1. 학습 성과

본서 완독 후 테스트 설계 역량과 도메인 중심의 리팩토링 역량 향상
가. 저비용 고가치 테스트 설계 역량 향상
1) after refactoring
•
테스트 케이스 간 격리 조건 충족, 제품 코드에서 외부 의존성을 오케스트레이션으로 이전했기 때문에 테스트를 병렬적으로 실행해도 테스트 케이스 간 간섭은 발생하지 않는다.
•
테스트 코드 가독성 향상, 검증 대상 값과 예상 값을 단순화하여 테스트 코드의 가독성을 높였다.
•
테스트 설명과 구현의 분리, 테스트의 설명을 검증 중심으로 추상화했기 때문에 제품 코드 내 수정이 발생해도 테스트 설명에 대한 추가적인 수정은 발생하지 않는다.
참고) 개선된 코드
class OrderUnitTest : DescribeSpec({
isolationMode = IsolationMode.InstancePerLeaf
describe("주문 시") {
context("주문금액이 5만원 이상이라면") {
val calculator = PriceCalculator()
val orderData = createOrderData(
itemPrice = BigDecimal.valueOf(45000),
itemName = "123테이블", stockQuantity = 7, orderQuantity = 2
)
val sut = Order()
val result = sut.createWith(orderData, calculator)
it("주문금액에 배송료를 포함하지 않는다") {
result.price shouldBe BigDecimal.valueOf(90000)
}
}
})
Kotlin
복사
2) before refactoring
•
테스트 간 격리 위배, 외부 의존성(DB)과 결합된 테스트 환경이기 때문에 테스트를 병렬적으로 실행하면 테스트 간 간섭이 발생한다.
•
낮은 수준의 코드 가독성, 검증 대상 값과 예상 값이 쉽게 읽히지 않는다.
•
테스트 설명과 구현의 결합, OrderService::order의 이름이 변경되면 테스트 설명에 포함된 ‘order 메소드’의 표현도 수정해야 한다.
참고) 리팩토링 전 코드
@DataJpaTest
class OrderClassicalDslTest(
@Autowired private val orderRepository: OrderRepository,
@Autowired private val orderItemRepository: OrderItemRepository,
@Autowired private val itemRepository: ItemRepository,
) : DescribeSpec() {
override fun extensions() = listOf(SpringExtension)
private var orderQuantity: Int = 0
private val itemPrice: BigDecimal = BigDecimal.valueOf(45000)
private val deliveryFee: BigDecimal = BigDecimal.valueOf(2500)
private val stockQuantity: Int = 7
private val itemId: Long = 7722L
beforeTest {
orderData.clear()
service = OrderService(orderRepository, itemRepository, orderItemRepository)
}
describe("order 메소드는") {
context("만약 주문금액이 5만원 이상이면") {
beforeTest {
orderQuantity = 2
}
it("주문금액에 배송료를 포함하지 않고 반환한다") {
orderData.add(OrderData(itemId, orderQuantity))
val order = service.order(orderData)
val actualPrice = order.price
val expectedPrice = itemPrice.multiply(BigDecimal.valueOf(orderQuantity.toLong()))
val actualStockQuantity = itemRepository.findByIdInLock(itemId).stockQuantity
val expectedStockQuantity = stockQuantity - orderQuantity
actualPrice shouldBe expectedPrice
actualStockQuantity shouldBe expectedStockQuantity
}
}
}
Kotlin
복사
나. 도메인 중심의 리팩토링 역량 향상
1) after refactoring
•
오케스트레이션 로직과 비지니스 로직의 분리, 비지니스 의사결정에 대한 로직을 모두 도메인 객체로 이전했고, 오케스트레이션 로직에는 의사결정 결과를 외부 의존성과 협력하는 로직만 남겼다.
•
불필요한 레파지토리 제거, ORM의 영속성 전이(CASCADE)를 활용하여 불필요한 레파지토리를 제거했다.
•
불필요한 인터페이스 제거, 구현체가 하나이자 추상화 가능성이 없는 오케스트레이션 로직에서 인터페이스를 제거했다.
참고) 개선된 코드
@Service
@Transactional
class OrderService(
private val orderRepository: OrderRepository,
private val itemRepository: ItemRepository,
) {
fun order(orderData: OrderData): OrderResult {
val order = Order()
val calculator = PriceCalculator()
val item: Item = itemRepository.findByIdInLock(orderData.itemId)
orderData.item = item
val result = order.createWith(orderData, calculator)
itemRepository.save(item)
orderRepository.save(Order(null, result.price, result.orderItems.toMutableList()))
return result
}
}
@Entity
@Table(name = "order_table")
class Order(
// 생략
) {
fun createWith(orderData: OrderData, calculator: PriceCalculator): OrderResult {
val item = orderData.item
var totalPrice = BigDecimal.ZERO
totalPrice = calculator.totalPriceWith(totalPrice, item!!.price, orderData.orderQuantity)
try {
item.decreaseStock(orderData.orderQuantity)
} catch (e: SoldOutException) {
return OrderResult(false, totalPrice, arrayListOf())
}
this.updateOrderPriceBy(totalPrice)
return OrderResult(true, this.price, arrayListOf())
}
}
Kotlin
복사
2) before refactoring
•
오케스트레이션 로직과 비지니스 로직의 결합, 오케스트레이션 로직에 비지니스 의사결정이 모두 들어가 있다.
•
불필요한 레파지토리 사용, ORM 활용에 따라 생략할 수 있는 외부 의존성이 오케스트레이션 로직과 결합되어 있다.
•
불필요한 인터페이스 사용, 구현체가 하나이자 추상화 가능성이 없는 오케스트레이션 로직에 인터페이스를 사용했다.
참고) 리팩토링 전 코드
@Service
@Transactional
class OrderService(
private val orderRepository: OrderRepository,
private val itemRepository: ItemRepository,
private val orderItemRepository: OrderItemRepository,
) : OrderLogic<Order, OrderData> {
override fun order(orderData: List<OrderData>): Order {
val order = Order()
val orderItems: ArrayList<OrderItem> = ArrayList()
var totalPrice = BigDecimal.ZERO
for (each in orderData) {
val item: Item = itemRepository.findByIdInLock(each.itemId)
val orderItem = OrderItem(order, item, each.itemQuantity)
if (each.itemQuantity > item.stockQuantity) {
throw SoldOutException(soldOutMessage)
}
item.decreaseStock(each.itemQuantity)
orderItems.add(orderItem)
val priceSum = each.itemQuantity.times(item.price.toLong())
totalPrice += BigDecimal.valueOf(priceSum)
itemRepository.save(item)
}
this.addDeliveryFeeByAmountLimit(freeDeliveryLimit, order, totalPrice, deliveryFee)
this.saveOrder(order, orderItems)
return order
}
private fun saveOrder(
order: Order,
orderItems: List<OrderItem>
) {
orderRepository.save(order)
for (each in orderItems) {
orderItemRepository.save(each)
}
}
}
Kotlin
복사
2. 단위 테스트의 목표는?
테스트의 목표는 회귀 방지에 따라 소프트웨어의 지속 가능한 성장을 지원하는 것이다. 저비용 고가치의 단위 테스트만 남기면 테스트의 목표를 효율적으로 달성할 수 있다.
가. 고가치 테스트
1) 가치 있는 테스트 작성
•
가치 있는 테스트를 작성하기 위해서는 가치 있는 ‘코드 베이스’가 전제되어야 한다. 대표적인 예가 ‘비지니스 로직’에서 다른 레이어의 코드를 분리하는 것이다. 오직 ‘비지니스 로직’만을 대상으로 테스트가 작성되면 테스트는 간결한 모양을 유지하므로 가독성이 높아진다. 더불어 다른 레이어에 의존성이 낮아지므로 변경 가능성이 최소화 되어 유지보수성면에서 최적화된다.
•
가치 있는 테스트를 식별하기 위한 ‘틀’ 또는 ‘기준’이 필요한데 관련 내용은 4장에서 다룬다.
2) 커버리지 지표는 ‘부정 지표’로 활용
•
커버리지는 부정 지표(‘60% 미만’ 기피)로 적용해야 한다. 긍정지표(‘90% 이상’ 달성)로 적용하면 부작용이 크다. 그 이유는 해당 지표가 테스트의 질을 대변하지 않음에도 이를 달성하기 위해 불필요한 자원이 허비되기 때문이다. 참고로 커버리지 지표 중 ‘코드 커버리지’ 보다 ‘분기 커버리지’가 그나마 테스트의 질을 측정하는 면에서 낫다. ‘코드 커버리지’는 코드 라인의 ‘코드 양적 비교’인 반면, ‘분기 커버리지’는 분기 처리되는 로직이 테스트에서 다뤄지는 지를 비교한다.
나. 저비용 테스트
1) ‘비지니스 로직’ 외에는 간소화된 테스트 작성 고려
•
모든 로직에 단위 테스트를 작성하면 너무 많은 비용이 든다. 단위 테스트는 ‘비지니스 로직’과 같이 중요도가 높은 로직을 대상으로 집중적으로 작성해야 한다. 중요도가 비교적으로 떨어지는 로직에는 ‘통합 테스트’로 간접 테스트하는 것을 권장한다.
2) 불필요한 테스트 버리기
•
코드는 자산이 아니라 부채다. 개발자의 인지능력에는 한계가 있기 때문에 코드가 많아지면 인지 범위에서 벗어난다. 따라서 가치 있는 테스트를 식별하는 기준을 만들고 이에 미달하는 테스트가 있다면 과감히 버려야 한다.
•
테스트 코드는 제품 코드에 의존할 수 밖에 없으므로 제품 코드 리팩터링 시 테스트 코드도 함께 리팩터링해야 한다. 코드 작업에 드는 비용을 최소화하기 위해 가치가 낮은 테스트는 제거해야 한다.
