1. SQL과 관계형 모델
가. 관계형 모델 이해의 중요성
1) 성능
•
설계 의도를 벗어난 조작은 성능문제로 이어질 가능성이 높음
→ RDBMS는 관계형 모델의 설계 위에서 동작하는 응용프로그램임
2) 문제 해결
•
설계에 숨겨진 내부 동작 원리를 이해하지 못하면 문제의 원인을 찾아내기 힘듬
→ 기술은 사용성을 높이기 위해 내부동작 원리가 표면으로 드러나지 않음
나. 관계형 모델 개괄
1) 데이터 모델 vs 데이터 모델링
•
데이터 모델: 특정 개념을 사용해 데이터를 표현하는 방법론
→ 관계형 모델은 '관계'라는 개념으로 데이터를 표현하는 방법론
→ KVS(Key-Value Store): 키와 이에 대응하는 값으로 데이터를 표현하는 방법론
•
데이터 모델링: 데이터 설계
→ 관계형 모델의 경우 ERD와 같은 모델링 툴을 이용하여 데이터를 설계함
2) 기본 개념
•
관계형 모델: 현실 세계의 데이터를 '릴레이션(관계)'이라는 개념으로 표현한 데이터 모델
•
릴레이션(관계): 관계형 모델에서의 연산 단위
→ SQL에서 릴레이션에 해당하는 것은 테이블이다
→ 테이블 간의 관계는 릴레이션이 아니다
•
릴레이션의 구성: 제목(Heading), 본체(Body)
•
제목(Heading): 속성(Attribute)이 n개 모인 집합
→ 속성은 이름과 데이터형으로 구성됨
•
본체(Body): 속성 요소(tuple)의 집합
→ 속성요소(tuple)는 속성(Attribute)의 이름과 데이터형의 범주에 들어가는 값이어야 함
제목: 국가번호/정수, 국가명/문자열, 지역/문자열
본체: 81/한국/아시아, 29/미국/북아메리카, 44/케냐/아프리카, ...
Plain Text
복사
3) 집합과 릴레이션
•
릴레이션은 집합의 한 종류이므로 집합의 특성은 릴레이션에도 적용됨
•
집합 특성 1: 집합의 요소에는 불확정성을 허용하지 않음
→ 집합 내 요소는 특정 집합에 포함되거나 포함되지 않음
→ RDB 적용: NULL을 허용하는 것은 집합의 특성에 맞지 않음
→ 7장 참고
•
집합 특성 2: 집합의 요소는 중복되지 않음
→ 집합과 집합 내 요소는 포함 또는 미포함의 관계
→ 집합이라는 개념에서 요소의 개수는 의미를 갖지 않음
→ RDB 적용: 테이블에 중복되는 행을 방치하는 것은 집합의 특성에 맞지 않음
•
집합 특성 3: 집합의 요소 각각은 더는 분해될 수 없는 값
→ 집합 S에 요소 a가 포함된다고 할 때, 요소 a의 일부를 이루는 값은 a와 다르기 때문에 a가 집합 S에 포함된다는 판정에 아무런 영향을 주지 못함
→ RDB 적용: ??
다. 릴레이션과 SQL 기본 조작 간 관계
1) 릴레이션 기본 연산
관계형 모델은 릴레이션 단위로 다양한 연산을 사용해 질의를 수행하기 때문에 '관계형 모델'이라고 부른다
•
예시 릴레이션
제목: 국가번호/정수, 국가명/문자열, 지역/문자열
본체: 81/한국/아시아, 29/미국/북아메리카, 44/케냐/아프리카, 90/일본/아시아
Plain Text
복사
•
제한(Restrict): 특정 조건에 맞는 튜플을 포함한 릴레이션 반환
→ ex) 조건(지역이 '아시아')에 맞는 릴레이션 반환
제목: 국가번호/정수, 국가명/문자열, 지역/문자열
본체: 81/한국/아시아, 90/일본/아시아
Plain Text
복사
•
프로젝션(Projection): 특정 속성만 포함하는 릴레이션 반환
ex) 속성 중 '지역/문자열'만 포함하는 릴레이션 반환
반환 릴레이션에 중복이 발생한 값(아시아)에서 단일 값만을 반환한다
→ 집합에서 중복을 허용하지 않음
제목: 지역/문자열
본체: 아시아, 북아메리카, 아프리카
