영속성 컨텍스트의 특징
•
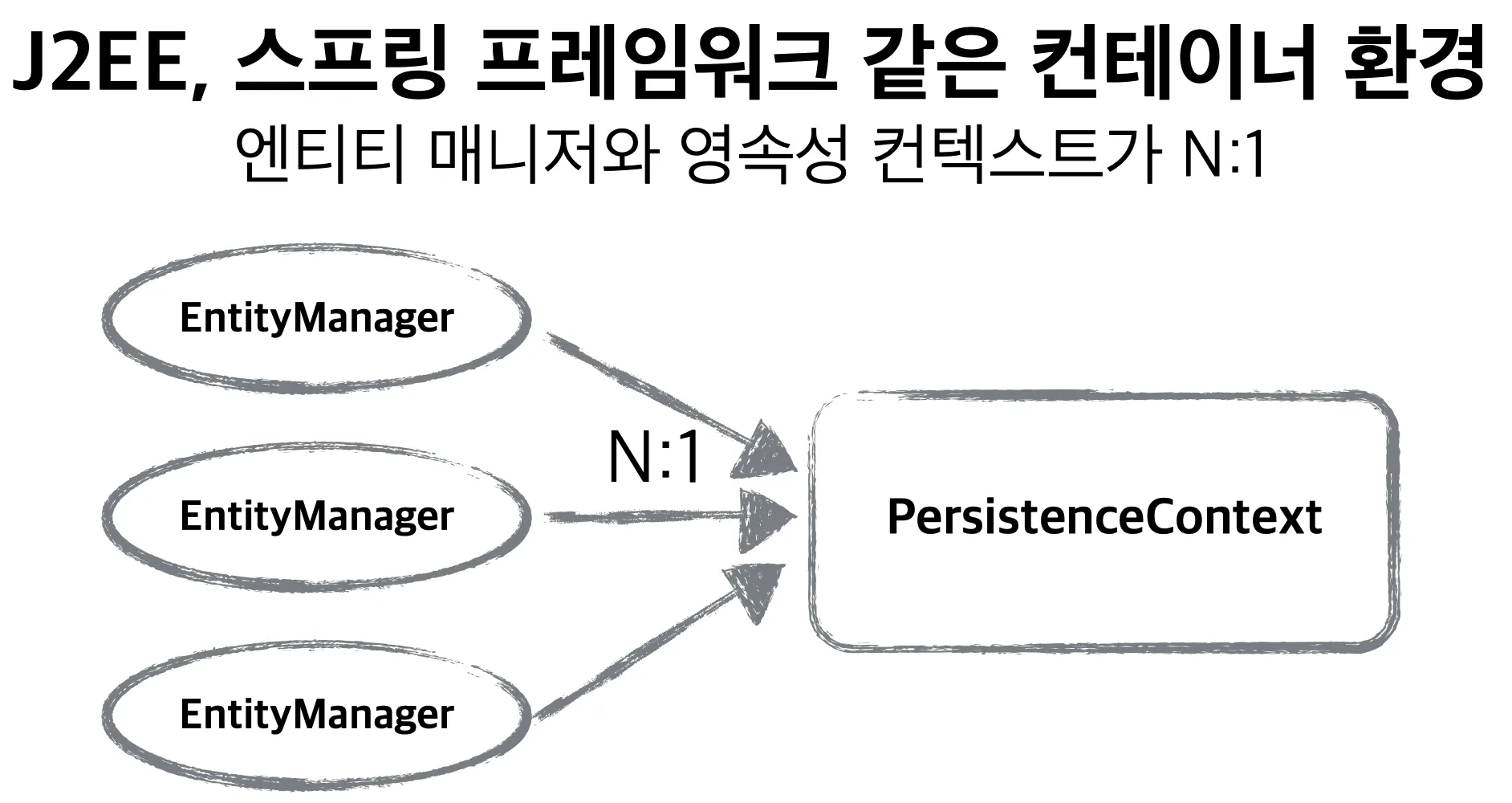
엔티티는 엔티티 매지너를 통해서 영속성 컨텍스트에 접근
•
영속성 컨텍스트는 물리적 저장공간이 아니라 논리적인 개념
•
엔티티 매니저:영속성 컨텍스트 = N:1로 맵핑됨
나. 엔티티의 생명주기
1) 비영속(new/transient)
•
영속성 컨텍스트와 관계 없는 상태, 새로운 상태
•
JPA 관련 작업을 실행하지 않고 객체만 생성한 상태
2) 영속(managed)
•
영속성 컨텍스트에 의해 관리되는 상태
•
persist 호출에 따라 엔티티가 영속상태가 됨
•
persist 호출이 없더라도 엔티티 조회에 따라 1차 캐시에 특정 엔티티가 할당되는 경우에도 영속상태가 됨
// 이하 실행 후의 상태
EntityManager.persist(entity);
Java
복사
3) 준영속(detached)
•
영속성 컨텍스트에서 분리되었지만 객체는 DB 내 존재하는 상태
// 이하 실행 후의 상태
EntityManager.persist(entity);
EntityManager.detach(entity)
Java
복사
4) 삭제(removed)
•
객체 자체가 삭제되어 DB 내에도 존재하지 않는 상태