다. 기타 질문
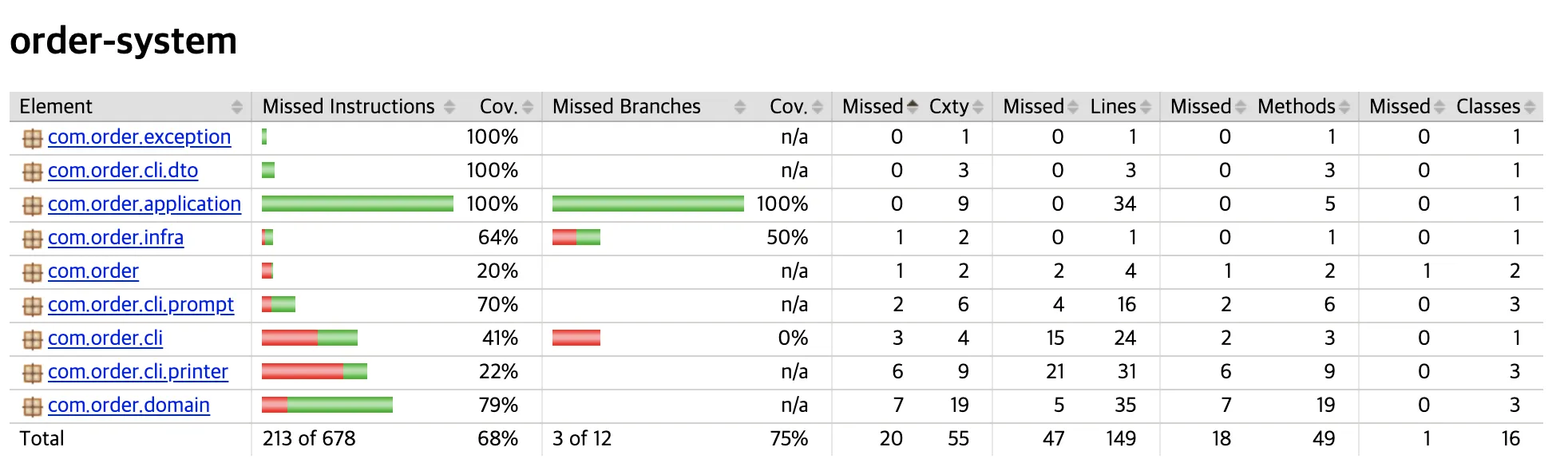
1) 스프링 환경에서 분기 커버리지를 확인하는 방법은?
•
JaCoCo 활용하면 분기 커버리지를 간편하게 확인할 수 있다. 관련 의존성 설정 후 이하 명령에 따라 분기(Branch) 대비 테스트 케이스 비율을 확인할 수 있다.
•
리포트 생성 및 커버리지 확인 명령: ./gradlew --console verbose test jacocoTestReport jacocoTestCoverageVerification
•
분기 커버리지 확인 결과
2) 회귀(Regression)라는 용어의 의미는?
회귀는 특정 사건(일반적으로 코드 수정) 후에 기능이 의도한 대로 작동하지 않는 경우다. 소프트웨어 버그와 회귀라는 용어는 동의어이며 바꿔서 사용할 수 있다.
- 본문 중
•
위키피디아에 따르면 회귀는 코드 수정 후 과거에 해결됐던 문제(더 넓게 해석하면 새로운 문제)가 다시 발생하는 것을 말한다. 회귀라는 단어는 돌아간다는 뜻인데, 본문의 설명은 충분하지 못하여 위키피디아를 참고하여 보충했다.
3. 테스트에 대한 고전파와 런던파의 차이는?
고전파: 단일 동작 단위 검증, 다른 테스트 케이스와 격리, 의존성 상태 변화 검증 ..
런던파: 클래스 단위 검증, 대부분의 의존성 격리, Mock 객체와의 상호작용 검증 ..
가. 단위 테스트의 단위
1) 고전파: 유의미한 단일 동작
•
유의미한 단일 동작을 구성하는 ‘클래스 집합’을 대상으로 단위 테스트를 구성한다. 만약 하나의 클래스만으로 유의미한 단일 동작을 구성한다면 하나의 클래스가 단위테스트의 대상이 된다. 유의미한 단일 동작을 구성하는 클래스가 여러 개일 경우, 단위 테스트 케이스를 줄일 수 있으므로 테스트 유지보수면에서 이점이 있다.
2) 런던파: 클래스
•
객체지향 패러다임 관점에서 유의미한 최소 단위는 클래스이므로 단위 테스트의 대상은 클래스가 되어야 한다. 단위 테스트의 대상이 명확하게 떨어지므로 테스트 설계의 편리성면에서 이점이 있다.
나. 단위 테스트의 격리 대상
1) 고전파: 단위 테스트 간 격리
•
테스트 결과의 독립성을 보장하기 위해 단위 테스트 간 격리 설정이 필요하다. 이를 위해 공유 의존성에는 테스트 대역을 사용해야 한다. 공유 의존성에 테스트 대역을 사용하는 이유에는 두 가지가 더 있다.
•
하나, 단위 테스트의 실행 속도를 향상시킬 수 있기 때문이다. 특히 공유 의존성의 상당수가 프로세스 외부 의존성인데, 이를 제거하면 테스트 속도를 향상시킬 수 있다. 또 다른 이유는 설계 변경의 기회를 얻을 수 있기 때문이다. 테스트 환경에서 의존성 그래프를 직접 설정하기 때문에 의존성이 복잡하게 얽혔다면 문제 의식을 느끼고 설계를 변경할 수 있는 계기가 된다.
2) 런던파: 대부분의 의존성 격리
•
SUT 내부 로직만을 대상으로 검증하기 위해 대부분의 의존성에 대한 격리 설정이 필요하다. 이를 위해 불변 객체를 제외한 대부분의 의존성에 대해 테스트 대역을 사용하여 테스트 환경을 구축한다. 불변 객체의 예로, ENUM, Value Object, 상수 등을 들 수 있다. 만약 상용 로직의 의존성 그래프가 복잡하다면 이를 테스트 대역으로 대체하기 때문에 의존성 그래프 설정에 드는 비용이 상대적으로 저렴하다.
다. 단위 테스트 검증 대상
1) 고전파: SUT 반환 결과 + 협력자 상태 변화
•
SUT 반환 결과를 검증하는 것 외에 협력자의 상태 변화를 검증한다. 이하의 예시 코드를 보면 Item 엔티티의 stockQuantity의 상태변화를 추가적으로 검증하는 로직이 존재한다.
•
예시 코드: 코드 전체는 다음의 링크 참고
describe("order 메소드는") {
context("만약 주문금액이 5만원 이상이면") {
beforeTest {
orderQuantity = 2
}
it("주문금액에 배송료를 포함하지 않고 반환한다") {
orderData.add(OrderData(itemId, orderQuantity))
val order = service.order(orderData)
val actualPrice = order.price
val expectedPrice = itemPrice.multiply(BigDecimal.valueOf(orderQuantity.toLong()))
val actualStockQuantity = itemRepository.findByIdInLock(itemId).stockQuantity
val expectedStockQuantity = stockQuantity - orderQuantity
actualPrice shouldBe expectedPrice
actualStockQuantity shouldBe expectedStockQuantity
}
}
Kotlin
복사
2) 런던파: SUT 반환 결과 + SUT와 협력자의 상호작용
•
SUT 반환 결과 외 Mock으로 대체한 협력자와의 상호작용을 확인한다. 이하의 코드를 보면 OrderService::order 내부에서 ItemRepository::findByIdInLock의 호출 빈도를 확인한다.
•
예시 코드: 코드 전체는 다음의 링크 참고
beforeTest {
every { itemRepository.findByIdInLock(itemId) } returns item
every { itemRepository.save(any()) } returns item
every { orderRepository.save(any()) } returns order
every { orderItemRepository.save(any()) } returns OrderItem(null, order, item, orderQuantity)
}
describe("order 메소드는") {
context("만약 주문금액이 5만원 이상이면") {
beforeTest {
orderQuantity = 2
}
it("주문금액에 배송료를 포함하지 않고 반환한다") {
orderData.add(OrderData(itemId, orderQuantity))
val order = service.order(orderData)
val actualPrice = order.price
val expectedPrice = itemPrice.multiply(BigDecimal.valueOf(orderQuantity.toLong()))
actualPrice shouldBe expectedPrice
verify(exactly = 1) { itemRepository.findByIdInLock(itemId) }
}
}
Kotlin
복사
라. 통합 테스트 정의
1) 고전파: 단위 테스트의 세 가지 속성 중 하나라도 만족하지 않는 테스트
단위 테스트는
단일 동작 단위를 검증하고,
빠르게 수행하고,
다른 테스트와 별도로 처리한다.
- 본문 중
•
고전파 스타일의 통합 테스트는 단위 테스트의 세 가지 속성 중 하나라도 만족하지 않는 모든 테스트다. 다시 말해, 둘 이상의 동작 단위 대상의 테스트는 통합 테스트다. 외부 의존성 사용하여 느리게 실행되고, 테스트 케이스 간 결과의 독립성을 보장 받지 못하는 것도 통합 테스트다.
2) 런던파: 실제 객체를 협력자로 사용하는 테스트
•
런던파 스타일의 통합 테스트는 협력자에 실제 객체를 사용한다. 반면 단위 테스트는 협력자를 Mock으로 대체한다. 런던파 입장에서 고전파의 단위 테스트 일부는 통합 테스트로 볼 수 있다. 통합 테스트에 대한 구체적인 내용은 ‘3부 통합테스트’를 참고하시라.