Plain Text
복사
•
확장(Extend): 새로운 속성을 추가하여 릴레이션 반환
→ 대부분의 경우 기존 속성 값을 사용하여 새로운 속성 계산하는 형태
ex) 속성 중 인구와 면적을 사용하여 '인구밀도'라는 새로운 속성 추가
제목: 국가명/문자열, 인구/정수, 면적/실수
to
제목: 국가명/문자열, 인구밀도/실수, 인구/정수, 면적/실수
Plain Text
복사
•
합집합(Union): 두 개의 릴레이션에 포함된 모든 튜플로 구성된 릴레이션(합집합) 반환
→ 튜플 중복 제거 후 반환
•
교집합(Intersect): 두 개의 릴레이션에 모두 포함된(중복된) 튜플로 구성된 릴레이션 반환
•
차집합(Difference): 두 개의 릴레이션 중 한쪽에만 포함된 튜플로 구성된 릴레이션 반환
•
곱집합(Product): 두 개의 릴레이션에 있는 튜플을 각각 조합한 릴레이션 반환
•
결합(Join): 공통된 속성을 가진 두 개의 릴레이션에서 해당 속성이 같은 튜플끼리 조합한 릴레이션 반환
→ 결합 연산은 RDB의 내부 결합(INNER JOIN)에 해당하며 RDB의 외부결합의 경우 릴레이션에 NULL이 포함되므로 관계형 모델에서는 존재하지 않는 연산임
ex) 릴레이션 A와 릴레이션 B의 JOIN 결과 반환
# 릴레이션 A
제목: 국가번호/정수, 국가명/문자열, 지역/문자열
본체: 81/한국/아시아, 29/미국/북아메리카, 44/케냐/아프리카, 90/일본/아시아
# 릴레이션 B
제목: 국가번호/정수, 인구/정수
본체: 81/5, 90/12
# JOIN 결과
제목: 국가번호/정수, 국가명/문자열, 지역/문자열, 인구/정수
본체: 81/한국/아시아/5, 90/일본/아시아/12
Plain Text
복사
2) Relation Variable
•
도메인: 특정 변수에 대입할 수 있는 값의 유한집합
→ 변수란 도메인(유한집합)의 요소 중 하나를 선택한 것
•
관계변수(Relvar): 관계형 모델의 변수
→ 관계형 모델에서 릴레이션을 값으로 보기 때문에 Relvar에 릴레이션 대입 가능
•
RDB에서 테이블이 Relation이자 Relvar의 역할을 동시 수행
3) SQL과 릴레이션 조작
•
SELECT: 기본적으로 Product, Restrict, Projection 연산 수행
→ SELECT에 대한 릴레이션 연산의 논리적인 순서는 아래와 같다
1. 테이블 목록: 곱집합(Product)
2. 검색 조건: 제한(Restrict)
3. 칼럼 목록: 프로젝션(Projection)
Plain Text
복사
→ 연산 순서는 RDBMS의 옵티마이저의 실행계획에 따라 바뀔 수 있음
•
INSERT: R : = R U { T }
→ R은 테이블 t의 Relvar, T는 새롭게 추가되는 행의 튜플
→ RDB의 갱신을 관계형 모델에서 표현하면 릴레이션 자체에 대한 갱신이 아니라 Relvar에서 추가될 행의 튜플에 대한 합집합 연산 결과를 Relvar에 대입하는 것으로 표현 가능
# 관계형 모델 해석: Relvar(R)에 대해 새롭게 추가할 튜플의 집합(T)과의 합집합 연산
INSERT INTO t(c1, c2, c3) VALUES (1, 2, 3);
Plain Text
복사
→ 릴레이션은 값이기 때문에 갱신이 불가능하고 대신 변수에 대입되는 값이 변경되는 것
→ RDB의 테이블에 갱신이 되는 것은 테이블이 릴레이션이면서 동시에 Relvar이기 때문
•
DELETE: R : = R - { T }
→ RDB의 삭제를 관계형 모델에서 표현하면 Relvar에서 제거될 행의 튜플에 대한 차집합 연산 결과를 Relvar에 대입하는 것으로 표현 가능