// 이하 실행 후의 상태
EntityManager.remove(entity);
Java
복사
다. 영속성 컨테스트의 이점
1) 1차 캐시
•
엔티티가 영속 상태가 됨에 따라 1차 캐시에 저장
→ 1차 캐시: 하나의 트랜잭션 안에서의 캐쉬로 동작
→ 특정 엔티티메니저는 트랜잭션이 종료되면 삭제되기 때문에 캐시도 함께 삭제됨
•
1차 캐시에 저장된 엔티티에 대해 조회할 때, DB를 거치지 않고 캐시에서 해당 객체를 꺼낼 수 있음
•
조회 시, 캐시에 특정 객체가 없다면 해당 객체를 DB에서 조회하여 1차 캐시로 저장
•
1차 캐시라는 특징 때문에 성능 상 큰 이점은 없으나 객체지향적으로 설계할 때, 본 이점을 살릴 수 있음
→ 단, 하나의 트랜잭션이 복잡한 비지니스 로직을 다룬다면 성능 상 이점이 존재
2) 동일성(Identity) 보장
•
동일한 아이디("member1")로 조회해서 반환 받은 엔티티의 동일성이 보장됨
→ 단, 동일한 트랜잭션 안에서만 동일성이 보장됨. 같은 캐시에서 가져온 값에만 해당
EntityManager.persist(Memeber);
Member m1 = EntityManger.find(Member.class, "member1");
