1. Function
가. 함수 내 매개변수
1) 이름 붙인 매개변수(named parameter)
•
코틀린에서 함수 호출 시 정의된 매개변수 이름에 따라 값을 지정하여 전달할 수 있다.
// 함수 정의
fun greet(name: String, message: String) {
println("$message, $name!")
}
fun main() {
// 이름 붙인 인자로 함수 호출
greet(name = "Alice", message = "Hello")
}
Kotlin
복사
2) 기본 매개변수(default parameter)
•
함수 호출 시 매개변수를 전달하지 않는다면, 함수 정의 시 설정한 기본값이 전달된다.
•
불필요한 생성자 중복 선언을 줄일 수 있는 장점이 있다.
// 함수 정의
fun greet(name: String, message: String = "Hello") {
println("$message, $name!")
}
fun main() {
// message의 경우 기본 인자인 "Hello"가 전달됨
greet(name = "Alice")
}
Kotlin
복사
나. 확장 함수
1) 확장 함수의 정의
•
확장 함수란 객체 외부에 정의되었지만 해당 객체의 멤버처럼 호출할 수 있는 함수이다.
•
확장 함수의 내부 구현은 수신 객체를 첫 번째 매개변수로 받는 정적 메소드와 같다.
// MyCustomClass.kt 파일
class MyCustomClass(val value: Int){
// ...
}
// MyCustomClassExtensions.kt 파일
fun MyCustomClass.double(): Int {
return this.value * 2
}
// Main.kt 파일
import MyCustomClass
import double // 확장 함수 import
fun main() {
val obj = MyCustomClass(10)
val doubledValue = obj.double()
println("The doubled value is $doubledValue")
}
Kotlin
복사
2) 확장 함수를 사용할 수 없는 경우
•
객체의 private or protected 멤버에 접근해야 하는 경우, 해당 객체의 내부 메소드로 기능을 정의해야 한다.
•
특정 객체의 부모 객체에 정의된 메소드를 오버로딩해야할 경우, 확장 함수를 사용할 수 없다.
3) 확장 함수의 적절한 사용
•
새로운 기능을 추가하지만, 기존 클래스를 수정하고 싶지 않은 경우
ex) 코틀린에서 자바의 String을 대상으로 다양한 확장함수를 정의하여 자바 String의 내부 구현에 영향을 주지 않는다.
•
비즈니스 로직과는 무관한 유틸리티 함수를 구현할 경우
4) 확장 함수의 부적절한 사용
•
OOP의 다형성을 활용해야 하는 객체에 확장 함수를 적용한 경우
5) 확장 함수를 제네릭하게 활용하는 방법
•
Collection, CharSequence 등 Low Level 타입을 대상으로 확장 함수 정의 시 여러 타입에 범용적으로 사용할 수 있다. 특히 유틸리티 함수에 적용할 때 유용하다.
// List, Set, Map 등에서 사용할 수 있는 확장 함수
fun <T> Collection<T>.secondOrNull(): T? {
return if (this.size >= 2) this.elementAt(1) else null
}
// String, CharSequence 등에서 사용할 수 있는 확장 함수
fun CharSequence?.isNullOrEmpty(): Boolean {
return this == null || this.isEmpty()
}
Kotlin
복사
•
인터페이스를 바탕으로 확장 함수를 정의하고, 수신객체의 타입에 따라 확장 함수의 내부 구현을 정의하여 범용적으로 활용할 수 있다.
// 확장 함수에 대한 인터페이스 정의
interface SecondOrNullProvider<T> {
fun getSecondOrNull(): T?
}
// 확장 함수 정의
fun <T> SecondOrNullProvider<T>.secondOrNull(): T? {
return this.getSecondOrNull()
}
// String 타입 대상 확장 함수 정의
class StringSecondOrNullProvider(val str: String) : SecondOrNullProvider<Char> {
override fun getSecondOrNull(): Char? {
return if (str.length >= 2) str[1] else null
}
}
// StirngBuilder 대상 확장 함수 정의
class StringBuilderSecondOrNullProvider(val sb: StringBuilder) : SecondOrNullProvider<Char> {
override fun getSecondOrNull(): Char? {
return if (sb.length >= 2) sb[1] else null
}
}
Kotlin
복사
다. Collection Handling
1) vararg(가변 인자)
•
vararg를 활용하면 동일한 타입의 값에 대해 개수 제한을 두지 않고 함수의 매개변수로 전달할 수 있다.
// vararg 활용 함수 정의
fun sum(vararg numbers: Int): Int {
var result = 0
for (num in numbers) {
result += num
}
return result
}
// vararg 활용 함수 호출
val result = sum(1, 2, 3, 4, 5)
println("Result is $result") // 출력 결과: Result is 15
Kotlin
복사
2) infix function(중위 함수)
•
중위 함수란 수신 객체와 하나의 메소드 인자가 존재할 경우, 간편하게 호출할 수 있도록 정의한 함수이다.
•
중위 함수 활용에 따라 코드의 가독성을 높일 수 있지만, 함수의 이름을 모호하게 정의할 경우 오히려 코드 가독성을 낮출 수도 있다.
// 중위 함수 정의
infix fun Int.add(other: Int): Int {
return this + other
}
// 중위 함수 호출
val result = 1 add 2
println("Result is $result") // 출력 결과: Result is 3
Kotlin
복사
3) destructuring declaration(구조 분해 선언)
•
구조 분해 선언은 객체가 아닌 내부 요소를 분해하여 반환 받을 수 있는 방법이다. 구조 분해 선언은 List, Map, data class를 대상으로 빈번하게 사용된다.
val (x, y, z) = listOf(1, 2, 3)
println("x: $x, y: $y, z: $z") // 출력 결과: x: 1, y: 2, z: 3
Kotlin
복사
•
참고로 class로 정의된 객체의 경우, componentN() 함수를 정의하여 구조 분해 선언을 활용할 수 있다.
class Person(val name: String, val age: Int) {
operator fun component1() = name
operator fun component2() = age
}
val (name, age) = Person("John", 30)
println("Name: $name, Age: $age") // 출력 결과: Name: John, Age: 30
Kotlin
복사
•
data class의 경우, componentN() 함수가 자동 정의되어 있으므로 주 생성자에 전달된 매개변수의 순서에 따라 구조 분해 선언으로 객체의 각 요소를 반환 받을 수 있다.
data class Person(val name: String, val age: Int)
val (name, age) = Person("John", 30)
println("Name: $name, Age: $age") // 출력 결과: Name: John, Age: 30
Kotlin
복사
라. 로컬 함수와 확장 함수로 리팩토링
1) 로컬 함수 활용 리팩토링
•
하나의 함수에 존재하는 중복 로직을 제거할 경우 로컬 함수 활용하고, 중복은 없지만 캡슐화가 필요한 복잡한 로직에는 비공개 메소드를 활용하는 방향은 어떤가? 중복이 없는데 같은 함수 내 로컬함수를 정의하는 것은 오히려 불필요하게 로컬함수 시그니처를 생성하게 된다.