# 관계형 모델 해석
# 1. Relvar(R)에서 제한 연산(WHERE 조건)에 따라 튜플의 집합(T) 반환
# 2. Relvar(R)에 대해 튜플의 집합(T)과의 차집합 연산 후 결과값을 Relvar(R)에 대입
DELETE FROM t WHERE c1 =100
Plain Text
복사
•
UPDATE: R : = ( R - { T1 } ) U { T2 }
# 관계형 모델 해석
# 1. Relvar(R)에서 제한 연산(WHERE 조건)에 따라 튜플의 집합(T1) 반환
# 2. T1에 대해 수정을 가한 T2 반환
# 3. Relvar에서 T1에 대한 차집합 연산
-> 집합(R)에서 T1과의 차집합 연산이 선행돼야 수정된 튜플집합(T2)이 결과적으로 Relvar에 반영 가능
# 4. 위의 연산 결과와 수정된 튜플집합(T2)와의 합집합 연산 결과를 Relvar에 대입
UPDATE t SET c1 =1 WHERE c2 = 123;
Plain Text
복사
라. 관계형 모델과 SQL의 차이

관계형 모델의 개념을 벗어나지 않는 방향으로 SQL 조작 권장
1) 요소 중복
•
집합에는 요소의 중복을 허락하지 않지만 테이블에는 행의 중복이 가능함
•
유일성 제약을 사용해 테이블 내 행의 중복을 제거해야 함
2) 요소 간 순서
•
집합에는 요소 간 순서 개념이 존재하지 않지만 테이블에는 열과 행에 순서 개념이 존재함
•
행이나 컬럼의 위치를 변수로 설정한 쿼리를 작성하면 안됨
ex) ORDER BY 1, ROWNUM 등 사용 지양
3) 트랜잭션
•
관계형 모델에는 트랜잭션 개념이 없지만 RDB에는 존재함
→ 트랜잭션 이론은 관계형 모델과 함께 RDB의 주요한 이론임
•
트랜잭션은 관계형 모델과 다른 이론적 배경이 있음
→ 14장 참고
4) 스토어드 프로시저
•
테이블을 루프로 처리하는 것은 집합 연산과 정면 충돌
5) NULL
•
NULL은 집합에 포함되지 않는 개념이므로 사용 지양
→ 7장 참고
2. 술어논리와 관계형 모델
3. SQL과 관계형 모델
4. 정규화 이론
가. 개요
1) 정규화의 이점
•
데이터 중복 방지에 따른 데이터 사이의 모순 제거
2) 키의 종류
•
슈퍼키: 릴레이션의 각 튜플을 고유하게 구별할 수 있는 속성의 집합
•
후보키: 튜플을 고유하게 구별하기 위한 속성의 최소 집합
→ 슈퍼키의 일종으로 속성의 집합에서 튜플을 고유하게 구별하는데 있어 불필요한 속성을 제거한 속성의 집합
•
기본키: RDBMS에서 후보키 중에서 하나를 선택하는 것
→ 기본키는 여러 개의 후보키 중에서 하나를 주관적으로 선택하는 것이므로 관계형 모델에서 기본키라는 개념은 다루지 않음
•
대리키(or 인공키): 튜플을 식별하기 위해 정수값의 속성을 임의로 추가하여 만든 키
3) 제 1 정규형
RDBMS의 ‘테이블’이 관계형 모델의 ‘릴레이션’의 조건을 만족할 것
•
릴레이션 조건
◦
칼럼이나 행의 순서 존재 X
◦
중복되는 행 제거: 후보키에 의해 행의 모든 값은 구분될 것
◦
NULL 미포함: 하나의 행에는 열에 대응되는 값이 반드시 존재할 것
◦
값의 원자성: 하나의 행에는 열의 값이 될 수 있는 값들의 집합 중 하나만 들어갈 것
나. 함수 종속성
1) 함수 종속성이란
•
함수 종속성이란 특성 속성값에 의해 다른 속성값이 구분되는 특성
x → y
•
자명한 함수종속성: 후보키에 의해 후보키가 아닌 속성값이 구분되는 것
•
자명하지 않은 함수종속성: 후보키의 일부 또는 후보키가 아닌 속성에 의해 일부 속성값이 구분되는 것
•
자명하지 않은 함수종속성의 폐해: 중복값의 전체가 아닌 일부 갱신에 따른 값의 모순 발생 가능
