1. ORM 도입 배경은?

객체 모델링, 구현, 유지보수 작업의 생산성 향상
가. 객체 모델링 작업의 생산성 향상
•
객체 모델링 시 패러다임의 충돌에 따른 부작용을 고려하지 않아도 됨으로 모델링 작업의 생산성이 향상된다. ORM을 도입하면 객체지향 패러다임에 따라 객체 모델링한 결과를 그대로 관계형데이터베이스에 적용할 수 있다. ORM을 도입하기 전에는 RDB에 저장할 객체의 경우 온전히 객체지향 패러다임에 따라 모델링할 수 없었다.
나. 구현 및 유지보수 작업의 생산성 향상
•
SQL 기반으로 영속적 데이터를 다루는 작업이 사라지면 새로운 기능을 구현하고 유지보수하는 작업의 생산성이 향상된다.
다. 추가 질문
•
JPA가 해결하지 못한 패러다임의 불일치의 예로 어떤 것이 있는가?
상속: 객체 지향 프로그래밍에서 상속은 핵심적인 개념입니다. 그러나 관계형 데이터베이스는 상속 개념을 직접적으로 지원하지 않습니다. JPA는 상속 관계를 테이블과 매핑하는 방법을 제공하지만, 이는 종종 복잡하고 효율성이 떨어질 수 있습니다. 예를 들어, 단일 테이블 상속, 조인된 상속, 테이블 당 구체 클래스 등 다양한 전략이 있지만, 각각의 전략은 특정 상황에서만 잘 작동합니다.
•
ORM을 도입한다면 더 이상 관계형 모델을 고려하지 않고 객체 모델링해도 부작용이 없는가?
성능 최적화: ORM은 데이터베이스와의 상호작용을 추상화하지만, 이 추상화는 때때로 비효율적인 쿼리를 생성할 수 있습니다. 객체 모델이 복잡해질수록, ORM이 생성하는 SQL 쿼리의 성능에 부정적인 영향을 미칠 수 있습니다. 따라서, 데이터베이스의 성능을 고려하여 모델링을 해야 합니다.
트랜잭션 관리와 동시성: 관계형 데이터베이스의 트랜잭션과 잠금 메커니즘은 데이터의 일관성과 동시성 제어에 중요합니다. ORM을 사용하더라도 이러한 데이터베이스의 기본 개념을 이해하고 적절히 활용해야 합니다.
2. 엔티티 매니저와 JPQL의 역할은?
패러다임 불일치를 해소하기 위한 수단으로 객체와 RDB 사이의 중간 매개체
가. 엔티티 매니저: 영속성 객체 가상 관리
•
엔티티 매니저는 영속성 객체와 RDB 사이에서 객체의 갱신과 조회 작업을 중재한다. 각각의 작업에 맞는 EntityManager의 메소드를 호출하면 이에 대응하는 SQL이 생성되어 RDB에 반영된다. 단, 수정작업에 대응되는 EntityManger의 메소드는 존재하지 않는다. EntityManger는 객체의 변경사항을 자동감지하여 UPDATE 쿼리를 생성하기 때문에 별도의 수정 메소드가 필요하지 않다.
나. JPQL: 영속성 객체 대상 조회
•
JPQL은 객체 중심으로 RDB에 질의하기 위한 매개체다. 영속성 객체 대상 조회 시 엔티티 매니저는 createQuery 메소드의 인자로 JPQL을 넘긴다. JPA는 JPQL에 기반해서 SQL을 생성한다. 단, 기본키만으로 영속성 객체 자체를 조회할 때 엔티티 매니저는 JPQL을 사용하지 않고 find 메소드를 호출하여 직접 SQL을 생성하고 이를 RDB에 반영시킨다.
다. 추가 질문
•
엔티티 매니저를 쓰레드 간 공유했을 때 발생할 수 있는 부작용에는 어떤 것이 있는가?
데이터 불일치: 한 쓰레드가 엔티티를 변경하고 다른 쓰레드가 이를 읽을 때, 변경 사항이 아직 커밋되지 않았거나 부분적으로만 반영된 상태일 수 있습니다. 이는 데이터 불일치 문제로 이어질 수 있습니다.
•
JPQL은 객체지향과 관계형 모델 간 어떤 이슈를 해결하기 위해 도입되었는가?
3. 영속성 컨텍스트에서 엔티티 CRUD의 처리 과정은?
CRUD 처리 과정의 핵심은 영속성 컨텍스트에서 발생한 중간 작업을 DB에 동기화하는 것
가. 엔티티 조회
•
JPQL 사용하여 조회할 경우, EntityManager::flush 를 자동 호출하여 영속성 컨텍스트와 DB의 동기화를 완료한다. 이후 JPQL에 대한 SQL이 생성되어 DB에 질의한다.
→ 위와 같이 flush로 동기화를 한 후에 DB에 질의하는 이유는 영속성 컨텍스트와 DB의 일관성을 지키기 위해서 입니다.
•
JPQL을 사용하지 않는 경우, EntityManger::find를 호출하여 엔티티를 조회한다. 만약 1차 캐시에 해당 엔티티가 존재한다면 DB에 질의하지 않고 1차 캐시로부터 조회 결과를 받아온다.
→ EntityManager::flush 는 호출되지 않기 때문에 영속성 컨텍스트와 DB 간 동기화 과정은 발생하지 않는다.
나. 엔티티 등록
•
EntityTransaction::commit 호출에 따라 EntityManager::flush를 자동 호출하여 영속성 컨텍스트와 DB의 동기화 과정을 거친다. 첫번째 작업은 1차 캐시에 엔티티를 저장하고 동시에 쓰기 지연 저장소에 해당 엔티티에 대한 생성 SQL을 보내는 것이다. 두번째 작업은 쓰기 지연 저장소에 쌓인 SQL을 DB에 한꺼번에 전달하는 것이다. 이후 DB commit이 발생하여 엔티티 등록 작업이 마무리된다.
→ 동기화 흐름을 이해할 때, EntityTransaction::commit과 DB commit을 명확히 구분할 필요가 있다.
다. 엔티티 수정
•
엔티티 등록 과정처럼 EntityTransaction::commit, EntityManager::flush 호출에 따라 동기화 과정이 발생한다. 동기화 과정의 첫번째 작업은 1차 캐시에 저장된 엔티티와 스냅샷 으로 저장된 엔티티를 비교하여 변경된 부분에 대한 수정 SQL을 작성해서 쓰기 지연 저장소에 보내는 것이다. 두번째 작업과 그 이후 작업은 엔티티 등록 작업과 동일하다.
라. 엔티티 삭제
•
마찬가지로 EntityTransaction::commit, EntityManager::flush 호출에 따라 동기화 과정이 발생한다. 해당 엔티티를 영속성 컨텍스트에서 제거하고 동시에 쓰기 지연 저장소에 삭제 SQL을 보낸다. 이후 과정은 엔티티 등록 및 수정 작업과 동일하다.
마. 추가 질문
•
영속성 컨텍스트란?
엔티티 매니저가 엔티티를 저장하는 환경으로, 애플리케이션과 데이터베이스 간의 데이터를 관리하는 중간 계층 역할을 합니다.
•
p104의 그림 3.11을 참고하면 flush가 두 번 보인다. 엔티티 수정 작업 흐름 중 em.flush()는 총 두 번 호출되는가?