•
하나의 함수에 중복 로직이 존재할 경우, 함수 내부에 로컬 함수를 정의하여 중복 로직을 제거할 수 있다. 로컬 함수로 정의할 경우 매개변수 전달 받은 값 외에도 원 함수(processData)에 선언된 변수에 접근할 수 있다는 특징을 활용할 수 있다.
// 중복 로직이 존재하는 예시
fun processData(data: List<Int>) {
var sum = 0
for (item in data) {
sum += item
}
println("합계: $sum")
var product = 1
for (item in data) {
product *= item
}
println("곱: $product")
}
Kotlin
복사
// 로컬 함수로 중복 로직을 제거한 예시
fun processData(data: List<Int>) {
fun calculate(initialValue: Int, operation: (Int, Int) -> Int): Int {
var result = initialValue
for (item in data) {
result = operation(result, item)
}
return result
}
val sum = calculate(0) { a, b -> a + b }
println("합계: $sum")
val product = calculate(1) { a, b -> a * b }
println("곱: $product")
}
Kotlin
복사
2) 확장 함수 활용 리팩토링
•
만약 로컬 함수가 private이나 protected 멤버를 사용하지 않는다면 확장 함수로 재정의하여 가독성을 더 높일 수 있다.
// 로컬 함수를 확장 함수로 빼서 개선한 예시
fun List<Int>.calculate(initialValue: Int, operation: (Int, Int) -> Int): Int {
var result = initialValue
for (item in this) {
result = operation(result, item)
}
return result
}
fun processData(data: List<Int>) {
val sum = data.calculate(0) { a, b -> a + b }
println("합계: $sum")
val product = data.calculate(1) { a, b -> a * b }
println("곱: $product")
}
Kotlin
복사
마. 기타 질문
1) 이름 붙인 인자 활용
•
IDE에서 기본적으로 제공하는 인자 힌트로도 유사 효과를 볼 수 있음. 하지만 IDE 인자 힌트의 경우, 일부 비활성화되는 경우가 존재하므로 가능하다면 이름 붙인 인자 활용 권장
2) 로컬 함수 vs private 멤버 메소드
•
로컬함수는 Public mehtod의 간결성을 떨어뜨리므로 private 메소드를 사용하는 것이 낫다. 로컬 함수는 kotest DSL에 자주 사용되는데, 로컬 함수를 사용해서 테스트의 케이스를 응집도 있게 묶을 수 있기 때문이다. 만약 private으로 빼버리면 하나의 테스트 케이스를 읽는데 왔다갔다 읽어야 하니까 테스트 코드 가독성이 떨어진다.
3) 확장 함수 vs public 멤버 메소드
•
외부 라이브러리를 활용할 때는 확장함수 활용에 좋다. 확장 함수를 활용하면 DTO 변환 등에서 코드를 깔끔하게 변경할 수 있다.
2. Class, Object, Interface
가. Data Class
1) toString, equals, hashCode
•
data class로 선언하면 위의 세 가지 메소드를 내부적으로 정의된다.
•
참고로 코틀린에서 연산자 비교(==)는 equals를 호출하여 사용된다.
•
JPA에서도 내부적으로 equals와 hashCode를 사용하므로 꼭 정의되어야 한다.
2) copy
•
데이터 클래스의 불변성을 지키면서 유사한 인스턴스가 필요할 경우, copy 메소드를 정의하면 편리하다.
•
참고로 copy는 얕은 복사이기 때문에 원객체와 복사객체가 동일한 참조를 같고 있다. 만약 불변 객체로 정의되어 있다면 얕은 복사에 따른 부작용은 발생하지 않는다.
data class Person(val name: String, val age: Int) {
fun copy(name: String = this.name, age: Int = this.age) : Person {
return Person(name, age)
}
}
fun main() {
val person1 = Person("John", 25)
val person2 = person1.copy(age = 30)
println(person1) // Person(name=John, age=25)
println(person2) // Person(name=John, age=30)
}
Kotlin
복사
나. Object keyword
1) object
•
객체 정의와 인스턴스 생성 작업을 동시에 함으로써 싱글턴 패턴을 편리하게 구현할 수 있다.
2) companion object
•
java의 정적 멤버를 kotlin에서 사용할 수 있다.
•
객체의 비공개 멤버에 접근 가능하고 최상위 함수와 같이 동작하므로 팩토리 메소드를 편리하게 구현할 수 있다.
다. 기타 질문
1) hashCode의 재정의와 성능 간 연관성
•
hashCode를 재정의하지 않으면 기본 hashCode 함수를 오버로딩해서 사용한다. 기본 hashCode는 객체의 메모리 주소를 기반으로 HashCode를 만들기 때문에 해쉬 기반 컬렉션에서 충돌 발생 가능성이 비교적 높다. 만약 해쉬 충돌이 발생하면 충돌된 해쉬에 대해 추가적인 자료구조를 사용하므로 해쉬의 시간 복잡도가 O(1)에서 O(n)으로 늘어날 수 있다.