마. TDD 설계 방식
1) 고전파: 상향식 TDD
•
대부분의 의존성에 대해 실제 객체를 사용하는 만큼 도메인 모델부터 윗 계층으로 테스트를 작성하는 방향으로 개발한다.
2) 런던파: 하향식 TDD
•
전체 시스템의 의존성 설계 후, 상위 계층의 클래스에 대한 단위테스트를 기반으로 개발한다. 설계 단계에서 작성된 의존성의 인터페이스를 바탕으로 Mocking하여 윗 계층에서부터 아래 계층의 방향으로 테스트하며 개발한다.
바. 용어 정리
1) SUT vs 협력자
•
SUT(System Under Test, 테스트 대상 시스템)는 단위 테스트의 대상이다. 런던파 입장에서 테스트 대상의 단위는 단일 클래스이므로 SUT는 테스트 대상 단일 클래스에 해당한다. MUT(Method Under Test, 테스트 대상 메소드)는 SUT에서 호출하는 메소드이다.
•
협력자는 테스트 대상의 의존성 중 공유 또는 변경이 가능한 것이다.
2) 테스트 대역 vs 협력자
•
테스트 대역(Test Double)은 모든 종류의 가짜 의존성이다. 목(Mock)은 테스트 대역의 부분집합으로, SUT와 협력자의 상호관계에 대한 테스트 대역으로 이해할 수 있다. 구체적인 내용은 5장을 참고하시라. 목을 만들 때는 구현체가 아니라 인터페이스를 기초로 한다. 자세한 내용은 11장 안티패턴을 참고하시라.
•
협력자는 테스트 대상의 실제 의존성이다.
3) 공유 의존성 vs 프로세스 외부 의존성
•
공유 의존성은 테스트 케이스 사이에 공유되어 테스트 결과에 영향을 줄 수 있는 의존성이다. 비공개 의존성은 테스트 케이스 사이에 공유되지 않는 의존성이다.
•
프로세스 외부 의존성은 어플리케이션 프로세스 밖에 존재하는 의존성으로, 구현 방법에 따라 테스트 케이스 간 영향을 줄 수도 있고 안 줄 수도 있다. 대부분의 프로세스 외부 의존성은 공유 의존성이다.
4) 의존성 vs 협력자 vs 값
•
의존성은 협력자와 값으로 구분한다. 협력자는 공유하거나 변경 가능한 의존성이다. 반면 값은 불변성이 있는 의존성(불변 객체)이다. ENUM, Value Object, 상수 등이 대표적인 예이다.
5) 객체 그래프
•
객체 그래프(=의존성 그래프)는 대상 클래스가 의존하고 있는 클래스와 의존 클래스가 의존하고 있는 클래스들의 관계를 그래프의 형태로 표현한 것이다.
사. 기타 질문
1) 고전파 스타일로 단위 테스트 구성 시 Spring의 Repository 컴포넌트는 ‘공유 의존성’으로 보고 Mocking해야 하는가?
•
테스트 환경 설정에 따라 다르다. Repository가 DB와 직접 연관된 컴포넌트이기 때문에 프로세스 외부 의존성을 갖는 공유 의존성으로 볼 수 있다.
•
Repository에 대한 조작이 다른 테스트에 영향을 주지 않도록 환경을 설정한다면, Repository의 성격을 비공개 의존성으로 바꿀 수 있다. 예를 들어, Transactional 어노테이션을 활용하여 Repository 컴포넌트를 비공개 의존성으로 설정된다. 왜냐하면 테스트 케이스 각각이 종료될 때마다 모든 데이터 변경 사항이 Rollback되기 때문이다.
•
DataJpaTest 어노테이션을 적용하면 테스트를 빠르게 실행할 수 있다. 그 이유는 자체 in-memory DB를 구축하여 사용하기 때문에 Disk I/O 지연을 피할 수 있기 때문이다. 참고로 DataJpaTest 어노테이션 내부에 Transactional 어노테이션이 포함되어 있다.
•
테스트를 순차적으로 실행한다는 전제가 추가되어야 ‘비공개 의존성’으로 볼 수 있다. 위와 같이 설정해도 Spring의 Repository 컴포넌트는 ‘공유 의존성’이다. 만약 테스트가 많이 축적되었다면 병렬로 실행할 경우도 존재한다. 테스트가 병렬로 실행된다면 아무리 롤백되더라도 테스트 케이스간 간섭이 일어날 수 있다.
2) 비지니스 로직을 테스트할 때, Spring의 Repository에 대한 의존성을 제거하고 간단하게 테스트할 수 있는 방법이 있는가?
•
DDD가 대안이다. DDD에 따르면 계층별로 비지니스 로직이 포함된 클래스를 별도로 생성하는 것을 권장한다. 만약 주문이라는 비지니스 로직을 다룰 때, OrderService 내부의 핵심 비지니스 로직을 Order 도메인 계층에 정의할 수 있다. 그렇게 되면 해당 도메인 계층의 비지니스 로직은 Repository 계층과 결합되어 있지 않기 때문에 위와 같은 질문에 대한 답이 될 수 있다.
4. 테스트 구조의 Best Practice는?
테스트 구조를 간결하게 유지하여 유지비용을 낮추기 위해 테스트 패턴, 가독성 높은 명명법, 매개변수 활용을 권장한다.
가. AAA 패턴
1) 3A(Arrange, Act, Assert) 패턴 구조
•
준비 단계를 앞에 두고 실행과 검증 부분을 묶으면 가독성 면에서 이점이 있다. 준비 단계가 실행과 검증 부분을 합친 것 보다 더 크다면 별도의 팩토리 메소드를 활용할 것을 권장한다. 자세한 내용은 10장의 Object Mother과 Test Data Builder의 내용을 참고하시라.
2) 검증 간소화
•
테스트 검증 객체에 대해 동등성(equality)을 확인할 수 있는 객체를 준비하는 것을 권장한다. 특히 검증 대상 객체 내 필드를 하나하나 테스트해야 할 경우, 객체 간 동등성을 확인한다면 가독성이 큰 폭으로 향상된다.
3) SUT 인스턴스를 sut로 명명
•
고전파 입장에서 SUT는 복수의 클래스의 집합으로 볼 수 있다. 따라서 어떤 객체가 SUT에 해당되는지를 확인하는 시간을 줄이기 위해 해당 인스턴스 객체의 이름을 sut로 지정하는 것을 권장한다.
4) AAA 요소 간 구분은 주석 대신 빈 줄
•
패턴을 따른다면 빈 줄만으로도 요소 간 구분이 가능하다. 복잡한 준비(Arrange) 과정이 필요한 통합 테스트의 경우 주석을 활용할 필요가 있다.
5) fixture에 private factory method 활용
테스트 픽스처란 테스트 실행 대상 객체로, SUT로 전달된다. 픽스처는 각 테스트 실행 전에 고정(fix)한 상태로 유지하기 때문에 동일한 결과를 생성한다.
- 본문 중
•
픽스처를 생성자로 활용하는 것은 안티패턴이다.
6) 캡슐화된 단일 동작 대상 검증
•
검증 대상은 한 문장으로 간결하게 작성하는 것이 바람직하다.
나. 가독성 높은 명명법
1) 유의미한 동작 중심으로 명명
•
테스트 이름만으로 비개발자 도메인 전문가에게 충분히 전달할 수 있어야 한다. 하나의 테스트 케이스는 하나의 시나리오가 되어야 한다.
2) 사람 친화적 이름
•
테스트 케이스의 이름이 하나의 완벽한 문장에 가까운 것이 바람직하다. 이를 지원하는 테스트 프레임워크를 활용하는 것을 권장한다.
3) 불필요한 단어 제거
•
테스트의 검증 대상이 유의미한 동작이라면 SUT의 호출 메소드가 테스트 이름에 들어갈 이유는 없다. 생략 가능한 단어는 제거하는 것이 바람직하다. 예를 들어, should, considered 등등은 제거 대상이 되는 단어이다.
다. 매개변수 활용
1) 매개변수화된 테스트는 부정 결과 검증에만 사용
2) 매개변수화되어 복잡도가 너무 높아진다면 사용 말라
라. 기타 질문
1) 유의미한 단일 동작으로 캡슐화한 대상을 테스트하면서도 Repository에 의존하지 않도록 구성하는 방법은?
•
도메인 엔티티 객체 간 연관관계를 유연하게 설정한 후에 도메인 중심의 비지니스 로직을 담당하는 객체를 정의해야 한다. 이렇게 정의된 객체에 대해서는 Repository에 의존하지 않고도 유의미한 단일 동작에 대해 단위 테스트를 정의하고 실행할 수 있다.
•
만약 엔티티의 연관관계를 유연하게 설정하지 못하고, 엔티티마다 Repository가 정의된다면 유의미한 비지니스 로직으로 엔티티를 묶을 수 없다.
•
예를 들어, ‘N:M 관계 Order:Item’을 Order, Item, OrderItem의 세 가지 엔티티로 나누고 각각의 Repository를 설정하면 주문이라는 유의미한 단일 동작을 도메인 중심으로 구성할 수 없다.
5. 테스트 설계의 Best Practice는?