→ 첫번째 flush의 경우 EntityManager::flush가 호출되는 것이고 두 번째 flush는 동일 메소드를 호출하는 것이 아니라 DB로 flush된다는 의미로 이해하는 것이 자연스러움
•
JPQL로 엔티티를 조회할 경우에도 1차 캐시를 참조하는가?
→ JPQL의 경우 엔티티 조회 시 DB에 직접 질의하기 때문에 조회하려는 1차 캐시를 참조하지 않습니다. 다만 DB 조회에 따른 결과가 1차 캐시에 반영됩니다
4. ‘조회 조건 로깅' 객체 모델링 방법은?
가. 요구사항
•
요구사항은 아래와 같다
1. 아래의 요청의 request parameters에 대해 로그를 쌓고 싶다
'/api/height/range?monthAfterBirth=<생후개월>&height=<cm 단위의 신장>&sex=<성별>'
2. 로그에는 반드시 로그 데이터의 생성 날짜시간에 대한 데이터가 포함되어야 한다
Plain Text
복사
나. 엔티티 설계와 맵핑
•
기본키는 GeneratedValue(default=Auto)를 사용했다. RDB로 MySQL을 사용하므로 전략은 Identity로 자동 채택된다.
•
Enum 값이 중간에 추가되더라도 큰 문제가 발생하지 않도록 EnumType은 STRING을 채택했다
•
로그의 생성 날짜시간은 @CreationTimestamp 활용하여 어플리케이션에서 생성하여 자동으로 주입된다
@Entity
@Getter
@NoArgsConstructor
public class HeightRangeRequestLog {
@Id
@GeneratedValue
private Long id;
private Integer month;
private Float height;
@Enumerated(EnumType.STRING)
private Sex sex;
@CreationTimestamp
private LocalDateTime createdAt;
}
Java
복사
다. 추가 질문
•
책에서는 스키마 자동 생성 기능에 따른 DDL의 완성독 낮기 때문에 운영 환경에 사용하는 것을 권장하지 않는다. OGQ 실무에서는 스키마 생성이 필요할 때 DDL 작업을 어떤 식으로 진행하는가? 스테이징에서 직접 DDL 작업하고 컬럼의 경우, 관련 로그가 있으므로 참고해서 작업 가능, 롤백 시나리오는 추가함. 배포 시나리오를 작성해서 작업한다.
jpa:
hibernate:
ddl-auto: none
Plain Text
복사
•
OGQ 실무에서는 기본키 생성 전략으로 어떤 방식을 채택했는가?
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
Plain Text
복사
•
IDENTITY 기본키 생성 전략 으로 생성된 엔티티 인스턴스의 경우 쓰기 지연이 발생하지 않는데, 이 부분을 보완할 수 있는 방법이 있는가?
→ 기본키 생성 전략을 바꿔 보는게 하나의 선택지다. Table 전략 선택을 고민해보자.
•
기본키 자동 생성 시 발생할 수 있는 문제와 그 해결책은?
→ 비지니스 로직이 기본키의 순차적 생성에 의존하고 있는 상황에서 롤백에 따라 일부 엔티티의 기본키가 순차적으로 생성되지 않는다면, 일부 비지니스 로직이 의도치 않은 결과를 낳을 수 있다. 이러한 경우 innodb_auto_inc_lock_mode를 설정하여, 롤백의 상황에서도 엔티티의 기본키를 순차적으로 생성할 수 있다.
5. 객체 간 연관관계를 단방향과 양방향으로 설정법은?
요구사항을 분석하여 양방햔 관계를 최소화하여 복잡성을 줄일 필요가 있음
가. 단방향 연관관계 맵핑
1) 외래키의 위치
•
외래키를 가지고 있는 객체는 외래키의 관리 주체 이상의 의미를 부여하면 안된다. 예를 들어, 비지니스 로직을 고려하여 외래키의 위치를 결정하면 안된다. 외래키의 위치를 특정 객체에 설정하는 것이 특정 객체가 다른 객체 보다 중요하다는 오해를 낳을 수 있기 때문이다. N:1, 1:N 관계에서 반드시 N에 해당하는 객체에 외래키를 설정해야 한다. 6.2.1 참고
2) 단방향 관계 맵핑
•
외래키를 가지고 있는 객체에 연관관계 어노테이션을 설정한다.
나. 양방향 연관관계 맵핑
1) 연관관계 비주인
•
연관관계 비주인은 참조를 통해 연관관계 주인을 조회할 수 있다. 연관관계 비주인은 오직 이 기능만을 갖지만 이를 위해 설정해야할 부분이 많이 늘어나므로 꼭 필요한 경우에만 양방향 관계를 설정한다. 양방향 관계에서 연관관계 주인은 단방향 관계와 다를 게 없다. 왜냐하면 양뱡향 관계는 기존 단방향 관계를 그대로 유지한채 역방향으로 새로운 관계를 추가한 것이기 때문이다.
2) 양방향 관계 맵핑
•
연관관계 비주인 객체에 @mappedBy 활용하여 주인 객체를 참조하도록 설정한다. 1:N 양방향 관계에서 연관관계 비주인(N에 해당)은 읽기만 가능하다. 관련 설정을 위해 N객체에 insertable, updatable을 모두 false로 설정해야 한다


다. 추가 질문
•
양방향 관계에서 참조 관계의 객체를 호출할 때, 무한루프에 빠질 수 있는 이유는 무엇인가? 서로를 참조하는 관계에서 동시에 서로를 참조할 때, 끝임없이 참조 작업이 진행될 수 있음 ex) Member.toString() getTeam() Team.toString() getMember()
Team.toString() getMember()•
N:1 관계에서 N에 해당하는 객체가 연관관계 주인이 되어야 하는 성능상의 이유란 무엇인가?
•
JoinColum의 기본 전략에 대한 이해가 필요함
→ 명시해서 다른 개발자에게 의도를 보여주는 것을 선호함
→ 기본전략에 대한 이해 필요 설명이 안나온 부분들 이해하는게 중요

•
연관관계 삭제 부분 중요, 관련 이슈가 생기면 디버깅이 어렵다
→ 엔티티 삭제 시 레파지토리를 활용하면 관련 이슈가 함께 해결되는가?
6. N:1, 1:1, N:N에 대한 연관관계 맵핑의 Best Practice는?
연관관계 주인의 위치에 따른 장단점을 파악하는 것이 중요
가. N:1, 1:1
•
객체 생성 시 성능과 관리면에서 N:1 관계에서 연관관계의 주인을 N에 설정하는 것이 낫다.
나. N:M
•
실무에서는 연결 엔티티에 필드를 추가하는 요구사항이 생기기 쉽다. 연관관계에 있는 객체에는 존재하지 않는 필드의 경우 연결 엔티티에 해당 필드를 생성할 수 없다. 이 경우 N:M 연관관계는 1:N과 N:1 관계로 변경되어야 한다. 분해된 관계의 연결 엔티티의 식별자는 외래키를 포함하여 기본키를 구성할 경우, 복잡성이 증가한다. 따라서 JPA를 사용하는 경우 연결 엔티티만의 새로운 기본키를 생성하는 것이 관리면에서 낫다. 새로운 기본키를 생성할 경우 연관관계의 두 객체는 비식별관계가 된다.
다. 추가 질문
•
N:1 관계에서 연관관계 주인을 1에 설정한 상태에서 객체에 대한 생성을 하면 왜 Update 쿼리가 두 번 발생하는가?
•
연결 엔티티의 식별자에 외래키의 포함여부에 따라 연관관계의 두 엔티티의 관계는 식별과 비식별 관계로 나뉜다. 어떤 의미에서 식별과 비식별인가?