2) 인스턴스 생성 방법 비교
•
factory method(with companion object) vs 생성자 vs factory class
팩토리 메소드로 인스턴스 생성 예시
생성자로 인스턴스 생성 예시
Factory Class로 인스턴스 생성 예시
3. Lambda
가. 기본 개념
1) 일반
•
람다란 이름 없는 함수에 대한 표현식
•
프로그래밍의 람다는 수학의 람다 대수에서 유래
•
람다 대수는 복잡한 계산식을 함수의 조합만으로 표현하는 함수적 계산 모델
2) 핵심 문법
•
화살표(→)로 인자와 본문 구분
•
람다 표현식은 중괄호{}로 표현
•
람다의 인자가 하나일 경우, it 키워드로 대체 가능
•
람다 인자와 반환값의 타입을 자동으로 추론
•
람다 표현식을 멤버 참조로 대체 가능
•
일급 객체 세 가지 조건 만족
: 람다를 함수의 인자로 전달 가능
: 람다를 변수에 대입 가능
: 람다를 함수의 리턴 값으로 사용 가능
•
핵심 문법 적용 예시
data class Image(val name: String, val format: String, val fileSize: Long)
fun printImageNames(images: List<Image>, predicate: (Image) -> Boolean) {
images.filter(predicate).forEach { println(it.name) }
}
fun main() {
val images = listOf(
Image("image1", "jpeg", 2000),
Image("image2", "png", 3000),
Image("image3", "jpeg", 1000)
)
// 람다를 함수의 인자로 전달
printImageNames(images) { image ->
// 중괄호({})로 람다 표현식 표현, 화살표(→)로 인자와 본문 구분
// 람다 내 매개변수와 반환값의 타입을 자동으로 추론
image.format == "jpeg" && image.fileSize > 1500
}
// it 키워드 사용
printImageNames(images) {
it.format == "jpeg" && it.fileSize > 1500
}
// 멤버 참조 사용
val imageNames = images.map(Image::name)
println(imageNames)
// 람다를 변수에 대입
val jpegPredicate: (Image) -> Boolean = { it.format == "jpeg" }
printImageNames(images, jpegPredicate)
// 람다를 함수의 리턴 값으로 사용
fun createSizePredicate(minSize: Long): (Image) -> Boolean = { it.fileSize > minSize }
val sizePredicate = createSizePredicate(1500)
printImageNames(images, sizePredicate)
}
Kotlin
복사
3) 람다 활용의 장단점
•
장점: 코드가 간결해짐에 따라 가독성 향상 및 휴먼 에러 가능성 감소
•
단점: 외적으로는 단순하게 바꿔도, 내적으로 더 복잡하게 연산할 가능성 존재
나. 컬렉션 함수형 API 활용
1) filter, map, find, count, size, any, all
•
생략
2) group by
•
컬렉션 요소의 특정 속성을 Key로 갖는 Map의 형태로 변환함
•
Collection<T> → Map<Any, Collection<T>>
•
적용 예시
data class Image(val id: Int, val name: String, val format: String, val fileSize: Long, val category: String, val author: String)
fun main() {
val images = listOf(
Image(1, "image1", "jpeg", 4096, "Nature", "Alice"),
Image(2, "image2", "png", 6144, "City", "Bob"),
Image(3, "image3", "jpeg", 2048, "Nature", "Alice"),
Image(4, "image4", "png", 8192, "City", "Charlie"),
Image(5, "image5", "jpeg", 5120, "Nature", "Alice")
)
// 이미지를 카테고리별로 그룹화하고 각 그룹의 이미지 크기 합계를 구함
val categoryGroups = images.groupBy { it.category }
categoryGroups.forEach { (category, imageList) ->
println("$category:")
imageList.forEach { image ->
println(" Image: ${image.name}, File size: ${image.fileSize} Bytes, Author: ${image.author}")
}
}
}
Kotlin
복사
// 출력 결과
Nature:
Image: image1, File size: 4096 Bytes, Author: Alice
Image: image3, File size: 2048 Bytes, Author: Alice
Image: image5, File size: 5120 Bytes, Author: Alice
City:
Image: image2, File size: 6144 Bytes, Author: Bob
Image: image4, File size: 8192 Bytes, Author: Charlie
Kotlin
복사
3) flatMap, flatten
•
flatMap: 콜렉션의 중첩 콜렉션의 요소를 나열(flat) 후 변환함(map)
적용 예시 1의 첫번째 출력문의 결과는 category별로 내부의 imageList의 모든 요소를 나열한다. 다시 말해, 하나의 중첩된 컬렉션의 요소를 모두 나열하여 작업하는 것을 볼 수 있다.
•
flatten: 콜렉션의 중첩 콜렉션의 요소를 나열만 함
•
적용 예시
val fileSizeSumByCategory = categoryGroups.flatMap { (category, imageList) ->
println("imageList: $imageList")
listOf(Pair(category, imageList.sumByLong { it.fileSize }))
}
println("File size sum by category using flatMap:")
fileSizeSumByCategory.forEach { (category, fileSizeSum) ->
println(" Category: $category, File size sum: $fileSizeSum Bytes")
}
val aliceImages = images.filter { it.author == "Alice" }
val bobImages = images.filter { it.author == "Bob" }
val charlieImages = images.filter { it.author == "Charlie" }
val allImages = listOf(aliceImages, bobImages, charlieImages).flatten()
println("All images combined using flatten:")
allImages.forEach { image ->
println(" Image: ${image.name}, Category: ${image.category}, Author: ${image.author}")
}
Kotlin
복사
// 출력 결과
imageList: [Image(id=1, name=image1, format=jpeg, fileSize=4096, category=Nature, author=Alice), Image(id=3, name=image3, format=jpeg, fileSize=2048, category=Nature, author=Alice), Image(id=5, name=image5, format=jpeg, fileSize=5120, category=Nature, author=Alice)]
imageList: [Image(id=2, name=image2, format=png, fileSize=6144, category=City, author=Bob), Image(id=4, name=image4, format=png, fileSize=8192, category=City, author=Charlie)]
File size sum by category using flatMap:
Category: Nature, File size sum: 11264 Bytes
Category: City, File size sum: 14336 Bytes
All images combined using flatten:
Image: image1, Category: Nature, Author: Alice
Image: image3, Category: Nature, Author: Alice
Image: image5, Category: Nature, Author: Alice
Image: image2, Category: City, Author: Bob
Image: image4, Category: City, Author: Charlie
Kotlin
복사
다. Best Practice
1) first filter then map
•
filter에서 우선 요소를 걸러야 map에서 불필요한 연산이 발생하지 않는다.
2) count > size
•
컬렉션 내 요소의 개수를 구할 때, count를 활용하면 중간 컬렉션을 생성하지 않으므로 성능 상 이점이 있다.
3) 컬렉션 내 요소가 많을 경우 지연 계산 활용
•
중간 컬렉션 생성 과정이 생략되고, 컬렉션 원소의 순서로 필요한 모든 연산이 수행되기 때문에 요소가 많을 경우 성능 상 이점이 있다. 참고로 람다는 중간 연산의 결과로 중간 컬렉션이 생성된다.
•
8.2절에서 즉시 계산이 성능 상 이점이 되는 경우를 설명한다.
4) list.any {it != 3} > !list.all {it == 3}
•
부정 연산자는 등호 연산자로 이동하는 것이 가독성 면에서 낫다.