→ 자명하지 않은 함수종속성은 필연적으로 값의 중복을 야기함
→ 값의 중복에 따라 값을 갱신할 때, 중복되어 있는 모든 값을 동시에 변경해야 함
→ 전체적인 구조가 복잡할 때, 중복된 값의 전체가 아닌 일부만 갱신되어 값의 모순이 발생할 수 있음
2) 제 2 정규형
•
부분함수 종속성 제거
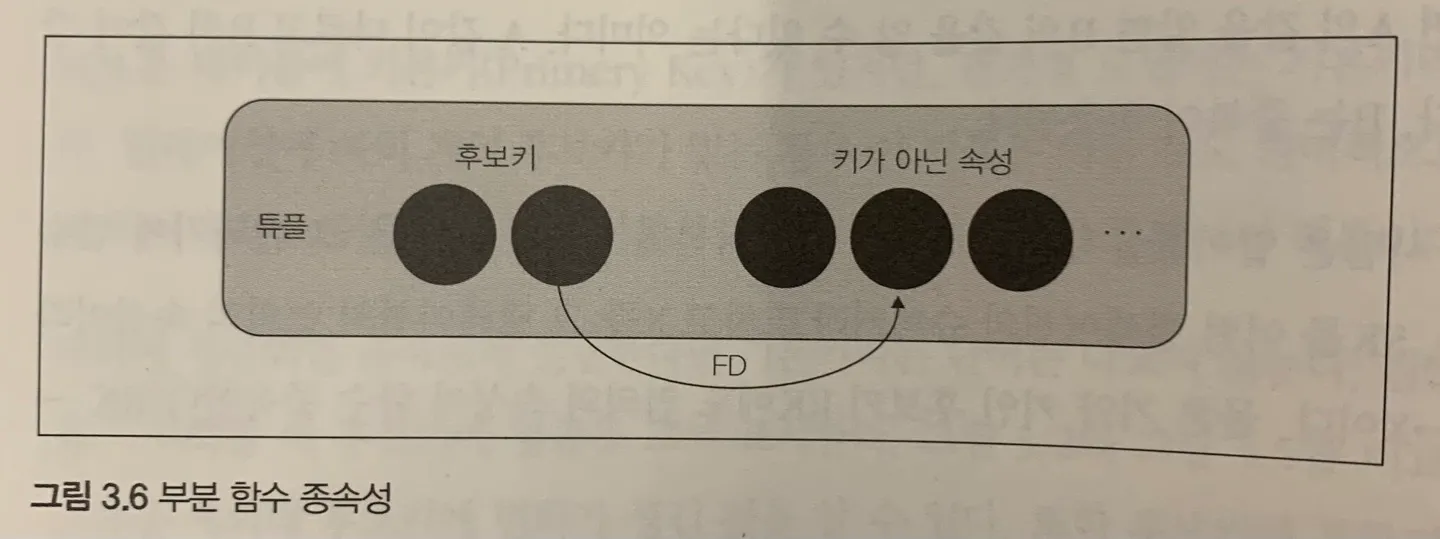
image from 오쿠노 미키야, 관계형 데이터베이스 실전 입문
3) 제 3 정규형
•
추이함수 종속성 제거
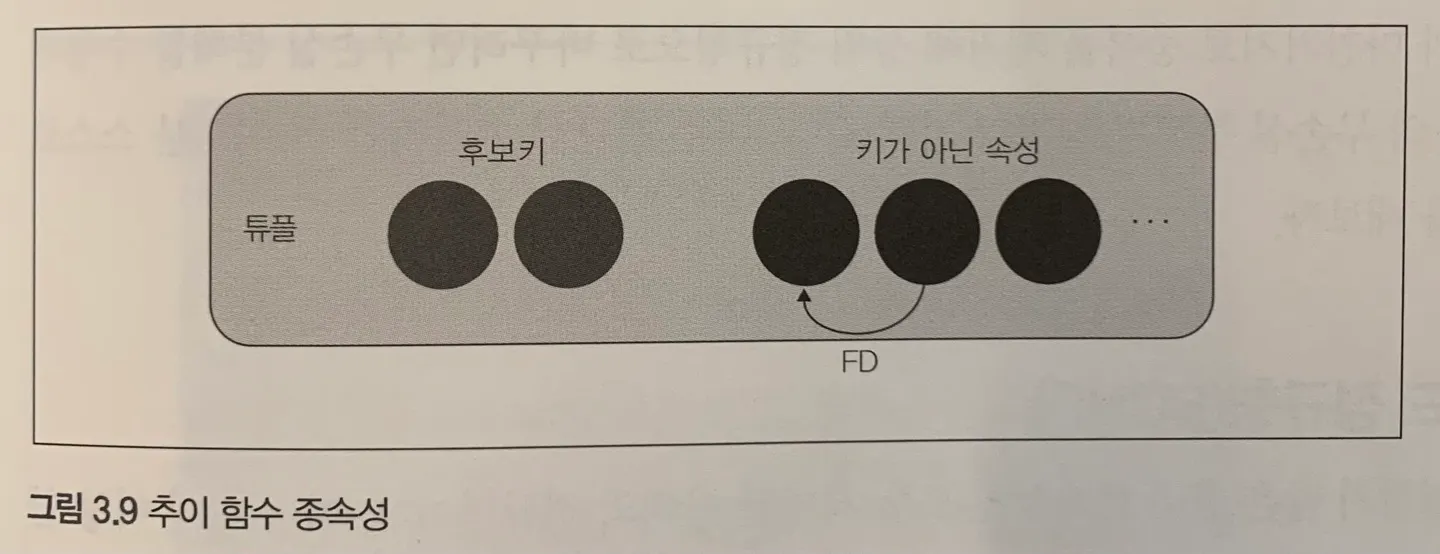
image from 오쿠노 미키야, 관계형 데이터베이스 실전 입문
이하의 비정규화된 테이블에서는 '부서ID'가 '부서 이름'과 '부서 위치'를 결정합니다. '직원ID'는 '부서ID'에 직접적으로 종속되며, 간접적으로 '부서 이름'과 '부서 위치'에 종속됩니다. 이러한 간접적 종속성이 추이 함수 종속성입니다.
정규화된 테이블에서는 이러한 추이 함수 종속성을 제거합니다. '직원 테이블'과 '부서 테이블'을 분리하여 각 테이블이 자신의 주요 키에만 직접적으로 종속되도록 설계했습니다. 이렇게 하면 데이터 중복을 줄이고, 데이터 무결성을 향상시킬 수 있습니다.
비정규화된 테이블 예시 (추이 함수 종속성이 존재):
직원ID | 직원 이름 | 부서ID | 부서 이름 | 부서 위치 |
1 | 홍길동 | D1 | 마케팅 | 서울 |
2 | 김철수 | D2 | 개발 | 부산 |
3 | 이영희 | D1 | 마케팅 | 서울 |
정규화된 테이블 예시 (3NF - 세 번째 정규형):
1.
직원 테이블 (직원 정보만 포함)
직원ID | 직원 이름 | 부서ID |
1 | 홍길동 | D1 |
2 | 김철수 | D2 |
3 | 이영희 | D1 |
2.
부서 테이블 (부서 정보만 포함)
부서ID | 부서 이름 | 부서 위치 |
D1 | 마케팅 | 서울 |
D2 | 개발 | 부산 |
4) 보이스코드 정규형
•
후보키가 아닌 속성에서 후보키의 일부 속성에 대한 함수 종속성 제거
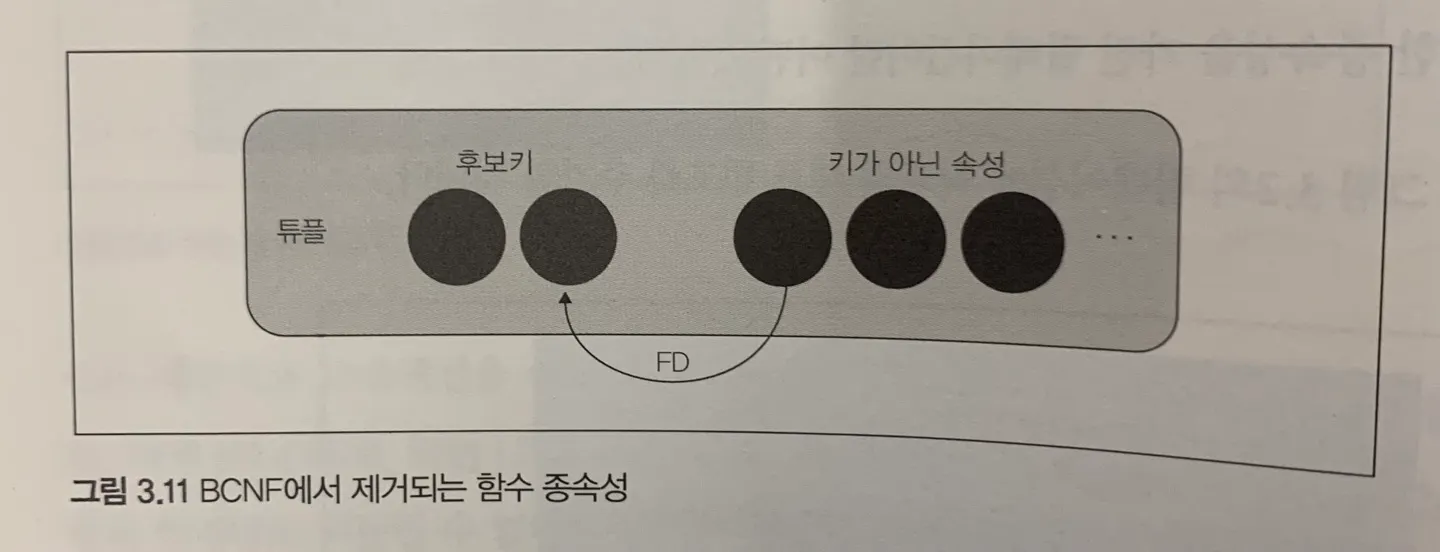
image from 오쿠노 미키야, 관계형 데이터베이스 실전 입문
다. 결합 종속성
1) 결합 종속성이란
2) 제 4 정규형
3) 제 5 정규형
4) 제 6 정규형
5. 릴레이션의 직교성
6. 도메인 설계 전략
가. 도메인
1) 정의
•
속성에 포함될 수 있는 값의 유한한 집합
2) 도메인 설계 전략
•
도메인 설계 전략(재정의): 설계 철학과 설계 노하우를 적용하여 속성이 가질 수 있는 유한한 값의 집합을 효과적으로 표현하는 것
•
저자의 도메인 설계 철학: DB 내 데이터는 데이터 자체의 본질을 잘 드러내야 함
•
저자의 도메인 설계 노하우
◦
속성별로 적절한 데이터 타입을 지정
◦
속성별로 명확한 이름을 지정
◦
자연키와 인공키에 대한 적절한 선택을 통해 기본키 결정
◦
제약사항으로 도메인의 범주를 구체화
나. 도메인 설계 전략 핵심
1) 설계 정답
•
설계작업은 논리 보다 작업자의 가치관과 경험을 바탕으로 결과를 도출하는 작업
◦
설계 전략 밑바탕에 깔린 철학과 노하우에 따라 작업하므로 설계에 정답은 없다
2) DB 설계 선작업: 응용프로그램 설계
•
DB 내 데이터가 응용프로그램에서 어떻게 사용될지에 대한 기획이 없으면 DB 내 데이터를 제대로 설계할 수 없음
•
응용프로그램의 주요 기능, 데이터 입출력 형태, 영속화할 데이터 목록 등을 DB 설계 전에 인지해야 함
•
영속화할 데이터란?