•
비식별 관계로 구성할 경우 성능상 불리한 점은 없는가?
•
일대다 양방향 관계를 설정할 때, 비주인쪽을 읽기전용으로 설정해야 함 with annotation
•
6장의 일대일 관계의 즉시로딩 이슈에 대해 8장 학습 시 이야기하자
7. 상속 관계 맵핑의 Best Practice는?
옵티마이저 성능 최적화를 위해 Type Modeling 중에서 ‘조인 전략'을 선택하는 것이 최선이다
가. Super Type & Sub Type Modeling
•
상황에 따라 ‘조인 전략'과 ‘단일 테이블 전략'을 선택적으로 활용할 수 있다. 하지만 ‘단일 테이블 전략'의 경우 Nullable 필드를 다수 허용함으로써 데이터 무결성면에서 여러 부작용을 낳을 수 있다. 따라서 요구사항은 지속적으로 변하고 데이터 갱신에 따른 부작용을 최소화하기 위해 ‘조인 전략' 선택이 최적으로 보인다.
나. @MappedSuperClass
•
@MappedSuperClass 를 활용하여 정의한 객체는 테이블에 직접 맵핑되지 않는다. 하지만 이 객체를 상속할 경우, 객체 내 정의된 필드가 상속 받은 엔티티의 필드에 자동 맵핑될 수 있다. 데이터 생성일자, 수정일자 등 다수의 데이터에 일괄적으로 적용되어야할 필드를 적용할 때 유용하다.
다. 추가 질문
8. 즉시 로딩과 지연 로딩의 Best Practice는?
가. 프록시 객체
•
프록시 객체는 지연로딩 대상 객체에 대한 참조를 임시 보관하여 지연 로딩의 동작을 가능케 한다.
•
프록시 객체 초기화란 지연로딩 대상 객체가 호출되어 연관 데이터를 DB에서 가져와 실제 객체를 생성하는 것이다.
•
프록시 객체의 초기화 과정의 흐름
프록시 객체의 초기화 과정이란 프록시 객체가 참고하고 있는 실객체를 영속성 컨텍스트에 초기화(또는 생성)하는 것이다.
프록시 객체는 실객체 자체에 대한 참조값을 가지고 있다. 프록시 객체를 대상으로 엔티티의 필드에 대한 조회요청이 발생하는 시점에서 프록시 객체는 영속성 컨텍스트에 초기화를 요청한다. 영속성 컨텍스트에 대상 엔티티가 존재하지 않으면 DB에 조회하여 실제 엔티티를 생성한다. 프록시 객체 대상 엔티티 필드에 대한 조회는 결과적으로 막 생성된 실제 엔티티의 필드의 값이 엔티티 객체를 거쳐서 반환된다.
프록시 객체의 초기화가 발생하기 위해 두 가지 전제조건이 필요하다. 영속성 컨텍스트에 조회 대상 엔티티가 존재하지 않아야 한다. 그리고 지연로딩으로 대상 엔티티를 조회하도록 설정되어야 한다.
나. 지연 로딩
지연로딩 설정의 Best Practice는 대부분의 관계 또는 두 개 이상의 컬렉션을 로딩하는 관계를 대상으로 지연로딩을 설정하는 것
•
지연로딩에 적합한 연관관계는 대부분의 관계 또는 두 개 이상의 컬렉션을 로딩하는 관계다. 개발 단계에서 모든 관계를 지연로딩을 설정할 경우, N:1 또는 1:1의 경우에만 지연로딩을 설정하면 된다. 다른 관계의 경우 기본적으로 지연로딩이 설정되어 있다.
•
하나의 쿼리를 생성할 때 여러 관계가 맞물려서 두 개 이상의 컬렉션이 로딩될 경우, 지연 로딩을 사용하여 지나치게 많은 데이터가 불필요하게 로딩되는 것을 줄일 수 있다.
다. 즉시로딩
즉시로딩 설정의 Best Practice는 함께 자주 사용되는 연관관계 또는 하나의 엔티티만 로딩하는 관계(N:1, 1:1)를 대상으로 조인 방식을 내부 조인으로 수정하는 것
•
즉시로딩에 적합한 연관관계는 함께 자주 사용되는 관계다. 함께 자주 사용되는 관계를 찾기 위해 실서비스에서 사용되는 기능을 분석하여 함께 자주 사용 되는 관계를 파악하여 즉시로딩을 설정할 수 있다.
•
즉시로딩의 성능의 최적화를 위해 조인방식을 내부 조인으로 변경해야 한다. 내부 조인으로 변경하기 위해 대상 관계의 외래키에 NOT NULL 설정을 해야한다. 하이버네이트 JPA 구현체는 범용적인 사용성을 위해 조인의 기본방식을 외부 조인으로 설정했다. 단, 컬렉션을 로딩하는 관계(1:N, M:N)의 경우, NOT NULL 설정과 별개로 항상 외부 조인 방식을 채택한다. 그 이유는 N에 해당하는 데이터가 존재하지 않는다면 1 or M에 해당하는 엔티티 자체가 조회되지 않는 부작용을 제거하기 위한 것이다.
라. orphanRemoval
•
CASCADE.ALL vs orphanRemoval
: CASCADE.ALL은 부모 객체 삭제에 따라 자식 객체가 삭제된다는 것
: orphanRemoval=true는 부모 객체에서 자식 객체에 대한 참조가 제거되면, 자식 객체가 삭제되는 것(delete query 발생)
•
orphanRemoval 사용법
: Image::imageFiles의 타입을 Mutable로 정의
: Image에서 ImageFile의 참조를 갱신할 때 addAll or clear과 같은 참조 갱신 함수를 사용하여 정상적으로 참조를 제거해야 함
: Image(부모 객체)에 orphanRemoval=true 추가해야 함
•
orphanRemoval 잘못 사용한 예
: 이하의 에시 코드 같이 Image(부모 객체)의 imageFiles에 orphanRemoval=true 가 설정되어 있지 않으면 고아객체가 발생한다.
: 결과적으로 영속성 컨텍스트에서 해당 컬렉션에 대한 참조가 제거되지 않은 엔티티가 있기 때문에 고아 객체가 발생하는 것이다.
: 구체적으로 보자면, JPA의 프록시 객체는 컬렉션을 감싸는데, 컬렉션 요소 내 참조를 제거하기 위해서는 컬렉션 내부 메소드를 호출해야 한다. 안타깝게도 JPA는 가변 객체가 일반화된 자바를 기반으로 구현되었기 때문에, 컬렉션을 감싼 프록시 객체 또한 가변 컬렉션 기반으로 동작한다. 코틀린의 경우 객체는 기본적으로 불변이기 때문에 가변 객체로 정의해야 한다.