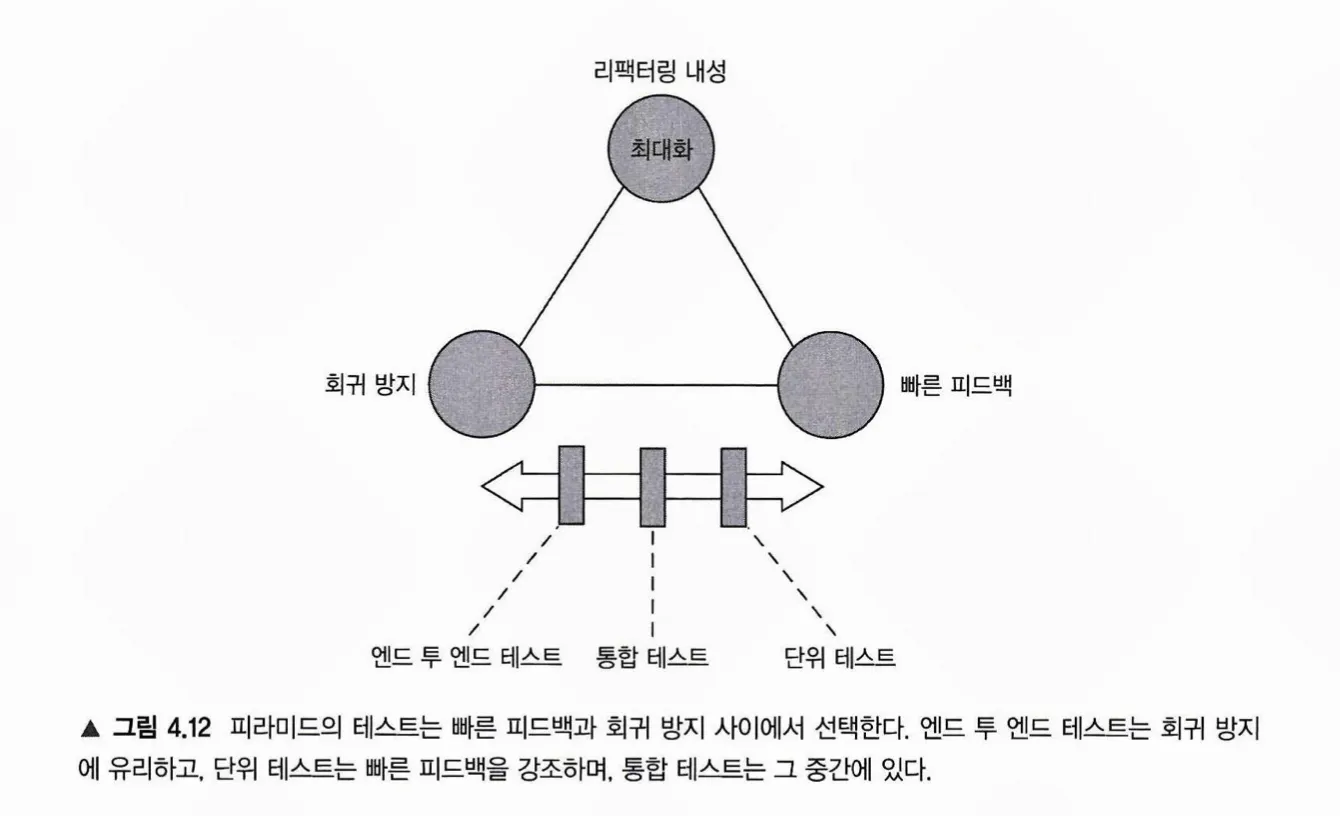
모든 테스트에서 리팩터링 내성과 유지 보수성을 필수적으로 갖춰야 한다. 단위 테스트에 회귀 방지를, e2e에는 빠른 피드백에 힘을 줘서 전체적인 균형이 맞도록 테스트를 설계해야 한다.
가. Trade Off: 회귀 방지와 빠른 피드백
1) 타협해야 하는 것: 회귀 방지와 빠른 피드백
•
테스트 설계 시 회귀 방지와 빠른 피드백은 타협의 대상이다. e2e 테스트는 회귀 방지에 탁월하지만 실행 비용이 너무 크다. 반면 단위 테스트는 실행 비용이 낮지만 회귀 방지 효과가 상대적으로 덜하다. 전체적이 비용과 효과를 고려하여 일반적으로 피라미트의 형태로 테스트를 설계하는 것이 바람직하다. 주요 비지니스 로직 전체에 대해 단위테스트를 구성해야 한다. e2e 테스트는 버그가 절대 발생하면 안되는 로직을 중심으로 일부에만 작성한다.
2) 타협할 수 없는 것: 리팩터링 내성, 유지 보수성
•
테스트 설계 시 리팩터링 내성와 유지 보수성은 타협할 수 없는 주요 요소이다. 리팩터링 내성은 회귀 방지 및 빠른 피드백과 Trade Off 관계이지만, 리팩터링 내성은 중간이 없기 때문에 테스트가 반드시 갖춰야할 요소이다. 반면 유지 보수성은 다른 요소와 Trade Off 관계가 아니기 때문에 타협의 여지 없이 반드시 갖춰야 할 요소이다.
•
리팩터링 내성을 갖추기 위해 최종 결과에 초점을 맞춰 검증해야 한다. 그리고 오직 좋은 거짓 양성만 허용해야 한다. 좋은 거짓 양성의 기준은 리팩터링에 따른 컴파일 에러 발생 유무에 있다. 만약 리팩터링에 따라 테스트 코드에 컴파일 에러가 발생한다면 좋은 거짓 양성이다. 테스트 코드를 쉽게 고칠 수 있기 때문이다. 타입 변경, 매개변수 변경이 대표적이 예이다. 하지만 컴파일 에러가 아니라 검증 대상의 값이 변경된다면 좋지 않은 거짓 양성이다. 테스트 코드를 전반적으로 수정해야 하기 때문에 테스트 유지보수 비용이 많이 든다.
•
유지 보수성은 테스트의 간결성과 실행의 편의성과 관계가 있다. 테스트 코드를 간결하고 읽기 쉽게 작성해야 한다. 시나라오 중심으로 도메인 관계자라면 쉽게 읽을 수 있는 수준으로 간결성을 보장해야 한다. 더불어 테스트의 외부 의존성 구성이 편리해야 한다. 새로운 테스트를 추가할 때마다 외부 의존성에 대한 설정이 걸림돌이 된다면 유지 보수면에서 단점이 너무 크다.
참고) 본 책의 그림 4.12
나. 테스트 비율 조정
1) 피라미드
•
비지니스 로직 중심의 단위 테스트를 가장 많이 작성한다. e2e 테스트는 버그가 절대 허용되서는 안되는 기능에 대해서만 작성한다. 통합 테스트는 그 중간에서 필요한 곳에 최소한으로 작성하는 것이 바람직하다.
2) 1:1
•
CRUD 중심의 간단한 서비스는 비지니스 로직의 복잡성이 낮기 때문에 단위 테스트와 통합 테스트의 비율을 1:1로 가져가는 것이 바람직하다. 비지니스 로직이 간단하여 단위 테스트에 대한 필요가 상대적으로 적기 때문이다.
3) 예외
•
외부 프로세스 의존성이 하나인 경우, e2e 테스트의 단점이 상쇄됨. 외부 프로세스 의존성 구성 비용을 포함한 테스트 유지비용이 낮음. 모든 통합 테스트를 외부 프로세스 의존서을 대체할 수 있음
다. 블랙박스 방식으로
1) 모든 테스트는 블랙박스로
•
리팩터링 내성은 타협할 수 없으므로 기본적으로 단위 테스트를 포함한 모든 테스트는 블랙박스 방식으로 작성되어야 한다.
2) 테스트 분석에만 화이트 박스로
•
코드 커버리지 툴을 활용해서 테스트 되지 않은 분기를 찾아내고, 해당 분기에 대해 블랙박스 방식으로 테스트를 작성하는 것이 바람직하다.
라. 용어 정리
1) 거짓 양성(False Positive)
•
허위 경보 및 1종 오류에 대한 지표이다. 리팩터링 내성을 갖춰야 거짓 양성의 발생을 극복할 수 있다.
•
프로젝트 초기에는 중요도가 상대적으로 떨어지나, 지속 유지보수에 따라 중요도가 상승한다. 시간이 지남에 따라 리팩터링에 대한 필요성이 점차 커지는데, 거짓 양성을 줄여야 원활한 리팩터링을 진행할 수 있기 때문이다. 중대형 프로젝트와 같이 요구사항의 변경이 지속적으로 발생하는 프로젝트에서 거짓 양성을 줄이기 위해 더욱 신경써야 한다.
2) 거짓 음성(False Negative)
•
알려지지 않는 버그 및 2종 오류에 대한 지표이다. 회귀 방지로 거짓 음성의 발생을 극복할 수 있다.
•
프로젝트 초기 또는 소형 프로젝트에서 중요도가 상대적으로 높다.
6. Mock에 대한 Best Practice는?
리팩터링 내성을 저해하지 않을 경우에만 Mock을 사용해야 한다.
가. Mock만 검증
1) Stub 검증은 과잉 명세
•
Stub을 검증하는 것은 리팩터링 내성을 저해하는 안티패턴이다. Stub은 SUT 내부에서 값을 반환하는 의존성에 대한 테스트 대역이기 때문에 Stub에 대한 검증은 구체적인 내부 로직과의 강결합으로 이어진다.
2) Stub이자 Mock인 테스트 대역은?
•
특정 테스트 대역이 Stub과 Mock의 역할을 동시에 수행한다면 Mock이다. 선언도 Mock으로 하고 검증도 하는 것이 바람직하다. 테스트에 있어서 Mock의 가치는 Stub의 가치 보다 높기 때문이다.
나. Mock의 적절한 사용처
1) CQS의 Command
•
CQS의 원칙을 전제한 경우, Command에 해당하는 메소드에 대해 Mock을 사용할 수 있다. 왜냐하면 Command 메소드의 호출 따른 부수효과(side effect)에 대해 추가적인 검증이 필요하기 때문이다.
2) 식별할 수 있는 동작
•
식별할 수 있는 동작 또는 공개 API에 대해서는 Mock을 사용할 수 있다. 세부 구현사항과 거리가 있기 때문에 리팩터링 내성을 저해하지 않는다.