4) 데이터의 본질
•
도메인 설계 시 데이터의 본질을 드러내는 것의 이점
→ MVC 패턴의 이점과 같이 DB에서는 데이터 그 자체에만 신경쓸 수 있으므로 시스템 관리 복잡도가 낮아짐.
→ 시스템의 관리 복잡도가 낮아지면 유지보수에 용이함
•
도메인 설계 시 데이터 본질을 가장 잘 드러내는 데이터형을 지정해야 함
•
주의할 점
◦
데이터의 비본질적인 부분은 도메인 설계에서 고려하지 않는다
◦
비본질적인 부분이라 함은 응용프로그램 상에 표시, 사용자의 편리성 등이 해당된다
ex) 학생의 학번(8자리의 숫자로 표현)을 CHAR(8)로 지정하는 것
데이터 출력의 편리, 저장공간의 효율적 사용이라는 점에서 학번을 CHAR(8)로 지정했지만 학번의 본질은 8자리 숫자라는 점에서 INT로 지정하는 것이 적합함
5) 속성 이름 결정
•
속성 이름은 데이터의 본질을 잘 드러내도록 작성
◦
릴레이션 내에서 해당 속성의 역할이 이름에 포함되어야 한다
•
ORM을 사용하는 경우, 릴레이션, 속성과 매칭되는 클래스, 클래스 변수와 동일한 이름을 사용하는 것을 권장함
•
클래스, 클래스 변수에 대한 리팩토링에 따라 DB 내 이름도 함께 변경에되어야 함
6) 리팩토링
•
응용프로그램 단계에서의 리팩토링에 따라 구조적인 변화가 발생하면 DB 설계도 맞물려서 변경되어야 함
•
13장 DB의 리팩토링 참고
다. ID 설계
1) 자연키와 인공키
•
자연키: 현실세계에 이미 존재하는 데이터 중 식별자로 사용할 수 있는 것
ex) 주민등록번호, ISBN 등등
•
인공키: 현실세계에 존재하지 않지만 임의로 응용프로그램 또는 DB 내에 생성되어 식별자로 사용하는 것
2) 자연키 지정 시 고려사항
•
자연키의 신뢰성 확인
◦
ISBN의 경우 출판사의 실수에 따라 같은 책의 구판과 신판에 동일한 ISBN을 할당할 수 있음
•
자연키의 라이프사이클 확인
◦
충분히 오랫동안 사용될 수 있는지 확인해야 함
◦
탈레반 정부가 발행한 '아프가니스탄 주민등록번호'는 라이프사이클에 대한 검토가 필요함
3) 무분별한 인공키 사용 지양
•
기본키(Primary key)로 사용할 수 있는 자연키가 있음에도 인공키를 추가하는 것은 지양
◦
기본키로 사용할 수 있는 자연키에 대한 유니크 제약에 따라 인덱스 생성에 따른 오버헤드 발생
◦
만약 해당 자연키에 유니크 제약을 제거하면 데이터 중복 발생 가능
•
자연키로 구성된 복합 기본키를 대체하기 위해 인공키를 추가하면 추가적인 함수 종속성 발생함
◦
인공키 → 기존키 or 기존키 → 인공키
◦
함수 종속성을 제거하기 위해 릴레이션을 나누면 DB 복잡도는 커짐
라. 도메인의 SQL 표현
1) 적절한 데이터형 선택
•
도메인이 가질 수 있는 모든 데이터를 표현할 수 있는 데이터형 지정
◦
충분한 길이, 데이터 타입(문자 또는 정수) 등 고려
2) 술어를 제약으로 표현
•
CHECK 제약 활용하여 값의 범위에 제한을 설정함
→ 문자열이라면 정규표현식, 숫자라면 범주를 CHECK 제약으로 지정
→ MySQL에서 CHECK 제약을 지정할 수 있으나 쿼리 실행 시 CHECK 제약조건을 무시함
3) 도메인을 테이블로 표현
•
마스터 테이블로 도메인의 값의 범주를 제한하여 관리할 수 있음
◦
마스터 테이블: 카디널러티가 적은 경우나 CHECK 제약 설정이 어려운 경우(열거형) 실데이터를 테이블로 관리할 수 있음
•
열거형을 지원하는 일부 RDBMS의 경우 열거형을 활용하여 도메인 제약 가능
7. NULL과의 싸움
가. NULL 폐해
1) 2차 논리(2VL) vs 3차 논리(3VL)
3차 논리는 쿼리의 의도와 결과의 불일치에 따라 문제 발생 가능성이 높아지므로 개발 효율이 크게 떨어짐
•
3차 논리의 복잡도
→ 2차 논리연산의 경우의 수는 4가지