// 두번째 매개변수("member1")는 primary key 가리킴
Member m2 = EntityManger.find(Member.class, "member1");
System.out.println(m1 == m2); // true
Java
복사
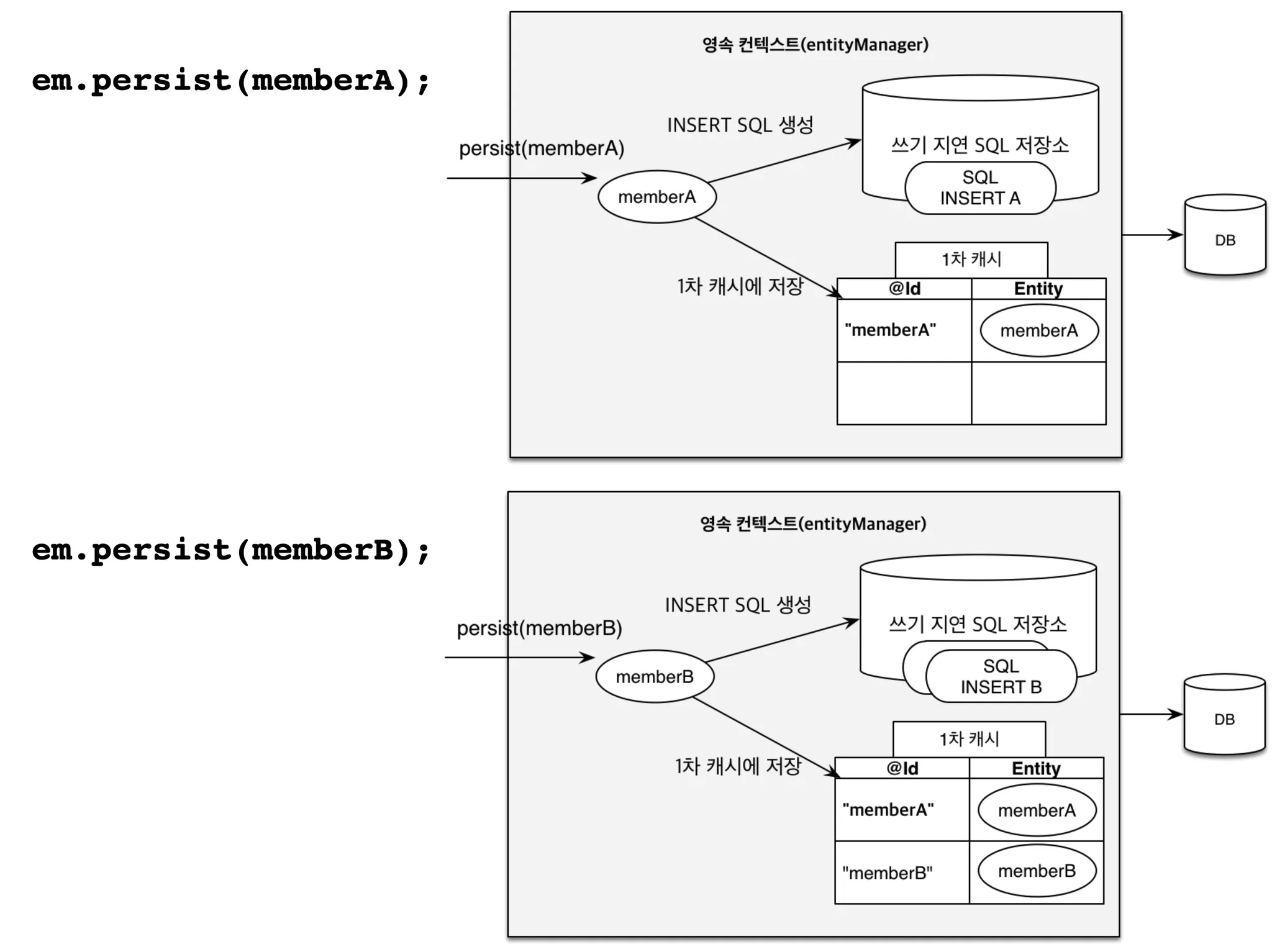
3) 트랜잭션을 지원하는 쓰기 지연
•
엔티티 등록 상의 이점
→ 트랜잭션 상에서 발생하는 SQL 쿼리를 저장하고 있다가 트랜잭션 종료 시점에 한꺼번에 실행함
→ transactional write-behind
•
영속화 단계에서 쿼리명령을 실행하지 않고, 쓰기 지연 SQL 저장소에 SQL을 저장하고 있다가 commit 되는 순간 DB로 저장한 SQL 명령을 전달함
EntityManager em = emf.createEntityManager();
EntityTransaction transaction = em.getTransaction()
transaction.begin(); // [트랜잭션] 시작
em.persist(memberA);
em.persist(memberB);
//커밋하는 순간 데이터베이스에 'INSERT SQL' 2개를 보낸다.