•
제대로 사용한 코드(왼쪽) vs 잘못 사용한 코드(오른쪽)
class Image(
@OneToMany(mappedBy = "image", cascade = [CascadeType.ALL], fetch = FetchType.LAZY, orphanRemoval = true)
var imageFiles: MutableList<ImageFile>? = null
)
class ImageFile(
@ManyToOne
var image: Image? = null
)
fun attach(files: List<ImageFile>) {
if (files.isEmpty()) {
return
}
files.forEach { it.image = this }
imageFiles = imageFiles ?: mutableListOf()
imageFiles!!.addAll(files)
}
private fun replace(files: List<ImageFile>) {
if (files.isEmpty()) {
return
}
imageFiles = imageFiles ?: mutableListOf()
clearFiles()
attach(files)
}
private fun clearFiles() {
if (imageFiles!!.isEmpty()) {
return
}
imageFiles!!.forEach { it.image = null }
imageFiles!!.clear()
}
Kotlin
복사
class Image(
@OneToMany(mappedBy = "image", cascade = [CascadeType.ALL], fetch = FetchType.LAZY)
var imageFiles: List<ImageFile>? = null
)
class ImageFile(
@ManyToOne
var image: Image? = null
)
fun attach(files: List<ImageFile>) {
if (files.isEmpty()) {
return
}
files.forEach { it.image = this }
imageFiles = files
}
private fun replace(files: List<ImageFile>) {
clearFiles()
attach(files)
}
private fun clearFiles() {
imageFiles!!.forEach { it.image = null }
imageFiles = listOf() // imageFiles에 대한 참조가 제거되지 않았음
}
Kotlin
복사
마. 추가 질문
•
영속성 전이(CASCADE) 사용에 따른 장점은?
장점은 연관관계 엔티티의 영속화 과정이 편리해진다. 부모 자식 엔티티를 각각 영속화했지만 부모 엔티티만 영속화하면 자식 엔티티도 자동으로 영속화되기 때문이다.
•
영속성 전이(CASCADE) 사용에 따른 부작용은?
연관관계 양방향에 영속성 전이가 설정될 경우, 한쪽에서 엔티티를 갱신할 경우 의도대로 동작하지 않을 수 있음.
•
(성우님) 하나의 기능에서 중간에 트랜잭션이 끊기면서 영속성 컨텍스트가 종료됨에 따라 엔티티가 준영속 상태로 변경됨. 이때 Lazy Loading으로 설정되었다면 영속성 컨텍스트에 관련 엔티티가 없으므로 문제 발생함. 이때 즉시 로딩으로 작업하여 해결 가능
•
(재우님) 영속성 컨텍스트에 있는 엔티티를 대상으로는 프록시 객체가 안만들어진다. 프록시 초기화가 발생하지 않는다. p300
•
(재우님) 컬렉션 객체에 대해 인덱스를 넣고 실사용을 하면, 실제 쿼리는 어떻게 작성되는가?
→ 모든 컬렉션을 가져오는가? 아니면 인덱스를 넣은 컬렉션 요소만 가져오는가?
9. 일반적인 VO와 VO Collection의 Best Practice는 무엇인가?
가. VO
•
VO를 불변객체로 정의하고 하나의 엔티티에만 완전 종속되도록 사용해야 한다. 만약 VO의 필드가 다른 엔티티에 의해 공유된다면 참조 공유에 따라 의도치 않게 필드가 갱신될 수 있다. 불변 객체를 만들기 위해 내부 값을 수정할 수 있는 메소드를 제거하고 오직 생성자로만 VO 인스턴스를 생성하도록 정의해야 한다.
나. VO Collection
•
VO Collection에서 많은 데이터를 들고 있으면 1:N 관계로 수정하는 방향을 권고한다. 성능면에서 엔티티 연관관계가 낫기 때문이다. VO Collection 대상 수정 작업 시 기존 데이터를 모두 지우고 새로 생성하는 쿼리가 발생한다. 반면 엔티티의 연관관계는 기존 데이터를 수정하는 쿼리만 발생하기 때문에 성능면에서 엔티티의 연관관계가 우월하다.
다. 추가 질문
10. 요구사항 만족하도록 JPQL과 QueryDSL을 작성법은?
가. 특정 회의 관련자 조회
•
추가설명: 특정 회의의 참석 인원과 참조 인원에 대해 조회할 수 있다
→ 입력: 회의 ID(필수) and 관련자 유형(선택)
→ 출력: 참석 인원 엔티티 컬렉션 or 참조 인원 엔티티 컬렉션
•
결과
select mm from MeetingMember mm
inner join mm.meeting m
on m.id = :meetingId
where mm.dtype = :memberType
SQL
복사
나. 특정일에 예약된 모든 회의에 대한 핵심 정보 조회
•
입력: 예약일자(필수)
•
출력: 회의 ID and 회의 제목 and 예약 날짜 and 회의 장소
•
결과: JPQL에는 일자만 자르는 기능(date in SQL)이 없다. runtime에서 전달 받은 일시 변수에서 일자만 자르고 startDateTime에는 같은 일자의 00시, endDateTime에는 동일한 일자의 23:59를 입력하는 방향으로 원하는 결과를 얻을 수 있다
select b.bookingDateTime, m from BookingInTime b
inner join b.meeting m
join fetch m.places
where b.bookingDateTime between :startDateTime and :endDateTime
SQL
복사
다. 주의사항
1) 컬렉션 값 연관 경로 탐색
•
묵시적 조인 활용하여 컬렉션 조회 시 연관필드는 묵시적 조인으로 조회할 수 없다
•
묵시적 조인에 따른 컬렉션에 대해 조인하여 별칭을 얻고, 해당 별칭을 바탕으로 묵시적 조인으로 연관필드로 조회는 가능하다
•
묵시적 조인을 자주 사용하면 하나의 쿼리에서 조인이 일어나는 상황을 한 눈에 확인하기 어렵다. 성능 개선을 위해 조인을 분석해야 하는데 조인 상황이 생략되어 있으면 분석에 어려움이 있다.
# 불가
SELECT t.members.username FROM Team t
# 가능
SELECT m.username
FROM Team t
INNER JOIN t.members m
SQL
복사
2) Fetch Join
•
연관된 엔티티와 컬렉션을 포함하여 조회할 수 있음
•
Fetch Join은 엔티티 내부에 존재하는 객체(또는 참조) 그래프를 탐색할 때 효과적
# Organization 내부의 List<Team> teams에 속한 엔티티도 모두 조회됨
select o from Organization o
join fetch o.teams
where o.name = :organizationName
# Orgainzation 내부의 teams 엔티티는 생략하고 조회됨
select o from Organization o
inner join o.teams ts
where o.name = :organizationName
SQL
복사
•
객체 그래프 탐색이 아닌 여러 객체의 조인에 따른 다양한 필드를 반환 시 Fetch Join 권장 X
→ DTO 정의하여 조회 결과를 반환 받아서 사용하는 방법 고려
•
Fetch join의 대상 객체는 on or where 절에서 필터링에 사용될 수 없다
# ms는 on절에서 필터링을 거는 시점에 DB에서 모두 조회되지 않기 때문에
# 상태필드를 대상으로 필터를 걸 수 없다
select m from Meeting m
join fetch m.members ms
on ms.dtype = :memberType
where m.id = :meetingId
# ms는 fetch join의 대상으므로 where절에서 필터링의 대상이 될 수 없다
# where절에서는 m의 상태필드만을 대상으로 필터를 걸 수 있다
select m from Meeting m
join fetch m.members ms
where ms.dtype = :memberType and m.id = :meetingId
SQL
복사
11. Spring Data JPA 공통 인터페이스가 자동으로 구현되는 흐름은?
가. 인터페이스의 구현 흐름
•
Spring Data JPA는 인터페이스의 정의를 참고하여 SimpleJpaRepository에 따라 Repository 구현체를 생성한다. 런타임 시점에 Repository 구현체 생성되어 필요한 곳에 주입된다.
나. SimpleJpaRepository 분석
(참고) SimpleJpaRepository code
다. 추가 질문
•
SimpleJpaRepository에 @Repository 가 붙게 됨으로써 JPA 예외를 스프링이 추상화한 예외로 변경된다고 한다. 이렇게 예외를 변경할 때의 이점은 무엇인가?