라. 수신 객체 지정 람다
1) 일반
•
정의: 수신 객체를 인자로 전달하는 람다
•
람다 내 참조 방식(this vs it)
: this는 수신 객체 지정 람다에서 수신 객체를 참조함
: it은 람다 표현식에서 매개변수가 하나일 경우, 해당 매개변수를 참조함
: 참조 방식(this vs it) 예시
data class Image(val name: String, val format: String, val fileSize: Long)
val image = Image("sampleImage", "jpeg", 2048)
// let을 사용하여 이미지의 파일 형식을 대문자로 변경하고 출력
val upperFormat = image.let {
it.format.toUpperCase()
}
println(upperFormat) // JPEG
// apply를 사용하여 이미지의 파일 형식을 대문자로 변경하고 파일 크기를 KB 단위로 변경
val modifiedImage = image.apply {
format = format.toUpperCase()
fileSize /= 1024
}
println(modifiedImage) // Image(name=sampleImage, format=JPEG, fileSize=2)
Kotlin
복사
2) 수신 객체 지정 람다 함수
•
with vs run
: 두 함수 모두 참조 방식과 사용 목적은 같으나, 호출 방식에만 차이가 있음
: with는 첫 번째 인자로 수신 객체를 받고 두 번째 인자로 람다를 받음
: run은 수신 객체의 확장 함수 형태로 호출하며 람다를 인자로 받음
•
with vs apply
: 공통점은 두 함수 모두 수신 객체의 멤버에 this로 접근
: 차이점은 with은 람다 본문 내 마지막 식을 반환하고, apply는 람다 내 연산된 수신 객체를 반환
•
함수 간 비교표
함수 | 참조 방식 | 반환 값 | 사용 목적 |
with | this | 람다 결과
(람다 내
마지막 식) | - 수신 객체의 프로퍼티를 변경
- 수신 객체의 함수를 호출 |
apply | this | 수신 객체 | - 객체 초기화 및 설정을 수행하고 객체 자체를 반환할 때 사용
- 주로 객체의 프로퍼티를 변경하거나 객체를 구성하는 데 사용 |
run | this | 람다 결과
(람다 내
마지막 식) | - 수신 객체의 프로퍼티를 변경
- 수신 객체의 함수를 호출 시 사용 |
also | it | 수신 객체 | - 변경된 객체와 함께 다른 작업을 수행해야 할 때 사용
- 주로 객체의 프로퍼티를 변경하고 로깅이나 이벤트를 발생시키는 데 사용 |
let | it | 람다 결과
(람다 내
마지막 줄) | - 수신 객체의 값을 변경하지 않으면서 수신 객체를 사용
- 수신 객체가 null이 아닌 경우에만 람다를 실행하는 데 사용 |
•
각 함수 적용 예시
data class Image(val name: String, var format: String, var fileSize: Long)
val image = Image("sampleImage", "jpeg", 2048)
// with 함수 예시
val withResult = with(image) {
format = format.toUpperCase()
fileSize /= 1024
"Name: $name, Format: $format, File Size: $fileSize KB"
}
println(withResult) // Name: sampleImage, Format: JPEG, File Size: 2 KB
// apply 함수 예시
val modifiedImage = image.apply {
format = format.toUpperCase()
fileSize /= 1024
}
println(modifiedImage) // Image(name=sampleImage, format=JPEG, fileSize=2)
// run 함수 예시
val runResult = image.run {
val upperFormat = format.toUpperCase()
val fileSizeInKb = fileSize / 1024
"Name: $name, Format: $upperFormat, File Size: $fileSizeInKb KB"
}
println(runResult) // Name: sampleImage, Format: JPEG, File Size: 2 KB
// also 함수 예시
val loggedImage = image.also {
it.format = it.format.toUpperCase()
println("Image format has been changed to: ${it.format}")
}
println(loggedImage)
// Image format has been changed to: JPEG
// Image(name=sampleImage, format=JPEG, fileSize=2)
// let 함수 예시
val letResult = image.let {
val upperFormat = it.format.toUpperCase()
val fileSizeInKb = it.fileSize / 1024
"Name: ${it.name}, Format: $upperFormat, File Size: $fileSizeInKb KB"
}
println(letResult) // Name: sampleImage, Format: JPEG, File Size: 2 KB
Kotlin
복사
마. 고차함수
1) 고차함수란
•
고차함수(High Order Function): 다른 함수를 인자로 받거나 반환하는 함수
ex) filter, map 등은 함수(람다)를 매개변수로 받기 때문에 고차함수이다.
•
람다를 매개변수로 전달하고 반환 받기 위해서는 함수 타입에 대한 정의가 필요하다. 함수 타입에 대한 정의는 매개변수와 반환 타입을 정의하는 것이다.
ex) (Int, String) → Unit
2) 고차함수를 활용한 중복 제거
•
서비스 로직의 전체적인 흐름은 그대로 유지하면서 일부 함수만 변경할 때, 고차함수를 사용하면 중복을 제거할 수 있다.
•
이하 예제 코드에서는 Image의 태그를 가공하는데 필요한 세 개의 함수 중 메인 함수를 람다로 정의해서 각 공개 메소드 내 선언된 고차함수에서 받는다. 나머지 중복적으로 사용되는 두 개의 함수는 비공개 메소드로 정의해서 고차함수에서 메소드 참조로 전달한다.
예제 코드
고차함수로 개선 전 코드
고차함수로 개선 후 코드
바. 람다 인라인
1) Inlining 성능 최적화 원리
•
컴파일러는 inline 변경자로 정의된 함수를 호출 시점에 람다식을 풀어서 함수 호출 본문에 적용한다. 이하 왼쪽의 코드가 오른쪽의 코드와 같은 형태로 컴파일된다.
•
위와 같은 원리로 람다식 적용에 따라 런터임 시점에 생성되는 무명 객체의 생성 비용이 줄어들어 성능면에서 이점이 있다. 무명 객체는 new Function과 같은 형태로 컴파일 시점에 생성되기 때문에 비용이 든다.
•
다만 JVM의 JIT에서 성능을 고려하여 inline으로 정의되지 않은 함수도 인라인 함수와 같이 적용하여 컴파일 한다.
inline fun performOperation(x: Int, y: Int, operation: (Int, Int) -> Int): Int {
return operation(x, y)
}
fun main() {
val sum = performOperation(5, 3) { a, b -> a + b }
val product = performOperation(5, 3) { a, b -> a * b }
println("Sum: $sum") // Output: Sum: 8
println("Product: $product") // Output: Product: 15
}
Kotlin
복사
fun main() {
val sum = 5 + 3
val product = 5 * 3
println("Sum: $sum") // Output: Sum: 8
println("Product: $product") // Output: Product: 15
}
Kotlin
복사
2) Inlining 주의사항
•
람다식은 컴파일 시점에 함수 호출 본문에 적용되기 때문에 람다식을 변수로 저장하여 동적으로 사용하는 경우 인라인으로 사용될 수 없다.