→ 3차 논리연산의 경우의 수는 9가지
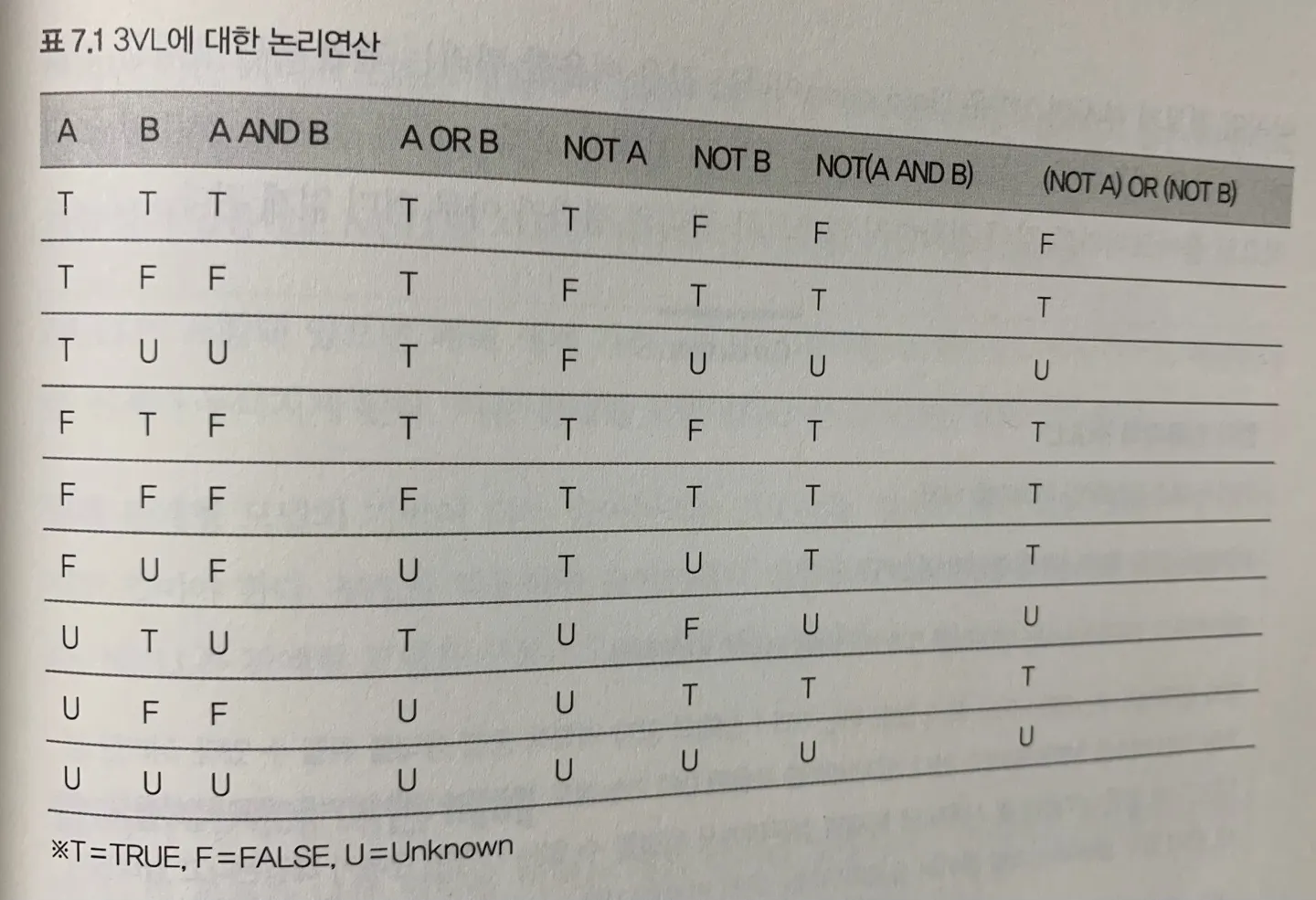
image from 129p, 관계형 데이터베이스 실전 입문, 오쿠노 미키야
2) 폐쇄 세계 가정 부정
RDB는 관계형 모델에 기반하고 관계형 모델은 2차논리에 기반하므로 3차 논리는 RDB의 파괴자
•
릴레이션은 2차 논리 위에 성립되므로 3차 논리는 관계형 모델의 폐쇄 세계 가정의 원칙을 파괴한다
→ 폐쇄 세계 가정: 모든 질의를 릴레이션의 연산만으로 해결함
→ 2차 논리: 명제가 가진 값은 참과 거짓 두 가지만 있어야 한다
3) 옵티마이저 성능 하락
NULL이 많아지면 옵티마이저와 쿼리 실행 비용이 증가할 수 있음
•
옵티마이저의 조합의 수가 줄어들어 쿼리 성능 최적화를 수동으로 해야하는 상황이 올 수 있다
→ NULL이 많아지면 옵티마이저의 쿼리 실행계획으로 재작성되는 쿼리의 수가 적어진다
→ 옵티마이저가 재작성하는 쿼리의 변수에 NULL이 포함되면 해당 쿼리는 채택할 수 있는 실행계획의 후보에서 탈락할 수 있다
•
인덱스에 NULL이 포함된 행은 인덱스의 제일 뒤나 앞으로 배치되므로 인덱스 스캔에 있어서 높은 비용을 든다
나. NULL 대책
1) 정규화
•
정규화에 따라 반복그룹 제거하는 것이 최선의 NULL 대책
→ 반복그룹: 테이블 내 같은 도메인에 속하는 값이 중복적으로 저장되는 것
→ 3장 참고
•
반복그룹 제거 방법
→ 같은 도메인에 속하는 값을 여러 행으로 나눠서 데이터를 저장한다
ex) 학생, 수업 1, 수업 2('MJ', 'DB', 'Network') → 학생, 수업 ('MJ', 'DB') ('MJ', 'Network')
2) 필요한 데이터만 저장
•
필요한 데이터만 DB에서 관리
3) COALESCE 함수
•
SQL 계산식에 의해 NULL을 발생시킬 수 있는 경우에 COALESCE 함수를 활용
→ 이하 다섯가지 상황에 대해 COALESCE 함수를 활용하여 기본값을 지정한다
# COALESCE 함수 사용 권장하는 경우
- 행의 개수가 0개인 행에 집계함수를 실행할 경우
- 행 서브 쿼리 또는 스칼라 실행 결과 일치하는 행이 없을 경우
- OUTER JOIN 실행 시 일치하는 행이 없을 경우
- CASE 식에서 어떤 조건에도 해당하지 않을 경우
- NULLIF 평가에 따라 NULL이 결과값으로 나온 경우
Plain Text
복사
# 예시
SELECT continent, COALESCE(SUM(population), 0)
FROM countries GROUP BY continent
Plain Text
복사
•
이미 NULL을 가지고 있는 컬럼에 대해 해당 함수를 사용 권장 X
→ 이미 NULL인 컬럼에 대해 해당 함수로 NULL인 경우에 특정 기본값을 지정하는 것은 큰 의미 없음
→ 최악의 경우, 의도치 않은 결과로 연산될 수 있음
4) LEFT JOIN
•
LEFT JOIN(or OUTER JOIN) 사용에 따라 일치하지 않는 행을 찾을 때는 'IS NULL' 평가가 어쩔 수 없이 필요함
5) DEFAULT 주의
•
NULL에 대응하기 위해 DEFAULT로 특정 값을 지정하는 방법이 아니라 NULL을 허용하는 컬럼을 최소화하는 방향으로 작업 권장
•
DEFAULT로 NULL에 가까운 데이터를 지정하는 것은 의도치 않은 연산 결과를 반환할 수 있음
ex) INT 데이터형의 경우 NULL 대신 -1을 입력하는 경우
6) NULL 허용하는 경우
•
관계형 모델이 아니라 다른 형태의 데이터 모델을 기반으로 데이터를 관리할 경우
8. SELECT 공략
가. SELECT 본질
1) SELECT의 역할
•
RDB에서 데이터 조회 담당
→ SQL에서 어떤 데이터를 얻을 것인가에 대한 논리적 의미를 담고 있음
2) 관계형 조작