transaction.commit();
Java
복사
•
각 엔티티가 영속화됨에 따라 해당 엔티티는 1차 캐시에도 저장되고 관련 SQL 명령은 쓰기 지연 SQL 저장소에 저장됨
4) 변경 감지(Dirty Checking)
•
엔티티 수정 상의 이점
→ 특정 엔터티를 조회한 결과에 대해 수정 작업을 한 후, 수정된 엔티티를 추가적으로 저장하지 않아도 됨
→ 자동으로 변경된 부분을 감지하여 Update SQL 명령을 생성함
transaction.begin(); // [트랜잭션] 시작
// 영속 엔티티 조회
Member memberA = em.find(Member.class, "memberA");
// 영속 엔티티 데이터 수정
memberA.setUsername("hi");
memberA.setAge(10);
//em.update(member) 이런 코드가 불필요, 커밋하는 시점에 자동 반영됨
transaction.commit(); // [트랜잭션] 커밋
Java
복사
•
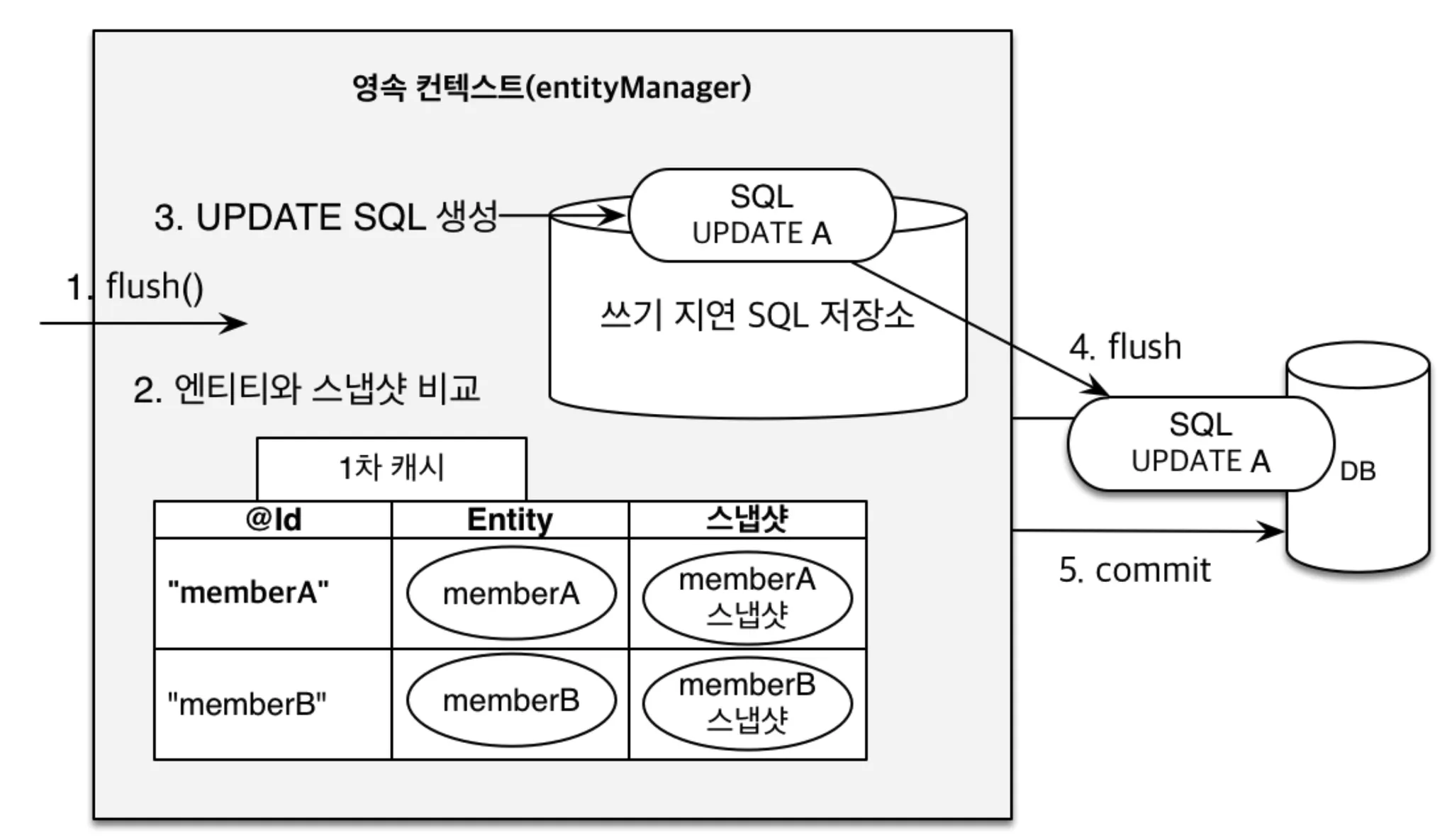
변경 감지 원리
→ 1. transaction 시작 후
→ 2. 1차 캐시에 저장된 Entity와 스냅샷으로 저장된 Entity를 비교함
→ 스냅샷은 최초로 DB에서 1차 캐시로 가져왔을 때의 Entity
→ 3. 1차 캐시와 스냅샷의 Entity가 다르다면 Update SQL 명령을 생성해서 '쓰기 지연 SQL 저장소'에 일시 저장함
→ 4. '쓰기 지연 SQL 저장소'에 저장된 SQL 명령을 DB에 전달
→ 5. transaction commit
•
JPA를 사용할 때, 변경된 엔티티를 다시 저장하는 코드 작성을 지양할 것
→ 마치 자바의 컬렉션 처럼 List의 요소를 변경한 후 다시 List에 변경한 요소를 저장하지 않는 것처럼 JPA는 동작함
→ 다시 말해, 저장하지 않아도 변경사항이 자동으로 DB에 반영됨
라. 플러시
1) 플러시(flush)란
•
영속성 컨텍스트의 변경내용을 DB에 반영하는 것
2) 플러시 호출에 따른 동작
•
Entity 변경 감지
•
Entity가 변경되었다면, 수정된 엔티티에 대한 Update SQL 쿼리를 '쓰기 지연 SQL 저장소'에 등록
•
'쓰기 지연 SQL 저장소'에 저장된 SQL 명령을 DB에 전송
3) 플러시 호출 방법
•
직접 호출: EntityManager.flush()
→ 주로 테스트할 때 사용함
•
자동 호출 1: transaction commit 발생
•
자동 호출 2: JPQL 쿼리 실행 시
→ JPQL에서 주로 Entity 조회를 하는데 쓰기 지연 SQL 저장소에 Insert 명령이 남아 있고 DB로 전달되지 않는다면 특정 Entity를 조회할 수 없음
→ 위와 같은 이유로 JPQL 쿼리 실행 시 자동으로 flush 호출됨
em.persist(memberA);
em.persist(memberB);