•
시퀀스의 경우, 람다식을 변수로 저장하여 각 고차함수에서 사용하기 때문에 인라인이 적용되지 않는다. 따라서 요소가 적은 컬렉션의 경우, 시퀀스를 사용하면 인라인 적용에 따른 성능 상의 이점을 누릴 수 없게된다.
3) 자바에서는 람다에서 지역 리턴을 쓰는데 코틀린에서는 지역 리턴을 사용하는 이유
사. 연습문제
1) 람다 성능 개선 문제
•
연습 문제 1: findMatchingImages의 성능 이슈를 밝히고, 개선 방법을 제시하시오.
data class Image(
val creatorId: Int,
val url: String,
val fileSize: Long,
val format: String,
val tags: List<String>
)
// 특정 사용자가 업로드한 이미지 중 일부 조건에 맞는 이미지만 반환
fun findMatchingImages(images: List<Image>, userId: Int): List<Image> {
return images.map { it.copy(tags = it.tags.sorted()) } // Image.tags 정렬하여 새로운 이미지 객체 생성
.sortedByDescending { it.fileSize }
.filter { it.creatorId == userId }
.distinctBy { it.format }
.take(10)
}
Kotlin
복사
개선 방법
•
연습 문제 2: countLargeImages 의 성능 이슈를 밝히고, 개선 방법을 제시하시오.
// 이미지 목록에서 크기가 sizeThreshold보다 큰 이미지의 개수를 반환
fun countLargeImages(images: List<Image>, sizeThreshold: Long): Int {
return images.filter { it.fileSize > sizeThreshold }.size
}
Kotlin
복사
개선 방법
3) any와 all의 활용 문제
•
연습 문제 1: any 또는 all을 사용하여 이하의 함수를 구현하시오.
// 주어진 이미지 목록 중에서 크기가 sizeThreshold보다 큰 JPEG 이미지가 존재하는지 확인
// 조건에 맞는 이미지가 있다면, true를 반환하고 그렇지 않으면 false를 반환
fun hasLargeJpegImages(images: List<Image>, sizeThreshold: Long): Boolean {
// 구현 필요
}
Kotlin
복사
답안 예시
•
연습 문제 2: any 또는 all을 사용하여 이하의 함수를 구현하시오.
// 주어진 이미지 목록의 모든 이미지 크기가 minSize와 maxSize 범위 내에 있는지 확인
// 모든 이미지가 해당 범위 내에 있다면 true를 반환하고, 그렇지 않으면 false를 반환
fun areAllImagesWithinSizeRange(images: List<Image>, minSize: Long, maxSize: Long): Boolean {
// 구현 필요
}
Kotlin
복사
답안 예시
4) 수신 객체 지정 람다 활용 문제
•
연습 문제 1: 이하의 세 가지 함수를 구현하시오.
data class Image(val name: String, val format: String, val fileSize: Long)
// Image::fileSize 기본 단위(Bytes)를 KB 단위로 반환하는 함수
fun fileSizeInKB(image: Image): Long {
// 구현 필요
}
// 람다 표현식을 사용하여 이미지 필터링하는 함수
fun filterImages(images: List<Image>, predicate: (Image) -> Boolean): List<Image> {
// 구현 필요
}
fun main() {
val images = listOf(
Image("image1", "jpeg", 4096),
Image("image2", "png", 6144),
Image("image3", "jpeg", 2048)
)
// 3KB 이상인 이미지만 반환
val largeImages = filterImages(images) {
// 수신 객체 람다로 구현 필요
}
}
Kotlin
복사
답안 예시
•
연습 문제 2: 수신 객체 지정 람다를 사용하여 이하의 확장 함수를 구현하시오.
data class Image(val name: String, val format: String, val fileSize: Long)
// 구현 필요
fun Image.isMatchingFormatAndFileSize(format: String, minimumSize: Long): Boolean
fun printImageNames(images: List<Image>, predicate: (Image) -> Boolean) {
images.filter(predicate).forEach { println(it.name) }
}
fun main() {
val images = listOf(
Image("image1", "jpeg", 2000),
Image("image2", "png", 3000),
Image("image3", "jpeg", 1000)
)
// 괄호 밖 람다(trailing lambda) 개념을 적용하여, 마지막 매개변수로 정의된 람다를 소괄호 밖으로 빼서 사용함
printImageNames(images) { it.isMatchingFormatAndFileSize("jpeg", 1500) }
}
Kotlin
복사
답안 예시
4. DSL

DSL 기반 API 설계 의도: 객체 사이의 연결지점(API)을 간결하게 표현함으로써 코드의 가독성과 유지보수성을 높이는 것이다.
가. DSL이란
1) 범용 프로그래밍 언어 VS 영역 특화 언어
•
범용 프로그래밍 언어(general-purpose programming language)는 대부분의 어플리케이션 개발에 사용되는 언어로 자바, C# 등이 있다. 반면 영역 특화 언어(domain-specific language)는 개발의 일부 영역에만 사용되는 언어로 SQL, 정규식 등이 있다.
•
DSL은 어플리케이션 개발 일부 영역에만 사용되고, 범용 프로그래밍 언어에 비해 선언적이다. 간단한 데이터를 얻는다고 가정할 때, SQL의 질의문과 Java의 조건 및 반복문에서 그 차이를 알 수 있다. 더불어 DSL은 범용 프로그래밍 언어의 일부 과정을 생략할 수 있어서 보다 간략하다. 예를 들어, 객체 생성, 메소드 정의 등의 설정 작업을 생략할 수 있다.
•
DSL의 단점은 추가적인 학습 비용과 범용 프로그래밍 언어와의 호환 비용이 발생한다는 것이다.
2) 내부 DSL
•
내부 DSL은 범용 프로그래밍 언어의 문법을 그대로 따라가면서도 DSL의 선언적이고 간결한 특징을 살리기 때문에 DSL의 단점을 상쇄한다.
•
Kotlin 기반의 DSL이 바로 내부 DSL이다.
3) 전통 API vs 코틀린 DSL 기반 API
•
전통 API는 오직 정의된 메소드만을 호출하여 사용한다. 메소드 호출 사이에는 연결고리가 없다.
•
코틀린 DSL 기반 API의 장점은 특정 결과를 얻기 위해 매개변수를 한 번에 전달하지 않고, 조합된 여러 메소드에 나눠서 전달할 수 있기 때문에 가독성이 높아진다.
•
코틀린 DSL 기반 API는 여러 메소드의 호출을 조합하여 보다 유연하게 사용할 수 있다. ‘람다 중첩’, ‘메소드 호출 연쇄’ 등의 문법을 활용하여 메소드 호출 사이의 구조 또는 문법을 만들어낸다.