3) 시스템 외부 통신 또는 통신의 결과가 외부에 영향을 줄 경우
•
어플리케이션에서 통제할 수 없는 외부 시스템에 대해서는 Mock을 사용할 수 없다. 역시나 어플리케이션 내부의 세부 구현사항과는 거리가 있고, Mock 사용에 따라 단위 테스트의 성능을 높일 수 있기 때문이다.
4) 완전 통제가 가능한 외부 의존성에는 Mock 사용 자제
•
외부 의존성에 대해 어플리케이션에서 완전 통제가 가능하다면 Mock 사용에 따른 부작용(리팩터링 내성 저해) 대신 성능과 타협하는 것이 바람직하다.
다. 용어 정리
1) Mock vs Stub
•
테스트 대역(Test Double): 대체 사용되는 가짜 의존성 전체
•
Mock: MUT 호출에 따라 SUT 외부에서 상태에 변화가 생기는 의존성 대상의 테스트 대역
•
Stub: MUT 호출에 따라 SUT 내부에서 값을 반환하는 의존성 대상의 테스트 대역
2) 도구 Mock vs 테스트 대역 Mock
•
테스트 프레임워크에서 제공하는 ‘도구 Mock’(Mock Library)은 테스트 대역을 만드는 툴이다. 다시 말해, ‘도구 Mock’을 활용해서 테스트 대역인 Mock과 다른 테스트 대역인 Stub을 쉽게 생성할 수 있다.
3) CQS(Command Query Separation)
•
메소드의 책임을 명령과 조회만으로 구분하는 개념이다. 명령 메소드는 부작용을 발생시키지만 값을 반환하지 않는다. 반면 책임 메소드는 부작용을 발생시키지 않지만 값을 반환한다.
마. 기타 질문
1) 재고 감소 검증 코드(예제 5.11)에서 IStore은 외부 의존성이 아닌 내부 의존성인데도 Mock으로 검증한 이유는 무엇인가?
•
CQS의 Command 메소드에 해당하기 때문에 Mock으로 추가 검증한 것이다. 다시 말해, Command 메소드 호출에 따른 Side Effect를 검증하기 위해 Mock을 사용한 것이다.
참고) 본책의 예제 5.11

2) 육각형 아키텍쳐에서 어플리케이션 서비스 내부의 도메인 서비스는 중간 결과를 반환한다. 중간 결과를 반환하기 때문에 세부 구현사항으로 보고, 도메인 서비스에 대해 단위 테스트를 하지 않는 것이 고전파의 스타일에 맞지 않는가?
•
아니다. 어플리케이션 서비스 관점에서 도메인 서비스는 식별할 수 있는 동작이자 공개 API로 보는 것이 바람직하다. 다시 말해, 도메인 서비스를 세부 구현사항으로 보는 것은 저자의 의도를 잘못 이해한 것이다.
7. 단위 테스트 스타일의 Best Practice는?
출력 기반 스타일이 리팩터링 내성, 유지보수성 면에서 이점이 크기 때문에 가능하면 출력 기반을 사용하자. 단, 해당 스타일을 적용하기 위해서는 SUT가 함수형 아키텍처로 구성되어야 한다. 함수형 아키텍처는 높은 유지보수성이 필요하지만 성능에 민감하지 않은 경우에 선택적으로 적용하는 것을 권장한다.
가. 출력 기반 스타일이 최고다
1) 리팩터링 내성을 위한 추가 작업
•
출력 기반은 반환 결과만 테스트하기 때문에 테스트가 세부 구현과 결합될 가능성이 가장 낮다. 반면 상태 기반 및 통신 기반의 경우 세부 구현사항이 의존성과 연결될 가능성이 높다.
2) 유지보수성
•
출력 기반은 반환 결과만을 대상으로 검증하기 때문에 유지보수할 코드가 가장 적다. 상태 기반의 경우, 부수 효과가 발생하는 의존성을 대상으로 목을 설정하고, 추가 검증에 대한 코드를 유지보수 해야 한다. 통신 기반의 경우, 통제할 수 없는 외부 의존성에 대한 설정 부분에 대한 코드를 유지보수 해야 한다.
나. 함수형 아키텍처로 리팩토링
1) 함수형 아키텍처 가이드
•
함수형 아키텍처는 함수 실행 결과는 오직 반환값을 통해서만 확인있다. 함수형 아키텍처로 정의하기 위해서는 함수 실행에 따라 외부에 영향을 줄 수 있는 요소를 제거해야 한다. 그런 의미에서 숨겨진 입출력이 제거 대상이다. 저자에 따르면 숨겨진 입출력을 제거하는 방법 중 하나는 순수 함수 실행 이후 시점으로 해당 입출력 코드를 이전하는 것이다.
2) 함수형 아키텍처로 리팩토링
•
함수형 아키텍처 리팩토링의 주요 작업은 주요 비지니스 로직 이전과 숨은 입출력 객체 제거하는 것이다. 이하 예제의 경우, OrderService 내 주요 비지니스 로직을 Customer::order로 이전했다. OrderService는 Customer::order의 반환값을 대상으로 DB와 협력한다.
•
Domain Service의 순수 함수성을 깨뜨리는 숨은 입출력 객체를 찾아서 제거해야 한다. 이하 예제에서 가변 콜렉션에 대한 외부의 참조를 제거했고, 기존의 예외발생 로직을 Customer::order의 반환값에 반영했다.
3) 통신 기반 → 상태 기반 변경
•
테스트 대역을 실제 객체로 대체한다. SUT와 협력자 사이의 상호작용 검증을 제거하고 숨은 출력에 대해 검증한다.
4) 상태 기반 → 출력 기반 변경
•
SUT를 Application Service가 아닌 Domain Service로 대체한다. 협력자와의 상호작용에 대한 검증을 제거하고 MUT의 반환값을 대상으로만 검증한다.
참고) 리팩터링 전 주문 비지니스 로직 코드
class OrderService(
private val orderRepository: OrderRepository,
private val itemRepository: ItemRepository,
) : OrderLogic<Order, OrderData> {
override fun order(orderData: OrderData): Order {
val order = Order()
var totalPrice = BigDecimal.ZERO
val item: Item = itemRepository.findByIdInLock(orderData.itemId)
item.decreaseStock(orderData.itemQuantity)
totalPrice = item.calculatePriceWith(totalPrice, orderData.itemQuantity)
itemRepository.save(item)
order.addDeliveryFeeByAmountLimit(totalPrice)
this.updateWith(order)
return order
}
}
Kotlin
복사
참고) 리팩터링 후 주문 비지니스 로직 코드
class Customer {
fun order(orderData: OrderData): OrderResult {
val order = Order()
val item = orderData.item
var totalPrice = BigDecimal.ZERO
totalPrice = this.calculatePriceWith(totalPrice, item!!.price, orderData.orderQuantity)
try {
item.decreaseStock(orderData.orderQuantity)
} catch (e: SoldOutException) {
return OrderResult(false, totalPrice, arrayListOf())
}
order.addDeliveryFeeByAmountLimitTo(totalPrice)
return OrderResult(true, order.price, arrayListOf())
}
}
class OrderServiceImp(
private val customer: Customer,
private val orderRepository: OrderRepository,
private val itemRepository: ItemRepository,
) : OrderService<OrderResult, OrderData> {
override fun order(orderData: OrderData): OrderResult {
val item: Item = itemRepository.findByIdInLock(orderData.itemId)
orderData.item = item
val result = customer.order(orderData)
itemRepository.save(item)
orderRepository.save(Order(null, result.price, result.orderItems.toMutableList()))
return result
}
}
Kotlin
복사
참고) 통신 기반 스타일 테스트 코드 참고
describe("주문 시") {
context("주문금액이 5만원 이상이면") {
orderQuantity = 2
stockQuantity = 7
itemPrice = BigDecimal.valueOf(45000)
val orderRepositoryStub = mockk<OrderRepository>()
val itemRepositoryStub = mockk<ItemRepository>()
val sut = OrderService(orderRepositoryStub, itemRepositoryStub)
val orderData = OrderData(itemId, orderQuantity, item)
every { itemRepository.findByIdInLock(itemId) } returns item
val order = service.order(orderData)
it("주문금액에 배송료를 포함하지 않는다") {
order.price shouldBe itemPrice.multiply(BigDecimal(orderQuantity)
}
it("item을 한 번 조회한다") { // 안티패턴(Stub 검증)
verify(exactly = 1) { itemRepositoryStub.findByIdInLock(itemId) }
}
}
}
Kotlin
복사
참고) 상태 기반 스타일 테스트 코드 참고
describe("주문 시") {
context("주문금액이 5만원 이상이면") {
orderQuantity = 2
stockQuantity = 7
itemPrice = BigDecimal.valueOf(45000)
val orderData = OrderData(itemId, orderQuantity, item)
val actualStockQuantity = itemRepository.findByIdInLock(itemId).stockQuantity
val sut = OrderService(orderRepository, itemRepository)
val order = sut.order(orderData)
it("주문금액에 배송료를 포함하지 않는다") {
order.price shouldBe itemPrice.multiply(BigDecimal(orderQuantity)
}
it("주문 수량만큼 재고가 준다") {
actualStockQuantity shouldBe (stockQuantity - orderQuantity)
}
}
}
Kotlin
복사
참고) 출력 기반 스타일 테스트 코드 참고
describe("주문 시") {
context("주문금액이 5만원 이상이라면") {
orderQuantity = 2
stockQuantity = 7
itemPrice = BigDecimal.valueOf(45000)
val item = Item(itemId, itemPrice, itemName, stockQuantity)
val orderData = OrderData(itemId, orderQuantity, item)
val sut = Customer()
val result = sut.order(orderData)
it("주문금액에 배송료를 포함하지 않는다") {
result.price shouldBe itemPrice.multiply(BigDecimal(orderQuantity))
}
it("주문이 성공한다") {
result.isSuccess shouldBe true
}
}
}
Kotlin
복사
다. Trade Off: 성능 vs 유지보수성
1) 성능
•
성능에 민감하지 않다면 함수형 아키텍처 선택하는 것이 바람직하다.