JPA는 DB 접근 기술로 Spring Application이 의존하지 않도록 설계하는 것이 유지보수면에서 낫다. 같은 맥락에서 JPA 예외를 스프링 예외로 추상화함으로써 추후 JPA가 아닌 다른 DB 접근기술로 변경 시 예외 관련 작업을 하지 않아도 되는 이점이 있다.
•
@Transactional(readOnly = true) 클래스 범위에서 다음과 같은 트랜잭션 어노테이션이 붙는다. 클래스 범위에서 기본값으로 readOnly = true를 지정한 의도는 무엇인가?
해당 옵션을 기본값으로 지정한 의도는 데이터 조회 메소드에 기본적으로 readOnly = true 옵션을 주기 위한 것이다. 참고로 데이터 갱신이 없고 오직 조회만 있을 경우, 위의 옵션을 기본값으로 지정하면 플러시를 사용하지 않기 때문에 약간의 성능상 이점이 있다. 데이터 갱신이 필요한 메소드의 경우 @Transactional을 붙여서 readOnly = false의 옵션을 적용한다
참고로 위의 어노테이션을 묶인 서비스 로직에 JPQL로 엔티티를 조회하는 로직이 있더라도 플러시 과정을 생략합니다. 왜냐하면 DB와의 동기화가 불필요하기 때문입니다.
•
트랙잭션이 적용된 서비스에 트랜잭션이 적용된 레파지토리가 사용되었을 경우, 영속성 컨텍스트의 생애주기는 어떤 트랜잭션을 따라가는가?
서비스의 트랜잭션을 따라간다. 서비스에 트랜잭션이 적용되지 않았다면 레파지토리의 것을 따라가지만 그렇지 않을 경우, 레파지토리의 트랜잭션은 서비스의 트랜잭션을 전파 받아서 사용한다.
12. 프리젠테이션 계층에 필요한 객체를 영속성 컨텍스트 활용하여 제공하는 Best Practice는?
스프링에서 제공하는 OSIV 활용하여 서비스 계층에서만 영속성 객체를 갱신하고, 프리젠테이션 계층에서는 영속 상태를 지속하여 지연로딩할 수 있도록 설정하는 것
가. Fetch Join vs 스프링 제공 OSIV
•
프리젠테이션 계층에 필요한 엔티티에 대해 Fetch Join을 활용하여 특정 메소드를 repository에 정의한다면 추가적으로 발생하는 요구사항에 손쉽게 대응이 가능하다. 다만 이런식으로 repository 안에 요구사항에 최적화된 메소드를 늘려가다 보면 repository와 controller 사이에 강한 의존관계가 만들어 진다.
•
스프링이 제공하는 OSIV(Open Session In View)를 활용하면 지연로딩을 활용하여 적재적소에 필요한 객체를 프리젠테이션 객체에 제공할 수 있다. 기존 OSIV와 스프링 제공 OSIV의 공통점은 프리젠테이션 계층에서 영속성 컨텍스트가 종료되지 않았기 때문에 영속성 객체를 조회할 수 있다는 것이다. 반면 차이점은 스프링 제공 OSIV의 경우 프리젠테이션 계층에서 엔티티에 대한 갱신이 불가능하다는 것이다. 이러한 차이점으로 인해 스프링 제공 OSIV를 활용해도 계층 간 역할을 침범하지 않도록 작업할 수 있다.
추가질문
•
스프링 컨테이너가 Multi Thread 환경에서 영속성 컨텍스트에서 관리하는 객체를 Thread Safe하게 관리할 수 있는 이유는 무엇인가?
스프링 컨테이너는 쓰레드 별로 트랜잭션을 할당하고, 트랜잭션 별로 서로 다른 영속성 컨테스트가 생성된다. 따라서 쓰레드 간 영속성 컨텍스트가 겹치지 않기 때문에 영속성 컨텍스트에서 관리하는 객체는 Thread Safe하게 관리된다.
•
Repository, Service, Controller의 주요 컴포넌트의 흐름에서 영속성 컨텍스트에서 관리되는 객체의 상태가 어떻게 변하는가?
영속성 컨텍스트는 트랜잭션의 시작에 따라 생성되고 트랜잭션이 종료에 따라 제거된다. 일반적으로 트랜잭션은 Service의 메소드별로 시작되고 종료됨으로, Service와 해당 Service에 의존하는 Repository에서 영속성 컨텍스트의 객체는 영속상태가 된다. 하지만 Service의 트랜잭션이 종료되고 반환되어 Controller로 전달된 객체는 준영속 상태가 된다.
•
글로벌 페치 전략에서 즉시로딩 설정 시 발생하는 N+1 이슈를 해결하기 위해 fetch join을 어떻게 활용할 수 있는가?
Team 객체와 Member 객체가 연관되어 있을 때, Team과 Member 객체를 즉시 로딩으로 조회할 때 N+1 이슈가 발생한다. 이 때 , Member 객체를 대상으로 fetch join을 설정하면 하나의 쿼리만으로 Team과 Member를 조회할 수 있다.
// JPQL
select
from Member m
join fetch m.team
// SQL
select m.*, t.*
from Member m
join Team t on m.team_id=t.id
SQL
복사
13. 엔티티 그래프 활용의 Best Practice는?
다시 읽어보자
•
엔티티 그래프 활용에 따라 root 엔티티 대상 조회에 대한 쿼리를 변경하지 않아도 된다고 한다. 이 부분이 가장 큰 장점이라고 한다. 하지만 JPQL과 Fetch Join을 활용하여 요구사항에 따라 root 엔티티 대상 조회에 대한 메소드를 추가적으로 생성하는 것과 달리 엔티티 그래프를 활용해도 결국 여러 메소드를 만든다는 점에서 이점에 대한 설명이 이해되지 않는다.
추가질문
•
글로벌 fetch 전략과 Fetch Join을 함께 사용하는 Best Practice는?
모든 엔티티 연관관계에 대해 글로벌 fetch 전략을 지연로딩으로 설정한다. 연관된 엔티티를 함께 로딩할 필요가 있는 경우에만 Fetch Join을 활용한다
14. 테스트 환경에서 엔티티를 테스트하는 Best Practice는?
테스트 환경이 하나의 영속성 컨텍스트 아래 있을 경우 동일성 비교가 적절하지만, 여러 영속성 컨텍스트가 존재한다면 동등성 비교할 것
가. Test Transactional
•
Transaction의 기본 전파 전략은 상위의 트랜잭션이 있으면 이어 받는 것이고, 없다면 새로 트랜잭션을 생성하는 것이다. 만약 테스트 메소드에 @Transactional 이 없다면 서비스 로직이 시작되기 전에 생성된 엔티티는 모두 준영속 상태에 존재한다. 하지만 테스트 메소드에 해당 어노테이션을 붙이면 하나의 영속성 컨텍스트의 범위가 테스트 전반에 걸치게 된다. 따라서 간편한 테스트를 위해 테스트 클래스 또는 테스트 메소드에 해당 어노테이션을 추가하는 것을 권장한다.