// 전통 API 활용
val image = Image("image.jpg")
val imageProcessor = ImageProcessor()
imageProcessor.filter(image, Filter.GRAYSCALE)
imageProcessor.resize(image, 800, 600)
Kotlin
복사
// 코틀린 DSL 기반 API 활용
val image = Image("image.jpg")
val imageProcessor = ImageProcessor(image)
imageProcessor.transform {
filter(Filter.GRAYSCALE)
resize(800, 600)
}
Kotlin
복사
나. DSL 연관 핵심 문법
1) 람다 & 수신 객체 지정 람다 & 확장 함수
•
•
함수의 매개변수로 확장함수 타입을 지정하면 기본 람다 타입을 지정했을 때보다 여러 중복을 제거하여 가독성을 높일 수 있다.
// 매개변수로 기본 람다 타입 활용
fun main() {
val ocp = Ocp()
ocp.addImage { image ->
image.url = "https://example.com/image1.jpg"
image.width = 800
image.height = 600
}
ocp.addImage { image ->
image.url = "https://example.com/image2.jpg"
image.width = 1200
image.height = 900
}
}
class Ocp {
private val images: MutableList<Image> = mutableListOf()
fun addImage(init: (Image) -> Unit): Image {
val image = Image("", 0, 0)
init(image)
images.add(image)
return image
}
fun filterImages(predicate: (Image) -> Boolean): List<Image> {
return images.filter(predicate)
}
}
data class Image(var url: String, var width: Int, var height: Int)
Kotlin
복사
fun main() {
buildOcp {
addImage {
url = "https://example.com/image1.jpg"
width = 800
height = 600
}
addImage {
url = "https://example.com/image2.jpg"
width = 1200
height = 900
}
}
}
fun buildOcp(block: Ocp.() -> Unit) = with(Ocp()) {
block
}
class Ocp {
private val images: MutableList<Image> = mutableListOf()
fun addImage(init: Image.() -> Unit) {
val image = Image("", 0, 0)
image.init()
images.add(image)
}
fun filterImages(predicate: Image.() -> Boolean): List<Image> {
return images.filter { it.predicate() }
}
}
data class Image(var url: String, var width: Int, var height: Int)
Kotlin
복사
2) 람다 타입의 재정의(기본 람다 타입 → 확장 함수 타입)
•
기본 람다 타입 활용 builderString 정의
fun buildString(
builderAction: (StringBuilder) -> Unit
) : String {
val sb = StringBuilder()
builderAction(sb)
return sb.toString()
}
val s = builderString { string ->
string.append("Hello, ")
stirng.append("World!")
}
Kotlin
복사
fun buildString(
builderAction: (StringBuilder) -> Unit
) : String {
val sb = StringBuilder()
builderAction(sb)
return sb.toString()
}
val s = builderString {
it.append("Hello, ")
it.append("World!")
}
Kotlin
복사
•
확장 함수 타입 활용 builderString 정의
fun buildString(
builderAction: StringBuilder.() -> Unit
) : String {
val sb = StringBuilder()
sb.builderAction()
return sb.toString()
}
val s = builderString {
this.append("Hello, ")
this.append("World!")
}
Kotlin
복사
fun buildString(
builderAction: StringBuilder.() -> Unit
) : String {
val sb = StringBuilder()
sb.builderAction()
return sb.toString()
}
val s = builderString {
append("Hello, ")
append("World!")
}
Kotlin
복사
•
확장 함수 타입 활용 builderStirng 정의 + apply 활용
fun buildString(
builderAction: StringBuilder.() -> Unit
) : String = StringBuilder().apply(builderAction).toString()
val s = builderString {
append("Hello, ")
append("World!")
}
Kotlin
복사
fun buildString(
builderAction: StringBuilder.() -> Unit,
): String = with(StringBuilder()) {
builderAction()
toString()
}
val s = builderString {
append("Hello, ")
append("World!")
}
Kotlin
복사
3) invoke 관례
•
기초 문법: 관례란 특수 문법에 따라 일부 함수를 더 간단한 방법으로 호출하는 기능이다. ex) boo.get(bar) → boo[bar]
•
invoke 관례란 invoke 함수가 정의된 객체를 간단하게 호출하는 것이다. 오직 소괄호와 매개변수만을 사용하여, 마치 함수를 호출하는 것처럼 사용할 수 있다. ex) boo.invoke(bar) → boo(bar)
•
invoke 관례를 활용하면 람다 본문을 유연하게 사용할 수 있다. 람다 본문이 복잡할 경우, 인터페이스를 구현하는 방향으로 람다를 분리할 수 있다. 이하 예제의 경우, 함수 타입((Issue) → Boolean)의 인터페이스를 구현하는 클래스를 정의하고, 람다의 복잡한 식을 클래스의 두 가지 메소드로 분리했다.
•
단, invoke 관례를 일상적으로 사용하면 오히려 가독성이 떨어질 수 있다.
fun main() {
val issues = listOf(
Issue("1", "High", "Bug", "OCP"),
Issue("2", "Major", "Bug", "OCS"),
Issue("3", "Low", "Feature", "OCS"),
Issue("4", "High", "Normal", "OCS"),
)
val importantIssues = issues.filter { issue ->
issue.type == "Bug" && issue.team == "OCP" &&
(issue.priority == "High" || issue.priority == "Major")
}
importantIssues.forEach { println(it.id) }
}
data class Issue(val id: String, val priority: String, val type: String, val team: String)
Kotlin
복사
// invoke 관례 활용
fun main() {
val issues = listOf(
Issue("1", "High", "Bug", "OCP"),
Issue("2", "Major", "Bug", "OCS"),
Issue("3", "Low", "Feature", "OCS"),
Issue("4", "High", "Normal", "OCS"),
)
val predicate = ImportantAndBugIssuePredicate(team = "OCP")
val importantBugIssues = issues.filter(predicate)
importantBugIssues.forEach { println(it.id) }
}
class ImportantAndBugIssuePredicate(
private val team: String,
) : (Issue) -> Boolean {
override operator fun invoke(issue: Issue): Boolean {
return issue.team == team && issue.isImportant() && issue.isBug()
}
private fun Issue.isBug(): Boolean {
return type == "Bug"
}
private fun Issue.isImportant(): Boolean {
return priority == "High" || priority == "Major"
}
}
data class Issue(val id: String, val priority: String, val type: String, val team: String)
Kotlin
복사
4) 중위함수 호출 연쇄
•
기초 문법: 중위함수란 수신객체와 하나의 매개변수가 존재할 경우, 간편하게 호출하도록 정의한 함수이다.