em.persist(memberC);
// memberA, B, C 대상으로 조회
// 이하 조회 쿼리가 동작하려면 위의 엔티티가 DB에 저장되어야 함
query = em.createQuery("select m from Member m", Member.class);List<Member> members= query.getResultList();
Java
복사
4) flush 주의할 점
•
flush 호출에 따라 영속성 컨텍스트나 1차 캐쉬를 비우는 것을 의미하지 않음
→ '쓰기 지연 SQL 저장소'를 비운다고 이해
•
'트랜잭션' 작업 단위에 따라 영속성 컨텍스트의 변경사항을 DB와 동기화
마. 준영속 상태
1) 준영속 상태
•
영속성 컨텍스트에서 특정 엔티티가 빠지는 것
•
준영속 상태가 되면 해당 엔티티에 대해 영속성 컨텍스트에서 제공하는 다양한 기능 활용이 불가함
→ 트랜잭션 커밋을 해도 해당 엔티티에는 별다른 일이 발생하지 않음
2) 준영속 상태를 만드는 방법
•
em.detach(entity): 특정 엔티티만 준영속 상태로 전환
•
em.clear(): 영속성 컨텍스트 초기화
•
em.close(): 영속성 컨텍스트 종료
3. 엔티티 매핑
가. 객체와 테이블 매핑
1) @Entity
•
@Entity가 붙으면 해당 클래스는 JPA가 관리하고 이를 엔티티라 명함
→ 해당 어노테이션이 붙지 않으면 JPA 관리 대상에서 빠짐
•
엔티티 객체는 반드시 기본 생성자를 정의해야 함
→ JPA 프레임워크에서 동적으로 엔티티 객체를 사용하기 위함. 표준
•
엔티티 객체는 final, enum, interface, inner class의 형태로 사용될 수 없음
→ abstract class or class로 사용됨
•
엔티티 객체의 필드에 final 사용할 수 없음
→ JPA가 동적으로 조작할 수 없게 됨
나. 데이터베이스 스키마 자동 생성
다. 필드와 컬럼 매핑
1) 맵핑 어노테이션 정리
•
@Column
•
@Temporal: 날짜 타입 매핑
•
@Enumerated: enum 타입 매핑
•
@Lob
•
@Transient: 특정 필드를 컬럼에 매핑 X
@Entity
public class Member {
@Id
private Long id;
// RDB의 속성명을 객체명과 달리하고 싶을 때 아래와 같이 사용
// RDB의 속성명이 "name"이 됨
@Column(name = "name")
private String username;
// 어노테이션을 달지 않았지만 자동으로 관련 타입으로 매핑됨
private Integer age;
@Enumerated(EnumType.STRING)
private RoleType roleType;
@Temporal(TemporalType.TIMESTAMP)
private Date createdDate;
@Temporal(TemporalType.TIMESTAMP)