•
test_signup에 @Transactional 이 붙으면 아래의 테스트는 성공하지만, 붙지 않으면 실패한다. 해당 어노테이션이 붙지 않는다면 member와 memberFound 각기 다른 영속성 컨텍스트에서 반환된 다른 엔티티이기 때문이다. 이 과정에서 생성되는 영속성 컨텍스트에 대해 자세히 보자면, MemberService::join의 시작과 끝에 하나의 영속성 컨텍스트가 생성되고, memberRepository::findOne의 시작과 끝에 또 다른 영속성 컨텍스트가 생성된다.
@Test
@Transactional
public void test_signup(){
Member member = new Member("kim");
Long idSaved = memberService.join(member);
Member memberFound = memberRepository.findOne(idSaved);
assertTrue(member == memberFound);
}
Java
복사
나. 추가 질문
15. 성능 최적화를 위한 Best Practice는?
가. N+1 이슈 해결
1) N+1 이슈란
•
연관관계가 설정된 엔티티(부모 엔티티)를 조회할 때, 연관관계의 엔티티(자식 엔티티)를 조회하는 쿼리가 추가적으로 N개 발생하는 이슈이다.
•
연관관계가 즉시 로딩으로 설정된 경우, 대상 엔티티를 조회하는 시점에 N+1개의 쿼리가 생성된다.
•
반면 지연 로딩으로 설정된 경우, 대상 엔티티를 조회하는 시점에는 1개의 쿼리만 생성되지만 대상 엔티티에서 자식 엔티티에 대한 속성에 접근하면 N개의 쿼리가 생성된다.
•
결과적으로 즉시 로딩, 지연 로딩 설정과 관계 없이 N+1 이슈가 발생한다.
2) 대응 방법1: Fetch Join 활용
•
부모 엔티티 조회 시 ‘join fetch’ 구문을 활용하여 JPQL을 작성하면 1개의 쿼리만 발생한다. 내부 조인(inner join) 기반의 DB 쿼리가 생성되기 때문에 1개의 쿼리만으로 연관관계의 엔티티를 모두 조회할 수 있다.
// join fetch 예시
@Query("select p from Parent p join fetch p.child")
List<Parent> findAll();
Kotlin
복사
3) 대응 방법2: BatchSize 활용
•
부모 엔티티를 조회하는 쿼리 1개와 자식 엔티티 조회 쿼리 1개만 발생한다. 자식 엔티티를 조회할 때, 부모 엔티티와의 외래키를 기반으로 IN절을 활용하여 조회한다. BatchSize는 설정 파일에서 글로벌하게 설정할 수 있고, 연관 객체에 어노테이션으로 직접 지정할 수도 있다.
•
BatchSize를 활용하면 아래와 같은 DB 쿼리가 발생한다.
select id, name from team
select c.parent_id, c.child_id, u.id, u.first_name, u.last_name, u.parent_id
from parent_childs c
inner join user u on c.child_id = u.id
where c.parent_id in (?, ?, ?, ?)
SQL
복사
•
BatchSize 설정 방법
spring:
jpa:
properties:
hibernate:
default_batch_fetch_size: 100
YAML
복사
// 또는 아래와 같이 레파지토리에 직접 설정
@BatchSize(size = 100)
List<Parent> findAll();
Kotlin
복사
나. 읽기 전용 쿼리 성능 최적화
•
읽기 전용 트랜잭션과 읽기 전용 엔티티를 함께 활용한다. 하나의 트랜잭션에 엔티티 갱신 작업이 없다면, 읽기 전용 트랜잭션을 사용하여 플러시를 호출하지 않음에 따라 스냅샷 비교와 같은 로직을 생략하여 성능을 높일 수 있다. 더불어 읽기 전용 엔티티를 사용하면 Dirty Checking에 사용되는 스냅샷을 보관하지 않으므로 메모리도 절약할 수 있다.
다. 기본키 생성 전략 최적화
•
아래와 같이 비지니스 키와 프라이머리 키를 분리하여 설정하면 다음과 같은 장점이 있습니다. 요구사항에 따라 변경 가능성을 고려할 때 소프트웨어의 확장성을 높일 수 있습니다. 특히 프라이머리 키의 변경은 DB에서 매우 높은 비용을 요구합니다. Disk의 물리적인 위치 변경이 필요한 작업입니다.
•
GenerationType.TABLE 을 설정하면 프라이머리 키를 기준으로 조회와 삽입의 성능이 향상됩니다. 엔티티 벌크 생성 시에도 성능 상 이점이 있습니다. 한 번에 다량의 엔티티 생성 시 쓰기 지연 저장소에 생성 쿼리를 모았다가 한 번에 DB에 쿼리를 전달할 수 있습니다. 만약 Identity 전략이라면 쓰기 지연 저장소를 활용할 수 없고, 쿼리 하나하나를 DB로 전달해야 합니다.
•
yaml 설정에서 fetch_size를 설정하면 메모리에 기본키를 해당 사이즈 만큼 저장하고 필요에 따라 할당하기 때문에 성능면에서 이점이 있습니다.
@Entity
class PointAccount(
@Embedded
@AttributeOverride(name = "id", column = Column(name = "account_id", unique = true, length = 40))
val accountId: AccountId,
) {
@Id
@TableGenerator(name = "PointAccountIdGenerator", table = "sequence", allocationSize = 100)
@GeneratedValue(strategy = GenerationType.TABLE, generator = "PointAccountIdGenerator")
private var id: Long? = null
}
interface PointAccountRepository {
fun find(memberId: MemberId): PointAccount?
}
Kotlin
복사
jpa:
properties:
hibernate:
default_batch_fetch_size: 100
YAML
복사
라. 외래키 사용 자제
"외래키는 부모테이블이나 자식 테이블에 데이터가 있는지 체크하는 작업이 필요하므로 잠금이 여러 테이블로 전파되고, 그로인해 데드락이 발생할 수 있다. 그래서 실무에서는 잘 사용하지 않는다.” - RealMySQL
마. 추가 질문
•
global fetch 전략을 지연로딩으로 설정한 환경에서 N+1 이슈가 발생할 수 있는 경우는?
•
기본키 생성전략을 IDENTIY로 지정하면 벌크성 배치 작업과 같은 곳에서 쓰기 지연에 따른 성능 최적화라는 장점을 얻을 수 없다. 그 이유는?
•
JPA를 잘 활용하면 어플리케이션 단계에서 DB에 걸리는 락의 시간을 최소화할 수 있다. 락의 시간이 최소화되는 원리에 대해 설명할 수 있는가?
16. JPA 트랜잭션에 대한 Best Practice는?
영속성 컨텍스트를 활용하여 Transaction Level을 REFEATABLE READ까지 유지하고, 더 높은 Transaction Level이 필요한 로직에는 OPTIMISTIC LOCK을 사용하는 방향 권장
가. JPA Transactional 동작 방식
1) 트랜잭션 일반
•
트랜잭션이란 일련의 SQL 쿼리를 하나의 작업 단위로 묶어서 실행하는 것입니다.
•
하나의 트랜잭션은 ACID의 특성에 따라 의도치 않은 동작으로부터 데이터의 정합성을 지켜줍니다. 예를 들어, 하나의 트랜잭션으로 묶인 SQL 쿼리 중 하나가 실패하면 트랜잭션 내 모든 쿼리에 대한 연산을 롤백합니다. 또한 동시적으로 여러 트랜잭션이 발생하여 동일한 컬럼에 대해 수정을 할 때에도 트랙잰션별로 순차적으로 해당 컬럼에 접근하여 값을 변경시키도록 제어합니다. MySQL의 경우, 커밋된 트랜잭션은 리두로그에 저장되어 있다가 시스템 장애 발생 후 재시작 시, 리두로그 내 트랜잭션 히스토리에 따라 결과적으로 DB 내 데이터의 정합성을 검증합니다.