•
중위함수 호출 연쇄를 활용하여 마치 영어 문장을 읽는 것과 유사한 수준의 가독성을 가질 수 있다.
// 중위 함수 정의
infix fun Int.add(other: Int): Int {
return this + other
}
// 중위 함수 호출
val result = 1 add 2
println("Result is $result") // 출력 결과: Result is 3
Kotlin
복사
다. 코틀린 DSL 활용
1) Gradle 의존관계 정의(invoke 관례 활용)
•
Gradle에서 특정 설정의 항목이 한 두 개 뿐일 경우, ‘전통 API 호출 방식’ 활용하고, 설정 항목이 많을 경우 ‘중첩된 블록 구조’를 사용할 수 있다.
•
invoke 관례를 활용하여 중첩된 블록 구조를 간단하게 만들 수 있다.
val dependencies = DependencyHandler()
dependencies.compile("io.kotest:kotest-runner-junit5")
dependencies {
compile("io.kotest:kotest-runner-junit5")
compile("io.kotest:kotest-assertions-core")
compile("io.kotest:kotest-property")
}
// 위의 invoke 관례의 변환 결과
// dependencies.invoke({
// this.compile("io.kotest:kotest-runner-junit5")
// this.compile("io.kotest:kotest-assertions-core")
// this.compile("io.kotest:kotest-property")
// })
class DependencyHandler {
fun compile(coordinate: String) {
println("~~")
}
operator fun invoke(body: DependencyHandler.() -> Unit) {
this.body()
}
}
Kotlin
복사
2) Kotest 내부 DSL(중위함수 호출 연쇄 활용)
•
Kotest 내 중위 함수(should, with)를 연쇄적으로 호출했다.
•
중위함수 호출 연쇄가 가능한 이유는 should 함수가 with이라는 함수를 호출 할 수 있는 래퍼 객체를 반환하기 때문이다.
// 중위 함수 호출 연쇄
"kotlin" should start with "kot"
// 일반 함수 호출 연쇄
"kotlin".should(start).with("kot")
object start
infix fun String.should(x: start): StratWrapper = StartWrapper(this)
class StartWrapper(val value: String) {
infix fun with(prefix: String) = // ...
}
Kotlin
복사
3) 날짜 처리(확장함수 호출 연쇄 활용)
•
확장함수 호출 연쇄를 활용하면 원시 타입을 보다 읽기 쉽게 정의할 수 있다.
•
특히, Kotest의 중위함수 호출 연쇄와 함께 사용하면 테스트 검증문의 가독성이 높은 수준으로 향상된다.
class MobileTokenUnitTest : FunSpec({
lateinit var authCode: MobileAuthCode
beforeEach {
authCode = TestDataUtils.createAuthCode()
}
test("인증코드 생성 후 20분이 되면 만료된다") {
authCode shouldBeExpired 20.minutes.fromNow
}
test("인증코드 생성 후 20분 이후에는 만료된다") {
authCode shouldBeExpired 21.minutes.fromNow
}
test("인증코드 생성 후 20분 이전에는 만료되지 않는다") {
authCode shouldNotBeExpired 19.minutes.fromNow
}
})
infix fun MobileAuthCode.shouldBeExpired(fromNow: LocalDateTime) {
this.expiredAt shouldBe lt(fromNow)
}
infix fun MobileAuthCode.shouldNotBeExpired(fromNow: LocalDateTime) {
this.expiredAt shouldNotBe lt(fromNow)
}
val Int.minutes: Duration
get() = Duration.ofMinutes(this.toLong())
val Duration.fromNow: LocalDateTime
get() = LocalDateTime.now() + this
Kotlin
복사
4) Exposed 내부 DSL(멤버 확장 함수 활용)
•
멤버 확장: 클래스 내부에서 확장 함수 또는 확장 속성을 정의하는 것이다.
•
멤버 확장을 사용하게 되면 메소드가 적용되는 범위를 제한할 수 있다. 다시 말해, 멤버 확장의 핵심은 확장 함수의 사용 맥락을 제어하는 것이다.
•
메소드 적용 범위 제한: 이하 예시 코드에서 3번, 4번과 같이 멤버 확장을 사용할 수 없다.
•
수신 객체 타입 제한: 이하 예시 코드에서 2번과 같이 멤버 확장을 사용할 수 없다.
class Column<T>
class Table {
fun integer(name: String): Column<Int> { TODO() }
fun varchar(name: String, length: Int): Column<String> { TODO() }
fun <T> Column<T>.primaryKey(): Column<T> { TODO() }
fun Column<Int>.autoIncrement(): Column<Int> { TODO() }
val id = integer("id").autoIncrement().primaryKey() // 1번
// val id = varchar("id").autoIncrement().primaryKey() // 2번
}
fun main() {
// val id = integer("id").autoIncrement().primaryKey() // 3번
// val id = Table().integer("id").autoIncrement().primaryKey() // 4번
}
Kotlin
복사
5. Kotlin Basic
가. 클래스
1) property vs field, accessor method
•
코틀린의 property는 자바의 field와 accessor method(getter, setter)가 엮인 기능이다.
2) custom accessor method
•
get()을 오버라이딩해서 정의할 수 있다.
나. 스마트 캐스트와 타입
1) 정의
스마트 캐스트란 타입 검사, 타입 캐스트, 타입 강제 변환이 엮인 기능이다.
- 본문 중
2) 스마트 캐스트 적용의 전제조건
•
val로 정의되고 커스텀 접근자가 정의되지 않은 변수
: var로 정의된 변수는 변경 가능성이 있기 때문에 스마트 캐스트가 적용될 수 없다.
: val로 정의된 변수일지라도 커스텀 접근자가 정의되었다면 반환 타입의 변경 가능성이 있다.
3) 명시적 타입 캐스팅 ‘as’
•
as 키워드를 활용하면 명시적으로 타입을 지정할 수 있다.
val TotalNumber = input as Num
Kotlin
복사
4) 타입 검사 ‘is’
5) java final vs kotlin val
•
java final은 변수 선언 시 값 입력 필요, kotlin val은 선언 시 타입만 지정해주면 추후에 값 입력할 수 있음
6) 코틀린 널 타입 체크
•
자바에서는 NullPointException이 런타임 시점에 확인가능
•
코틀린에서는 널 타입 도입에 다라 NullPointException을 컴파일 시점에 확인 가능
다. Expression vs Statement
1) 정의
•
Expression(식) ‘값’을 평가하고 반환한다.
•
Statement(문)은 값을 제어하여 ‘함수’를 호출한다.