2) 유지보수성
•
오직 함수의 시그니처에 입출력이 종속되고 부수 효과가 발생하지 않기 때문에 유지보수성이 뛰어나다. 단, 복잡하지 않은 로직에 함수형 아키텍처를 적용한다면 순수 함수 조건을 만족하는 과정에서 발생하는 비용에 따른 효과가 미미할 수 있다.
마. 용어 정리
1) Side Effect
•
함수의 호출 또는 연산의 결과에 따라 외부의 상태가 변경되는 것을 말한다.
•
Side Effect는 부작용 대신 부차 작용, 부수 작용으로 번역하는 것이 바람직하다. 표준국어대사전에 따르면 부작용이란 어떤 일에 부수적으로 일어나는 바람직하지 못한 일이다. ‘side effect’라는 단어를 바람직하지 못한 일이라는 의미가 담긴 단어로 대체하는 것은 원저자의 의도를 왜곡하는 것이므로 적절하지 않다.
2) 출력 기반 스타일 테스트
•
MUT에 대한 입력을 바탕으로 반환값에 대해서만 검증하는 테스트이다. 단, MUT 시그니처 외 숨은 입출력이 존재하면 안된다.
3) 상태 기반 스타일 테스트
•
MUT 호출에 따라 MUT의 반환값 외에도 외부의 상태 변화를 추가로 검증하는 테스트이다.
4) 통신 기반 스타일 테스트
•
SUT와 협력자 사이의 상호작용을 검증하는 테스트이다. 검증 방법은 협력자에 Mock을 사용하여 SUT와의 상호작용을 확인한다.
5) 숨은 출력
•
반환값 외에 함수 외부로 미치는 영향을 말한다. 대표적인 예로 다른 객체의 상태 변화 또는 예외 발생을 들 수 있다.
6) 숨은 입력
•
함수 내부에서 외부 객체를 참조하거나 외부에서 함수 내부 객체를 참조하는 것을 말한다.
마. 기타 질문
1) 함수형 아키텍처는 유지보수성 향상을 위해 성능을 희생한다는 주장의 근거는?
•
불변성을 지키기 위해 성능면에서 희생이 필요하다. 예를 들어, 컬렉션의 불변성을 지키기 위해서는 모든 요소를 대상으로 깊은 복사를 해야 한다. 더불어 아직까지는 함수형 아키텍처에 대해 Low Level에서의 성능 최적화 방법을 적용할 수 없다.
2) 순수함수 내부에서 가변 Collection을 인자로 전달 받아서 사용할 경우, 숨겨진 입력을 제거하기 위한 방법은?
•
순수함수 내부에서 가변 Collection을 조작한 이후 외부에서 해당 Collection에 대한 참조를 막아야 한다. 순수함수의 반환 값에 해당 Collection을 불변 타입으로 변경하여 반환한다. 만약 외부 객체에서 가변 Collection으로만 받아야 한다면, 타입은 다른 객체인 가변 Collection을 만들고, 내부 요소를 복사하여 전달하는 방향을 선택해야 한다.
•
용철님 방법: 공개 API에서만 가변 Collection을 처리하도록 구현
3) 함수형 아키텍처로 도메인 서비스 객체를 정의할 경우, 다수의 예외 처리는 어떻게 하는가? 함수형 아키텍처를 따른다면 출력은 오직 반환값 뿐인데, 상황에 따른 예외를 어떻게 구분하여 반환값에 반영할 수 있는가?
•
순수함수는 예외 발생 자체를 허용하지 않는다. 함수형 아키텍처로 구성한다면 기존 예외 발생 부분을 별도의 연산으로 처리하는 것이 바람직하다.
8. 너무 복잡한 코드를 리팩토링하는 Best Practice는?
너무 복잡한 코드를 비지니스 로직와 오케스트레이션 로직으로 분리한다. 외부 의존성과의 상호작용은 오케스트레이션에서 처리한다. 만약 비지니스 로직 중간 결과를 토대로 외부 의존성과의 상호작용이 필요하다면 CanExceute/Execute 패턴, 도메인 이벤트를 활용할 것을 권장한다.
가. 너무 복잡한 코드의 간단한 분리
1) 너무 복잡한 코드란?
•
너무 복잡한 코드란 도메인 연관성(또는 알고리즘 복잡도)이 높고 협력자가 많은(또는 외부 의존성이 있는) 코드를 말한다.
2) 너무 복잡한 코드를 분리해야 하는 이유
•
테스트 대상으로써 가치는 있지만 유지보수성이 떨어지므로 가성비 있는 테스트 스위트를 유지하기 위해 분리해야 한다.
3) 간단한 분리 방법
•
Humble Object Pattern을 활용하여 너무 복잡한 코드를 비지니스 로직과 오케스트레이션 로직(Humble Object)으로 분리한다. 그리고 비지니스 연산의 결과를 모아서 반환하면 오케스트레이션에서 이를 받아서 외부 의존성에 반영한다.
나. 너무 복잡한 코드를 분리하기 어려운 경우
1) 간단하게 분리할 수 없는 경우
•
위와 같이 간단하게 분리할 경우, 전체적인 성능의 불리점이 두드러진다면 오케스트레이션 로직의 유지보수성을 희생하더라도 성능과 도메인 로직의 캡슐화는 지키는 방향으로 리팩토링해야 한다.
•
만약 비지니스 로직의 중간 결과를 바탕으로 간단한 전제조건을 추가하여 성능 상 불리점을 피할 수 있다면 CanExecute/Execute 패턴을 활용할 수 있다. 하지만 여러번 변경될 가능성이 있는 조건이라면 전제조건 대신 변경 내역을 추적하기 위해 Domain Event를 활용하는 방법이 있다.
2) CanExecute/Execute 패턴 활용
•
유효성 상태에 대한 도메인 필드를 추가하여 전제조건을 생성한다. 도메인 로직의 앞단에서 해당 전제조건 검증하여 비지니스 로직의 중간 분기점을 만든다. 참고로 해당 전제조건은 비지니스 로직과 연관되어있으므로 단위 테스트의 영역이다. 통합 테스트의 검증 대상이 아니다.
•
이하 CRM 예제 코드의 노란색 음영 코드를 참고한다.
3) 도메인 이벤트 활용
•
여러 번 변경될 가능성이 있는 상태에는 도메인 이벤트를 발생시켜서 상태의 변경 이력을 추적하고, 모든 비지니스 연산이 끝났을 때, 외부 의존성을 호출하여 해당 상태의 변경을 공유한다.
•
이하 CRM 예제 코드의 분홍색 음영 코드를 참고한다.
4) 비지니스 로직에 외부 의존성을 분리할 수 없는 경우
•
전제 조건 또는 상태 변경 이력이 아니라, 외부 의존성의 반환 결과에 따라 주요 비지니스 연산의 분기가 갈린다면 비지니스 로직에서 외부 의존성을 분리할 수 없다. 회원 가입 로직 중 외부 의존성을 활용한 이메일 유효성 검사, 주문 로직 중 외부 결제 모듈의 결제 실패등을 예로 들 수 있다. 외부 의존성 분리가 어려운 비지니스 로직에 대한 검증은 단위 테스트가 아닌 통합 테스트에 책임이 있다.
참고) CRM 예제 코드, p.258, 264~265
// User
public int UserId {get; private set;}
public bool IsEmailConfirmed {get; private set;}
public string CanChangeEmail()
{
if (IsEmailConfirmed) return "Can't change a confirmed email";
return null;
}
public void ChangeEmail(string newEmail, Company company)
{
Precondition.Requires(CanChangeEmail() == null);
if (Email == newEmail) return;
UserType newType = company.IsEmailCorporate(newEmail)
? UserType.Employee
: UserType.Customer;
if (Type != newType){
int delta = newType == UserType.Employee ? 1 : -1;
company.ChangeNumberOfEmployees(delta);
}
Email = newEmail;
Type = newType;
EmailChangedEvents.Add(new EmailChangedEvent(UserId, newEmail));
}
C#
복사
// Controller
public string ChangeEmail(int userid, string newEmail)
{
object[] userData = _database.GetUserById(userid);
User user = UserFactory.Create(userData);
string error = user.CanChangeEmail();
if (error != null)
return error;
object[] companyData = _database.GetCompany();
Company company = CompanyFactory.Create(companyData);
user.ChangeEmail(newEmail, company);
_database.SaveCompany(company);
_database.SaveUser(user);
foreach (var ev in user.EmailChangedEvents) {
_messageBus.SendEmailChangedMessage(ev.Userid, ev.NewEmail);
}
return "OK";
}
C#
복사
다. 용어 정리
1) 순환 복잡도(Cyclomatic Complexity)
•
순환 복잡도는 코드의 복잡도를 측정하는 정량적 지표이다. 순환 복잡도의 계산은 특정 연산의 처음부터 끝까지 도달하는 경로에 대한 모든 경우의 수를 구하는 것이다. Extended Cyclomatic Complexity 방법으로 계산하면 순환 복잡도는 ‘1 + 최소 단위의 조건’이 된다. 예를 들어, 아래와 같이 하나의 분기 안에 최소 단위의 조건이 2개가 포함됐다면 순환 복잡도는 1 + 2 = 3이 된다.