2) JPA Transactional 동작 방식
•
이하의 메소드에 Transactional 어노테이션을 사용한다는 것은 해당 메소드에서 발생하는 DB 연산을 하나의 트랜잭션으로 묶는다는 것입니다.
•
다른 말로, Transactional 어노테이션을 사용하지 않는다는 것은 repository 메소드별로 각각의 트랜잭션이 발생한다는 뜻입니다. 만약 그렇게 된다면 데이터 정합성 문제가 발생하고 성능면에서 단점이 두드러집니다.
•
트랜잭션이 분리됨에 따라 이하의 메소드에서 예외 발생가 발생하면 의도치 않게 동작합니다. pointAccount.deductPoints에서 예외가 발생할 경우, 그 위의 동작은 수행되어 DB에 반영될 것입니다.
•
이하의 메소드에서 총 세 개의 DB 트랜잭션이 발생하여 DB 접근에 따른 비용이 증가합니다. 비용이란 빈번한 DB 접근 그 자체와 빈번한 DB 잠금 발생에 따른 전체적인 성능 하락을 의미합니다.
@Transactional
fun usePoint(memberId: String, amount: Int) {
val pointAccount = repository.find(MemberId(memberId)) ?: throw MemberNotFoundException(MemberId(memberId))
val useTrans = transFactory.createUseTrans(accountId = pointAccount.accountId, amount = amount)
transRepository.save(useTrans)
pointAccount.deductPoints(useTrans.points)
}
Kotlin
복사
나. REFEATABLE READ by JPA
1) JPA와 REFEATABLE READ
•
JPA의 Default Transaction Level이 READ COMMITED로 설정되었어도, JPA의 영속성 컨텍스트 활용에 따라 Transaction Level이 REFEATABLE READ까지 향상될 수 있다.
2) 영속성 컨텍스트와 1차 캐시 메커니즘
•
영속성 컨텍스트는 엔티티의 1차 캐시 역할을 합니다. 한 트랜잭션 내에서 동일한 엔티티를 여러 번 조회할 경우, 첫 번째 조회 이후의 조회들은 데이터베이스가 아닌 1차 캐시에서 엔티티를 가져옵니다. 이는 MySQL이 언두로그를 활용하여 본 트랜잭션 이후의 변경사항을 무시하는 것과 같은 역할을 합니다.
•
영속성 컨텍스트는 엔티티의 변경 사항을 추적합니다. 트랜잭션이 커밋되기 전까지 변경된 엔티티는 데이터베이스에 반영되지 않습니다. 이로 인해 같은 트랜잭션 내에서는 변경 전의 데이터를 계속 조회할 수 있으며, 이것은 REPEATABLE READ에서 기대할 수 있는 동작입니다.
3) 하이버네이트 기본 격리수준
하이버네이트(Hibernate)의 경우, 기본적으로 데이터베이스에서 설정된 기본 트랜잭션 격리 수준을 따릅니다. 하이버네이트 자체는 특정한 기본 격리 수준을 강제하거나 정의하지 않습니다. 대신, 하이버네이트는 사용 중인 데이터베이스의 기본 설정을 사용하거나, 애플리케이션 또는 설정 파일을 통해 명시적으로 격리 수준을 지정할 수 있습니다.
예를 들어, MySQL을 사용할 경우, 하이버네이트는 MySQL의 기본 격리 수준인 REPEATABLE READ를 사용하게 됩니다. PostgreSQL을 사용할 경우에는 PostgreSQL의 기본 격리 수준인 READ COMMITTED를 사용하게 됩니다.
다. 낙관적 락
서비스의 전체적인 성능을 향상시키기 위해 DB 차원의 락보다는 어플리케이션에서의 락을 권장. WAS 서버는 수평 확장에 용이하지만 DB 서버는 그렇지 못함
1) 낙관적락의 동작 방식
•
값에 변경이 발생한 경우, 엔티티에 생성한 version 필드 값을 올린다. 만약 한 트랜잭션 안에서 특정 엔티티를 두 번째 조회할 때, 버전이 달라졌다면 트랜잭션이 실패한다. 최악의 경우 트랜잭션의 실패여부를 마지막에 버전의 일치여부를 통해 확인 가능하다는 점이 단점이다. 트랜잭션 중간에 외부 시그템과 연동할 경우, 트랜잭션은 실패했지만 외부 시스템 API를 정상적으로 호출하는 결과를 야기할 수 있다.
2) 낙관적락 설정
•
낙관적락 설정은 아래와 같이 엔티티에 버전을 추가하고, 관련 Repository에 Lock을 걸 때 옵션을 OPTIMISTIC을 넣어주면 된다.
•
엔티티에 Version 어노테이션이 달린 필드가 있다면, repository method 위에 @Lock(value = LockModeType.OPTIMISTIC) 을 생략해도 JPA가 알아서 낙관적 락을 건다. 생략이 가능하지만 Lock을 그대로 두면 낙관적 락으로 동작한다는 것을 명시적으로 전달할 수 있다.
•
단, 이미 부모 엔티티에서 version이 필드로 정의되어 있고 대부분의 엔티티에서 상속 받아 구현했다면 Lock 어노테이션을 생략하는 것이 낫다. 왜냐하면 대부분의 엔티티가 이미 낙관적 락으로 동작한다는 것을 대부분이 인지한 상태에서 추가적인 명시성은 불필요하기 때문이다.
public class Item {
// 기타 필드 생략
@Version
private int version;
}
Java
복사
public interface ItemRepository extends JpaRepository<Item, Long> {
@Lock(value = LockModeType.OPTIMISTIC)
@Query("select i from Item i where i.id = :id")
Item findByIdForUpdate(@Param("id") Long id);
}
Java
복사
H2 기반 SQL Console Log
3) 낙관적락이 수평확장 유리한 이유
•
비관적락은 DB의 연관 레코드를 잠가버립니다. 특히 select for update는 next key lock의 형태로 잠금을 걸어버리기 때문에 해당 레코드와 주변 레코드에도 잠김이 걸려서 연관 작업이 모두 대기가 걸립니다.
•
하지만 낙관적락을 걸면 나중에 갱신된 데이터와 연관된 트랜잭션이 롤백하는 것을 감안하더라도 동시에 여러 작업이 실행될 수 있습니다.
라. 비관적 락
1) 비관적락의 동작방식
•
DB에서 지원하는 공유락 또는 베타락으로 레코드에 잠금을 걸고 다른 트랜잭션에 의해 해당 레코드가 갱신되지 않도록 막는다. 특정 레코드를 최초 조회하는 트랜잭션 외에 다른 트랜잭션에서 해당 레코드를 변경할 수 없다. 외부 시스템이 트랜잭션 중간에 호출되어도 부작용이 발생하지 않는다.
2) 공유락
•
공유락은 다른 트랙잭션에서 읽기는 허용하지만 쓰기는 허용하지 않는 것이다. PESSIMISTIC_READ 옵션
@Lock(value = LockModeType.PESSIMISTIC_READ)
@Query("select i from Item i where i.id = :id")
Item findByIdForUpdate(@Param("id") Long id);
Java
복사
H2 기반 SQL Console Log
3) 배타락
•
배타락은 다른 트랜잭션에서 읽기도 쓰기도 허용하지 않는 것이다. PESSIMISTIC_WRITE 옵션
@Lock(value = LockModeType.PESSIMISTIC_WRITE)
@Query("select i from Item i where i.id = :id")
Item findByIdForUpdate(@Param("id") Long id);
Java
복사
H2 기반 SQL Console Log
4) 비관적락이 수평 확장에 불리한 이유
추가 질문
•
REFEATABLE READ의 문제점에 해당하는 PHANTOM READ에 대해 설명할 수 있는가?