2) If Conditiion
•
Java의 if는 일반적으로 문(Statement)으로 사용되며, 괄호 안에서 연산을 제어하고 값을 반환하지 않는다. 단, Java의 삼항 연산자는 예외적으로 if를 식(Expression)으로 사용한다. 반면 Kotlin의 if는 식(Expression)으로 결과에 따라 값을 반환한다.
// if condition의 연산 결과에 따라
// x or y의 값을 반환한다.
val z = if (x > y) x else y
Kotlin
복사
// if condition의 연산 결과(true or false)에 따라
// 이하의 출력문의 호출여부를 제어한다.
if (x > 0) {
System.out.println("x is positive");
}
// 예외
int y = x > 0 ? 1 : -1;
Java
복사
라. Java switch vs Kotlin when
1) Kotlin의 when이 강력한 이유
•
when의 분기조건에 상수 뿐만이 아니라 임의의 객체를 적용할 수 있다. 임의의 객체에는 Expr 타입의 인터페이스도 포함되기 때문에 when의 분기 조건을 간략하게 표현할 수 있다. 참고로 Expr 타입

마. 반복문
1) in 활용
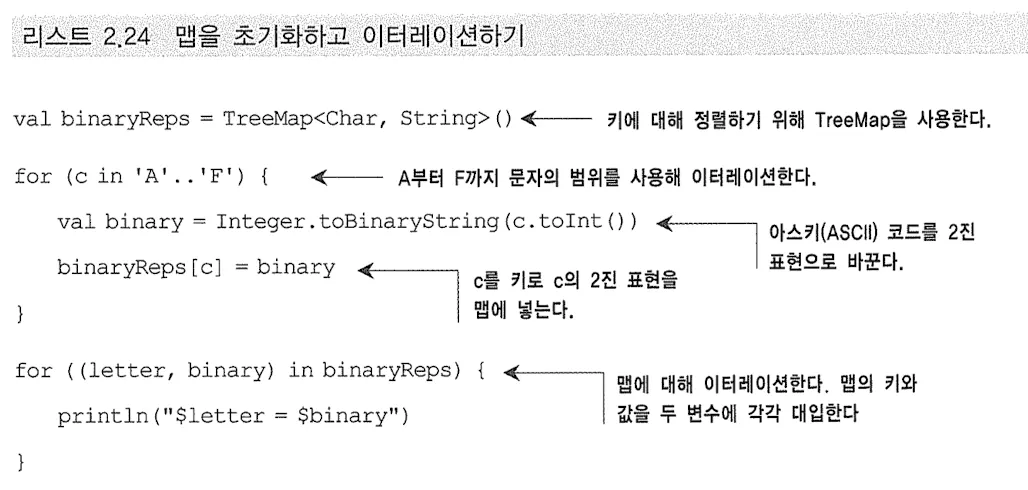
•
Map의 key와 value의 요소에 대해 순회할 수 있다.
•
in과 !in을 활용하여 범위 또는 컬렉션 내 요소 검사를 할 수 있다.

2) .. vs until
•
.. 연산자는 양쪽 값을 포함한다
1..10: 1~ 10
•
until은 오른쪽 끝 값을 포함하지 않는다
1 until 10: 1 ~ 9
바. 예외 처리
1) rethrow
•
함수 선언부에 throws를 정의할 필요가 없다. 예외가 발생하면 해당 예외를 처리하는 로직이 나올 때까지 해당 예외를 호출한 객체로 계속 throw한다.
2) try ~ catch도 식이다
•
try catch가 식이기 때문에 메소드 시그니처에 바로 이어서 정의할 수 있다.
•
val num = test ?: throw Exception
3) 자바의 try with resource 대체 방법
•
kotlin에서 확장함수 use를 사용하여 위의 자바 문법을 대체할 수 있다.
4) checked exception vs unchecked exception
•
kotlin에서는 exception을 컴파일 타임에 체크하지 않기 때문에 checked exception과 unchecked exception을 구분할 필요가 없다.
Java의 예외 처리
Java에서는 두 가지 유형의 예외가 있습니다: Checked Exception과 Unchecked Exception.
1. Checked Exception: 이 예외는 컴파일 타임에 체크되며, 개발자가 이를 명시적으로 처리하도록 강제합니다. 예를 들어, IOException은 Checked Exception에 해당합니다. 이러한 예외는 try-catch 블록을 사용하거나 throws 키워드를 통해 메소드 시그니처에 선언하여 처리해야 합니다.
2. Unchecked Exception: RuntimeException과 그 서브 클래스는 Unchecked Exception에 해당하며, 이들은 컴파일 타임에 강제되지 않습니다. 즉, 개발자가 명시적으로 이를 처리하지 않아도 컴파일 에러가 발생하지 않습니다.
---
Kotlin의 예외 처리
Kotlin에서는 Checked Exception과 Unchecked Exception의 구분이 없습니다. 모든 예외는 기본적으로 Unchecked로 취급됩니다.
• 예외 처리의 간소화: Kotlin은 Java와 달리 Checked Exception을 명시적으로 처리하도록 강제하지 않습니다. 따라서, 개발자는 try-catch 블록을 사용하여 예외를 처리할 수도 있고, 아니면 전혀 처리하지 않을 수도 있습니다.
• 유연성 증가: 이 접근 방식은 코드의 유연성을 증가시키고, 과도한 예외 선언으로 인한 코드의 복잡성을 감소시킵니다.
비교 및 결론
• Java: Checked Exception을 통해 더 엄격한 에러 처리를 강제하지만, 이로 인해 코드가 더 복잡해질 수 있습니다. 또한, 예외 처리를 강제함으로써 개발자가 예외에 더 주의를 기울이도록 유도합니다.
• Kotlin: 모든 예외를 Unchecked로 취급함으로써 개발자에게 더 많은 유연성을 제공합니다. 이는 코드를 더 간결하고 읽기 쉽게 만들지만, 예외 처리에 대한 개발자의 주의가 필요합니다.
Plain Text
복사
사. Generic
1) Type Safe
•
컴파일 타임에서 타입 체크를 한다.
•
List<T> vs List<Any?>: Any?의 경우 타입 체크를 하지 않기 때문에 타입 세이프하지 않음
2) 타입 제약
•
Nullable이 가능하기 때문에 Nullable아니라는 것을 명시해야 함 ex) List<Any>
3) 스웨거 타입 휘발
•
제네릭을 사용하면 스웨거 문서에 타입 정보가 입력되지 않음. 컴파일 타임에 타입이 결정되기 때문이지.
Reference
•
드미트리 제메로프, 스베트라나 이사코바 - Kotlin IN ACTION