•
관계형 조작: 릴레이션 연산에 따른 릴레이션 반환
→ SELECT 명령은 Project, Restrict, Product 릴레이션 연산이 기본으로 적용됨
3) 비관계형 조작
•
비관계형 조작: 비릴레이션 연산되거나 비릴레이션 형태로 값이 반환됨
→ ORDER BY: 집합에는 순서 개념이 없으므로 정렬은 비릴레이션 연산임
→ COUNT: 반환값이 릴레이션이 아니라 스칼라 값 형태로 반환되므로 비릴레이션 형태 반환임
나. SELECT 주의사항
쿼리에 비릴레이션 연산이 포함될 경우 상대적으로 성능이 떨어지는 쿼리 실행계획이 채택될 가능성이 높음
1) 비관계형 조작 시 주의사항
•
관계형 조작으로 대체 가능여부 재검토 필요
•
관계형 조작만으로 쿼리를 생성할 수 없다면 DB 설계 검토 필요
•
비관계형 조작이 필수적으로 포함되어야 한다면 쿼리 로직의 가장 마지막에 위치
2) SELECT & 집계함수
•
집계함수는 스칼라값을 반환하므로 비릴레이션 연산임
•
집계함수 중 COUNT는 공집합에 대해 0을 반환
•
COUNT 외의 집게함수는 공집합에 대해 NULL 반환
•
예시) students의 모든 행은 grade < 5 일 때, 이하 쿼리는 각각 0과 NULL을 반환
SELECT AVG(age) FROM students WHERE grade = 5;
SELECT COUNT(age) FROM students WHERE grade = 5;
SQL
복사
3) SELECT & GROUP BY
•
GROUP BY와 집계함수가 함께 사용하는 것은 관계형 조작임
•
GROUP BY와 집계함수의 사용은 릴레이션 연산 중 요약(Summarization)에 해당됨
→ 요약은 릴레이션 연산 중 확장의 일종으로 기존 릴레이션에 새로운 칼럼을 추가함
•
COUNT 외의 집계함수의 경우 GROUP BY로 지정된 컬럼에 대해 NULL을 반환하므로 이에 대한 대책 수립 필요
4) WHERE vs HAVING
•
WHERE: 집계 조작 전의 칼럼에 대한 조건 지정
•
HAVING: GROUP BY 절에 지정된 칼럼과 집계함수의 결과에 대해 조건 지정
→ WHERE 구에서 조건에 해당사항이 없는 데이터에 대해서는 HAVING의 연관조건으로도 조회할 수 없음
•
예시) 1, 2학년 학생이 30명 이하 포함된 학과명과 해당 학과의 학생수에 대한 쿼리문 작성
→ 30명 이하라면 0명도 포함되지만 이하의 쿼리로는 0명의 경우는 조회할 수 없음
→ 1, 2학년의 학생이 포함되지 않은 학과의 경우 WHERE 구에서 이미 해당사항이 없으므로 HAVING 구에 조건으로도 조회할 수 없음
# 1. WHERE구 해석: 1, 2학년 학생들의 department와 수를 조회
# 2. 집계 + HAVING구 해석: WHERE 구 조건에 따라 조회 시 학생수가 30명 이하인 department에 대해서만 조회함
SELECT department, COUNT(*)
FROM students
WHERE grade IN (1, 2)
GROUP BY department
HAVING COUNT(*) <= 30;
# 1, 2학년이 한 명 이상 속한 department에 대해서만 조회
# 다른 말로 1, 2학년이 한 명도 포함되지 않지만 다른 학년이 포함된 department는 조회 대상이 아님
SELECT department
FROM students
WHERE grade IN (1, 2);
SQL
복사
→ 이에 대한 대책으로 세 가지 해결 방법이 있음(상관쿼리, GROUP BY + LEFT JOIN, CASE)
# 상관쿼리 활용에 따른 문제 해결
SELECT department, (
SELECT COUNT(*)
FROM students
WHERE department = t1.department