•
예시 코드
public void testMethod(int a) {
if(a > 2 && a < 10){
a += 1
}
}
Java
복사
3) 도메인 유의성(Domain Significance)
•
프로젝트 도메인과의 관계의 깊이에 비례하여 코드의 중요도를 측정하는 정성적 지표이다.
ex) 도메인 서비스 >> 어플리케이션 서비스 > 컨트롤러
4) 협력자의 수
•
특정 로직에 대한 협력자의 수에 반비례하여 코드의 유지 보수성을 측정하는 정성적 지표이다. 단순히 협력자의 수에 반비례하는 것이 아니라 협력자의 적절한 사용여부도 중요한 측정 요소이다. 예를 들어, 도메인 모델에는 프로세스 외부 협력자를 사용하는 것은 부적절하다.
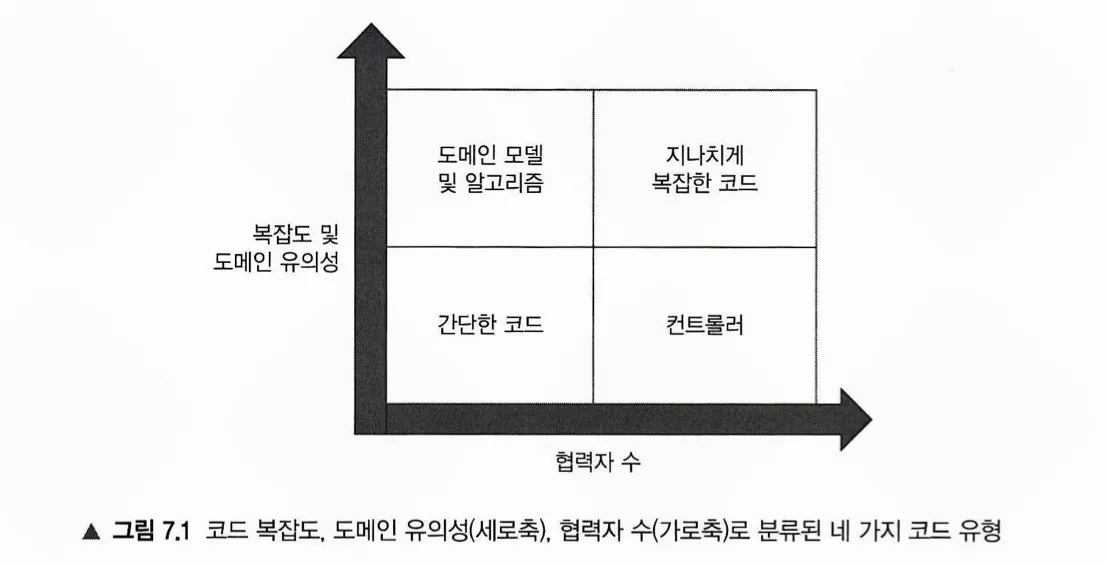
5) 코드 사분면
•
코드의 복잡도와 도메인 유의성 그리고 협력자의 수로 모든 코드를 네 가지 유형으로 나눈 것을 말한다. 단위 테스트면에서 가장 가치 있는 코드는 협력자의 수가 낮고 복잡도 및 중요도가 높은 코드이다. 테스트 생성 비용이 저렴하지만 회귀 방지의 대상이 되는 코드가 일반적으로 중요하기 때문이다. 반면 협력자의 수가 많고 복잡도 및 중요도가 떨어지는 코드는 분할의 대상이다. 테스트 대상으로서 가치는 있지만 유지 비용이 너무 높기 때문이다.
•
세로의 축을 복잡도와 중요도의 두 가지 조건의 합으로 정한 이유는 매우 중요하지만 복잡하지 않은 코드가 있기 때문이다.
•
참고) 본 책의 그림 7.1, p.231
라. 기타 질문
1) 순환 복잡도(이하 CC)에 대한 정의와 계산법 사이에 모순이 있다.(p229) 정의에 따르면 메서드 시작부터 끝까지 가는 독립적인 경로의 수이다. 하지만 예시에서는 ‘독립적인 경로의 수’에 대한 계산을 제거하고 분기점을 쪼개서 가장 간단한 조건을 기반으로 복잡도를 계산한다.
•
최초의 순환 복잡도(by Thomas J. McCabe)는 독립적인 경로의 수로 코드의 복잡도를 계산했다. 다시 말해, 분기의 개수를 기준으로 순환 복잡도를 계산했다. 이후 분기에 여러 조건이 포함된 경우를 1로 계산하는 것은 부적절하다는 문제가 제기되어 Extended Cyclomatic Complexity(이하 ECC)가 등장했다. ECC에서는 분기 내 최소 단위의 조건을 기준으로 순환 복잡도를 계산한다.
•
참고로 McCabe는 함수의 CC를 기준으로 10을 넘어가면 분할 대상이되며, 15 이상은 넘기지 말 것을 권고하고 있다.
2) Humbe Object Pattern의 Humble이라는 단어는 어떤 의미로 해석해야 하는가? 겸손은 이상하다. 어떤 의미에서도 해당 내용이 겸손하지는 않기 때문이다.
•
•
위의 해석에 따라 Humble Object Pattern을 다시 살펴보자. 테스트가 불가능한 원본 객체에서 테스트 가능한 로직을 별개의 객체로 분리하면, 원본 객체는 컨트롤러의 역할만 하는 ‘큰 가치가 없는’, ‘보잘 것 없는’ 객체가 되어버린다.
3) 전혀 복잡하지 않지만 도메인과 밀접한 코드는 좌측 상단 사분면에 해당하여 테스트 가치가 있다고 한다. 그렇다면 매우 복잡하지만 도메인과 밀접하지 않은 코드도 좌측 상단 사분면에 해당하는데 앞서 말한 케이스와 유사한 테스트 가치가 있다고 말할 수 있는가?
•
사분면의 세로 축에 설명된 복잡도와 사분면의 좌측 상단의 지나치게 복잡한 코드의 ‘복잡’은 매우 다르다. 전자의 경우, 알고리즘면에서의 복잡도를 말한다. 후자의 경우, 협력자의 수 또는 외부 의존성의 존재에 따른 유지보수성면의 복잡도를 말한다.
•
알고리즘면에서의 복잡도는 회귀 방지면에서 테스트 가치가 높다고 할 수 있다.
4) 너무 복잡한 코드를 간단하게 분리할 수 없을 때, CanExecute/Execute 패턴과 도메인 이벤트는 각각 어떤 상황에서 사용할 수 있는가?
•
CanExecute/Execute 패턴은 도메인 객체 내부의 상태 변화를 토대로 비지니스 의사결정을 할 수 있을 때 사용한다. 예제 코드에서는 도메인 객체의 멤버 변수(IsEmailConfirmed)를 도메인 서비스의 전제조건으로 사용했다. 반면 도메인 이벤트의 경우, 도메인 객체의 상태를 외부로 전달하는 용도로 사용할 수 있다. 예제의 경우, 이메일의 변경 여부에 대한 상태를 외부의 알림 시스템에 전달하기 위해 도메인 이벤트를 발생시켰다.
9. 통합 테스트의 Best Practice는?
통합 테스트는 외부 의존성과 통합한 환경에서 단위 테스트로 검증할 수 없는 비지니스 로직을 검증하는 것이다. 또는 외부 의존성과의 정상적인 통합여부를 확인하는 것이다.
가. 통합 테스트의 목적
1) 외부 의존성과 통합한 상태에서 정상 동작 테스트
•
외부 의존성과 통합한 상태에서 비지니스 모델의 정상동작 여부를 확인하는 것이 통합 테스트의 주요 목적이다. 하나의 비지니스 로직 당 2개 정도의 통합 테스트를 작성할 것을 권장한다.
2) 단위테스트만으로 확인 불가한 예외 테스트
•
단위테스트만으로 확인할 수 없는 예외사항을 테스트하는 것도 통합 테스트의 주요 목적 중 하나다. 예를 들어, 비인가 사용자와 인가 사용자에 따라 다른 비지니스 로직이 동작하는 경우는 단위테스트만으로 전체적인 비지니스 로직의 정상 동작 여부를 확인할 수 없다.
나. 목적에 맞는 통합 테스트 작성법
1) 가장 긴 주요 흐름 확인
•
외부 의존성과 가장 많이 연결된 로직을 대상으로 통합 테스트를 작성하여 외부 의존성과의 정상적인 통합 여부를 효과적으로 확인할 것을 권장한다. 외부 의존성과 통합된 상태에서의 정상적인 동작여부를 확인하는 목적을 달성하기 위해 여러 테스트 케이스가 필요하지 않다. 비지니스 로직에 대한 정상 동작 여부 및 예외 확인은 모두 단위 테스트의 역할이다.
2) 관리 의존성은 실객체, 비관리 의존성은 mocking으로 테스트
•
통합 테스트는 외부 의존성 중 관리 의존성을 대상으로 실제 통합된 상태에서 정상 동작을 확인할 수 있다. 따라서 관리 의존성은 mocking하지 않고 실제 인스턴스를 대상으로 테스트할 것을 권장한다. 대표적인 관리 의존성이 ‘내부 데이터베이스’이다.
•
비관리 의존성을 실객체로 사용하는 테스트는 e2e 테스트에 해당한다. 통합 테스트에서는 해당 의존성에 대해 Mocking함으로써 상호작용만 검증한다. 왜냐하면 비관리 의존성에 대한 테스트 설정 비용이 너무 크기 때문에 마지막 단계(e2e)에서만 검증하는 것이 전체적인 테스트 스위트를 가성비 있게 유지할 수 있다.
다. E2E 테스트 vs 통합 테스트
1) 외부 의존성 중 실제 통합되는 대상의 차이
•
E2E 테스트는 배포된 서비스를 대상으로 모든 외부 의존성을 통합한 상태에서 테스트한다. 관리 의존성은 어플리케이션을 통해 간접 확인해야 한다. 비관리 의존성도 Mocking하지 않고 실제 동작하는 상태에서 테스트한다는 것이 주요 차이점이다. 반면 통합 테스트는 어플리케이션과 동일 프로세스에서 테스트를 수행하므로 관리 의존성만을 대상으로 실통합이 가능하다.