•
낙관적 락과 비관적 락의 차이는?
•
2차 캐시 활용에 있어 주의사항은?
Redis vs 2차 캐시? 기능 상 큰 차이 없음. 다만 여러 서버를 올릴 경우, redis 하나에서 캐싱되지만 2차 캐시는 서버 각각에서 캐싱해야함. 이로 인한 관리 포인트가 추가됨. 예를 들어, DB에서 캐시 메모리로 로딩되는 시간이나 로딩되는 데이터 등을 일치시키는 작업이 번거로움. 성능 상 큰 차이가 나지 않기 때문에 백그에서는 Redis 공통 캐싱을 활용함
17. 자체 맵핑 시나리오(회의실 예약 시스템)
가. 요구사항 분석
1) 요구사항
OGQ 회의실 예약 시스템
유저 기능
회원 정보 조회(그룹/팀 및 본인이 참여한 회의 내용) 조회 가능
그룹/팀에 속한 유저 조회 가능
소속 기능
여러 그룹(OGQ , 닥프렌즈)이 존재
하나의 그룹에는 팀(모바일본부 , 마서본 , 네오마..)이 존재.
하나의 팀에 팀원(재우 , 성우 , 만진)이 존재.
예약 기능
여러 회의실을 예약 할 수 있다.
예약시 회의내용을 비공개 / 공개 설정가능
참석인원 1명 이상이어야 한다
참조인원 0명 이상이어야 한다
예약시 회의 제목 , 내용 , 결론 저장 할 수 있다.
예약단위는 하루이다 , 그러나 추후 1시간이 될수도 30분이 될수도 있다.
예약 취소 가능하다.
공통 요구사항
등록일과 수정일은 항시 포함되야한다.
회의실은 여러개(큰회 , 작회)가 존재 할 수있다.
여러 회의실을 예약 한번으로 예약 할 수 있다.
회의실 예약비는 0원이다, 추후에 금액부과 가능
Plain Text
복사
2) UML
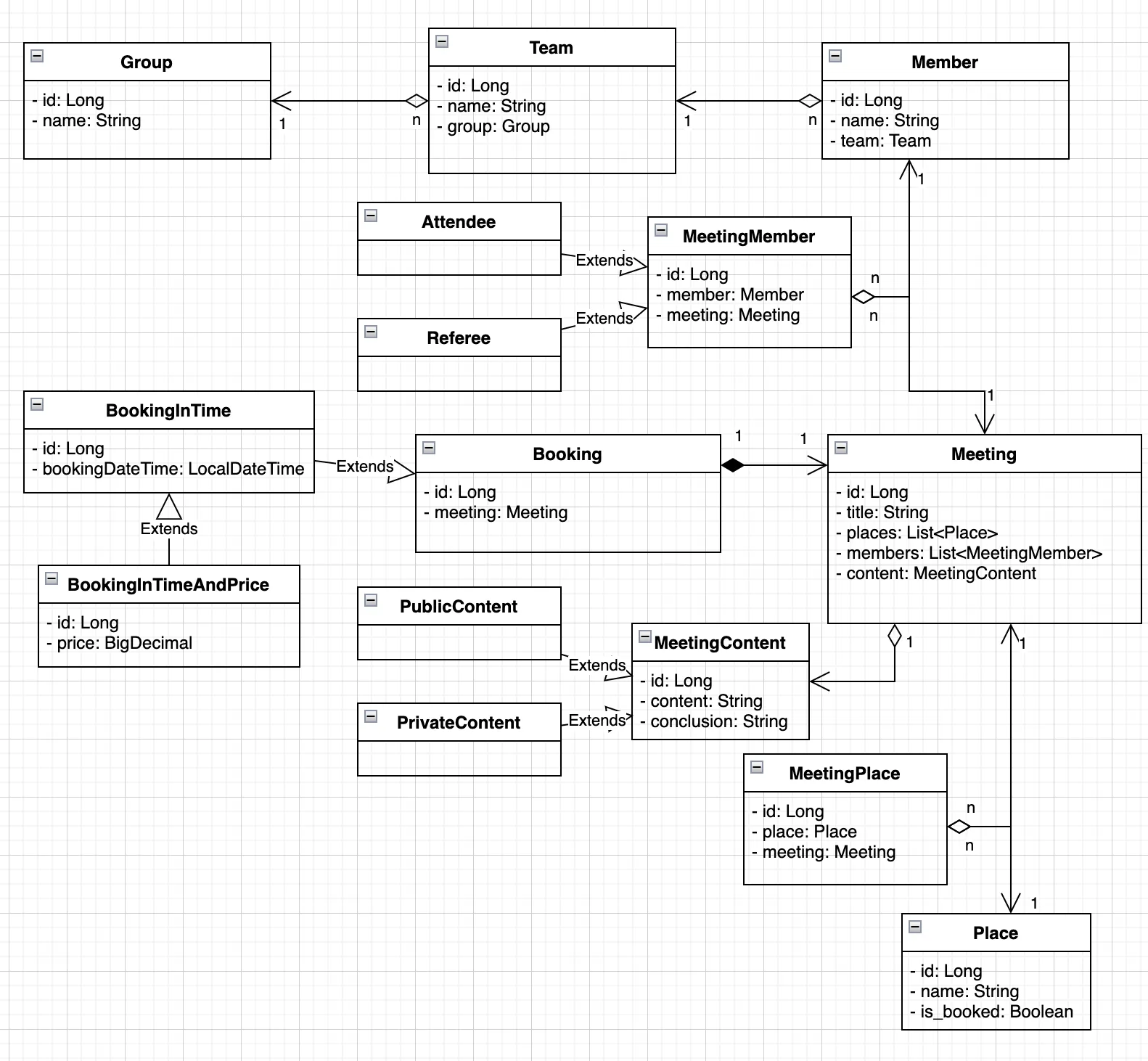
3) DDL
Base Entity
Member and else
Meeting and else
Booking and else
4) Entity Mapping
5) Feedback
•
(재우) @MappedSuperclass 활용하여 시간 관련 필드를 맵핑하는 것 권장
•
(재우) 요구사항에 딱 맞게 설계하다가 추가적인 요구사항이 발생할 때 전체적인 설계를 뒤집을 수도 있다. 설계할 때 확장성을 고려해서 유연하게 만들 것 권장
•
(성우) Boolean으로 처리된 부분을 제거하고 해당 엔티티를 상속 받아서 재정의하는 것 권장
•
(성우) @embedded 활용해서 Custom Type을 적용해서 Entity를 간결하게 만들어 볼 것을 권장
18. JPA know-hows
가. 대량의 데이터 처리
나. Transactional
다. DB 컬럼 추가 대응
라. equals, hashcode의 중요성
Reference
•
김영한, 자바 ORM 표준 JPA 프로그래밍
•
JPA 예외 → 스프링 추상화 예외 변경 이점, https://devbksheen.tistory.com/entry/JPA-예외-처리
•
Entity Graph 활용
◦
어노테이션 활용: https://kihwan95.tistory.com/13
•
낙관적 락과 비관적락의 쓰임, http://jaynewho.com/post/44