AND grade in (1,2)
) AS COUNT
FROM (
SELECT DISTINCT department
FROM student ) t1
WHERE COUNT <= 30;
SQL
복사
5) SELECT & Sub Query
•
대부분의 서브쿼리는 Distinct와 JOIN으로 대체 가능
•
서브쿼리의 형태는 모두 SELECT이지만 반환값은 테이블을 포함한 스칼라, 행 등 다양하므로 조작이 까다로움
9. 이력 데이터와 친해지기
10. 그래프에 맞서다
11. 인덱스 설계 전략
가. 인덱스의 동작
1) RDS의 인덱스와 B+ tree
•
RDS의 인덱스는 B+ tree 자료구조의 형태
→ B+ tree를 인덱스의 자료구조로 가져간다면 각 노드에는 인덱스(회색음영)가 저장됨

•
리프노드: 최하위 계층의 노드, 인덱스에 대응하는 데이터 포인터 저장(실데이터, d)
→ 데이터 포인터를 통해 page에 접근하여 실데이터를 확인 가능
•
논리프노드: 특정 리프노드까지의 경로역할, 자식 노드에 해당하는 최소값(인덱스) 저장
•
루트노드: 경로의 출발점
2) B+ tree 인덱스의 특징
•
특정 인덱스를 찾기 위해 한 개의 경로만 검색
→ 루트 노드에서부터 논리프 노드를 거쳐 리프 노드에 이르는 하나의 경로만 검색하면 되므로 효율적임
→ 논리프 노드를 거칠 때마다 논리프 노드의 최소값을 비교하여 특정 인덱스의 위치를 하나의 경로로 추정할 수 있음
•
테이블 행의 수와 인덱스의 수가 비례하여 증가함
3) 인덱스의 왼쪽과 검색 범위
•
인덱스 검색의 경우 등가비교와 범위 검색에 효율적으로 사용 가능
•
인덱스를 기준으로 검색
→ 값(실데이터)를 기준으로 검색하는 것이 아님
•
등가비교
→ WHERE key = 13
→ 최소값을 기준으로 경로를 탐색하여 하나의 경로로 탐색 가능
→ 성능: O(logn)
•
범위 검색
→ BETWEEN 1 AND 13
•
전방일치 검색의 경우 인덱스를 기준으로 검색 가능
→ LIKE 'a%' (O)
•
전방일치 검색이 아닌 경우, 인덱스 기준으로 검색 불가능
→ LIKE '%a' (X)
나. 인덱스의 종류
1) 보조 인덱스
•
정의: 보조 인덱스의 리프노드에 레코드에 대한 참조값을 저장하여 특정 열의 데이터에 접근하는 인덱스
•
데이터 접근 방법: 특정 보조 인덱스 검색 시 보조 인덱스의 리프노드의 데이터 참조값을 확인하여 해당하는 데이터 페이지 접근
•
특징
→ 외래키, 유니크 키 등이 보조 인덱스로 활용
2) 클러스터 인덱스
•
정의: 기본키의 리프노드에 기본키에 매칭되는 다른 열의 데이터도 함께 구성된 인덱스
•
데이터 접근 방법
→ 기본 인덱스 데이터 접근: 기본키가 저장된 리프노드에 다른 열의 실데이터도 함께 저장되어 있으므로 기본키로 값 검색 시 추가적으로 데이터페이지에 접근할 필요가 없음
→ 보조 인덱스 데이터 접근: 트리를 거치게 되므로 약간의 오버헤드가 발생?
•
특징
→ MySQL의 InnoDB 엔진은 모든 테이블이 클러스터 인덱스로 작성됨
3) 커버링 인덱싱
•
정의: 하나의 SELECT 질의에 대해 모두 인덱스 컬럼으로만 구성하여 빠르게 조회하는 방법
•
데이터 접근 방법
→ 인덱스 컬럼만으로 데이터 접근
•
특징
→ 리프 노드의 데이터 페이지에 접근하지 않으므로 SELECT 질의 성능이 크게 향상됨
→ 자주 사용되는 컬럼이 있다면 인덱스로 지정하여 커버링 인덱싱 활용 권장
다. 파티셔닝
라. 관계형 모델과 인덱스
마. 최적의 인덱스 찾기
12. 웹 응용프로그램을 위한 데이터 구조
13. 리팩터링 최적의 해결책
14. 트랜잭션의 본질
Reference
•
오쿠노 미키야, 관계형 데이터베이스 실전 입문
•
인덱스의 종류, NAVER D2, https://d2.naver.com/helloworld/1155