private Date lastModifiedDate;
@Lob
private String description;
// RDB 테이블에 관련 속성 생성 X
// 특정 필드를 메모리에서만 관리하고 싶을 때 사용
@Transient
private String temp
}
Java
복사
2) @Column
라. 기본 키 매핑
4. 연관관계 매핑 기초
가. 연관관계 매핑이 필요한 이유는?
1) RDBMS 설계 → 객체지향적 설계로 변경 가능
2) 객체지향적 설계로 변경되면 이점은?
•
패러다임 일치에 따라 코드 가독성 향상
•
객체 그래프 탐색 가능
5. 값 타입
가. Entity와 VO의 사용법의 차이는?
1) 의도치 않은 부수 효과 발생 가능
2) VO의 Primitive Type과 Wrapper Class는 다르게 취급됨
•
Primitive Type은 공유와 변경 모두 불가
•
공유 가능하나 변경 불가
3) VO를 Entity와 연결 방법
•
VO에 @Embeddable으로 정의
•
VO가 사용되는 Entity에 @Embedded으로 활용
•
한 곳에 관련 어노테이션이 붙으면 다른 곳에서는 생략이 가능하나, 명시성을 위해 양쪽에 관련 어노테이션을 붙이는 것을 권장
4) Entity와 VO의 연속관계
•
Entity → VO → VO
•
Entity → VO → Entity
나. VO를 불변객체로 만들어야 하는 이유는?
1) 의도치 않은 부작용 방지
•
참조 공유에 따라 의도치 않게 발생할 수 있는 부작용을 막기 위함
2)VO를 불변객체로 만드는 방법
•
오직 생성자로 속성값을 주입
•
단, 빈 생성자를 만들어야 하기 때문에 속성값에 final은 붙일 수 없다
•
JPA에서 빈 생성자를 토대로 객체를 생성하기 때문에 진정한 의미의 불변객체로 작업은 불가
다. JPA에서 VO Collection은 어떻게 사용할 수 있는가?
1) VO Collection → RDBMS에서 1:N 관계
•
1:N 구조로 관리됨
→ Member 객체 내 List<Address> history 필드가 존재한다면, Memeber 테이블 이하에 자식 테이블로 1:N 맵핑되는 Address라는 테이블이 필요함
→ RDBMS에서 필드는 단일한 Record이므로 컬렉션에 매칭되는 표현이 존재하지 않음
•
Address는 VO를 영속화한 테이블이므로 테이블 내 자체 인공키를 만들면 안된다.
→ 자체 인공키가 있으면 Entity지 VO가 아님
→ 부모 테이블(Member)에 대한 FK 및 Address 내 주요 필드(동등성 비교에 사용되는)에 대해 모두 PK를 적용한다
2) VO Collection 정의
•
@ElementCollection, @ColletionTable, @JoinColumn 적용
3) VO Collection 활용
•
저장
•
조회
•
수정
•
삭제
Reference
•
김영한, Java ORM 표준 JPA 프로그래밍