2) E2E 테스트가 필요한 경우
•
대부분의 경우 통합 테스트만으로 E2E 테스트의 범위를 다룰 수 있다. 그렇다면 E2E 테스트는 불필요하다. 하지만 ‘비관리 의존성’과 복잡하게 통합된 경우, 정상적인 통합 여부를 한 번 더 확인하는 절차가 필요할 수 있다. 모든 외부 의존성과 통합된 로직에 대해 소수의 E2E 테스트를 작성하여 정상 동작여부 확인 절차를 추가할 수 있다.
라. 용어 정리
1) 관리 의존성
•
테스트 대상 어플리케이션에서만 접근할 수 있는 프로세스 외부 의존성이다. 관리 의존성은 해당 어플리케이션의 유지보수 관리의 대상에 포함되므로 구조적인 변경에 대해 추적이 가능하다.
2) 비관리 의존성
•
다른 어플리케이션에서도 접근할 수 있는 프로세스 외부 의존성이다. 비관리 의존성은 테스트 대상 어플리케이션의 유지보수 관리 대상이 아닐 가능성이 높다. 다시 말해, 비관리 의존성에 대한 구조적인 변경이 발생하더라도 테스트 대상 어플리케이션 개발자 입장에서 해당 변경을 모를 수 있다.
마. 기타 질문
1) Spring의 Application Service에는 인터페이스를 적용하는게 맞는가?
•
본서에 따르면 인터페이스는 동일한 인터페이스에 대한 구현체가 두 개 이상 있을 때, 사용할 것을 권장한다. Application Service는 오케스트레이션이고 동일한 구현체가 두 개 이상 있을 가능성은 매우 낮다. 따라서 전체적인 코드의 유지보수성을 고려했을 때, Spring의 Application Service에 대한 인터페이스는 불필요하다.
10. 통합 테스트 Mock의 Best Practice는?
Mock은 SUT와의 하위 호환성을 검증하는 것이 핵심이다. 검증 대상의 가치에 따라 호환성 검증 정도는 달라질 수 있다.
가. 하위 호환성을 고려하여 Mock을 사용할 것
1) 오케스트레이션 내 비관리 의존성의 가장 마지막 고리에 대해 Mocking
•
Mock 객체의 리팩토링 내성을 극대화하기 위해 비관리 의존성의 가장 마지막의 단계에 대해 mocking할 것을 권장한다. 가장 마지막 단계란 두 가지 의미가 있는데, 하나는 Mocking의 대상은 제품 코드에 사용된 비관리 의존성 그 자체가 아니라 비관리 의존성에 의해 부수 작용을 발생시키는 내부 요소이다. 다른 하나는 유의미한 동작이 정의된 인터페이스의 가장 마지막을 기반으로 mock 객체를 정의한다는 것이다.
•
도메인 이벤트 전달에 대한 비관리 의존성에 대한 Mocking은 EventDispatcher::Dispatch 가 아니라 IMessageBus::SendEmailChangedMessage 을 대상으로 해야 한다. 왜냐하면 후자가 메시지 전송이라는 외부와의 상호작용의 가장 마지막 단계에 해당하므로 변경 가능성이 가장 낮기 때문이다. 아하의 제품 코드 예시를 살펴보면, _eventDispatcher.Dispatch() 가 가장 먼저 호출되어 도메인 이벤트를 처리한다. Dispatch 내부에는 private Dispatch가 있고, 그 내부에는 IMessageBus::SendEmailChangedMessage 을 가장 마지막 단계에서 호출한다.
•
IMessageBus는 메시지 버스에서 유의미한 동작(메시지를 전송)에 대한 마지막 인터페이스가 아니다. IBus가 해당 인터페이스이므로 Mock 정의 및 SUT와의 상호작용은 이하 예제 테스트 코드와 같이 수정하는 것이 바람직하다.
참고) p.316, 320 / 예제 9.3, 9.5 통합 테스트 코드
// before
var messageBusMock = new Mock<IMessageBuS>();
messageBusMock.Verify(
X => x.SendEmailChangedMessage(user.Userid, "newggmail.com"), Times.Once);
// after
var busMock = new Mock<IBuS>();
busMock.Verify( X => x.Send(
"Type: USER EMAIL CHANGED; " + $"Id: {user.Userid}; " + "NewEmail: new@gmail.com"), Times.Once);
C#
복사
참고) p.316, 예제 9.4 제품 코드
// UserController
public string ChangeEmail(int userId, string newEmail)
{
// 생략
user.ChangeEmail(newEmail, company);
_database.SaveCompany(company);
_database.SaveUser(user);
_eventDispatcher.Dispatch(user.DomainEvents);
// 생략
}
C#
복사
public class EventDispatcher{
}
private readonly IMessageBus _messageBus;
private readonly IDomainLogger _doniainLogger;
public EventDispatcher(
IMessageBus messageBus,
IDomainLogger domainLogger)
{
_domainLogger = domainLogger;
_messageBus = messageBus;
}
public void Dispatch(List<IDoinainEvent> events)
{
foreach (IDoinainEvent ev in events)
{
Dispatch(ev);
}
}
private void Dispatch(IDomainEvent ev)
{
switch (ev) {
case EmailChangedEvent emailChangedEvent:
_messageBus.SendEmailChangedMessage(
emailChangedEvent.UserId,
emailChangedEvent.NewEmail);
break;
}
}
}
C#
복사
2) 상호작용 검증은 그럴만한 가치가 있는 비관리 의존성에만 적용
•
비관리 의존성에 해당하는 로거와 SUT의 상호작용에서 검증하고자 하는 것은 로그의 발생여부, 로그 메시지 전달여부이다. 가장 가까운 Interface를 기준으로 Mock을 정의해도 충분하다.
•
Not ILogger But IDomainLogger enough
3) 비관리 의존성의 호출 수를 철저히 검증
•
mocking한 비관리 의존성의 의도한 메소드가 몇 번 호출되었는지를 검증하는 것은 하위 호완성을 검증한다는 면에서 의미가 있다. 더불어 비관리 의존성 내 비검증 대상인 메소드가 호출되지는 않았는지를 추가적으로 검증할 필요가 있다.
messageBusMock.Verify(X => x.SendEmailChangedMessage(user.Userid, "new@gmail.com"). Times.Once);
messageBusMock. VerifyNoOtherCalls (); // 비검증 대상 메소드의 호출 여부 확인
C#
복사
나. 목 활용 관련 기타 Know-hows
1) Mock 대신 Spy가 적절한 경우
•
오케스트레이션에서 비관리 의존성이 복잡하게 구성되어 가장 끝단에 대해 mocking하고 검증하는 것 보다 Spy를 테스트 코드 내 정의하여 사용하는 것을 권장한다.
// before
var busMock = new Mock<IBus>();
busMock.Verify( X => x.Send(
"Type: USER EMAIL CHANGED; " + $"Id: {user.Userid}; " + "NewEmail: new@gmail.com"), Times.Once);
// after
var busSpy = new BusSpy();
busSpy.ShouldSendNumberOfMessages(1)
.WithEmailChangedMessage(user.Userid, "new@gmail.com");
C#
복사
2) Third Party Library에 대해 Wrapper를 적용할 것
•
다음의 세 가지 이유로 외부 라이브러리에 대해 Wrapper 클래스로 묶는 것이 바람직하다. 하나 기본 라이브러리의 복잡성을 추상화할 수 있기 때문이다. 둘, 라이브러리에서 필요한 기능만 노출할 수 있기 때문이다. 마지막으로 프로젝트 도메인 언어를 사용하여 전체적인 가독성을 높일 수 있기 때문이다.
다. 용어 정리
1) 호환성 vs 하위 호환성
•
호환성: 두 제품을 서로 대체할 수 있다.
•
하위 호환성: 상위 버전이 이전 버전을 대체할 수 있는 호환성이다. 반대로는 대체할 수 없다. 하위 호환성을 고려하여 개발할 경우, 이전 버전의 인터페이스를 기반으로 새로운 기능을 추가하는 방향으로 작업한다.
2) Spy vs Mock
•
Mock은 프레임워크를 활용하여 생성하는 반면에 Spy는 개발자가 직접 정의한다.
라. 기타 질문
1) SpringBootTest 어노테이션으로 테스트 시 ‘Web Client’에 대해 mocking해야 하는가?
•
Web Clinet는 비관리 의존성이므로 책에 따르면 Mocking하는 것이 맞다. 하지만 각 테스트 케이스마다 Web Client를 Mocking하면 생산성이 너무 떨어진다. 더불어 일반적인 비관리 의존성과는 별개로 테스트 라이브러리이므로 Mock을 정의할 때 사용하는 Mock 도구와 같이 테스트 목적으로 그대로 사용하는 것이 바람직하다.
11. DB 테스트의 Best Practice는?
DB를 관리 의존성으로 보고 통합 테스트하기 위해서는 로컬 머신에서 로컬 DB 환경에서 테스트해야 한다. DB 테스트 구성 시 운영 환경과 유사하게, 순차적 실행 환경으로 구성하여 수고 대비 테스트의 가치를 높이는 것을 권장한다.
가. 통합테스트 환경 구성
1) 전체적인 비용을 고려했을 때, 순차적 실행환경으로 구성할 것
•
통합 테스트를 병렬적으로 실행하기 위해서는 효과 대비 너무 많은 수고가 들어가므로 순차적으로 실행하는 방향으로 환경을 구성하는 것이 낫다.
•
테스트 실행 환경을 구성할 때, 단위 테스트는 병렬적으로 실행하고 통합 테스트는 순차적으로 실행하도록 구성하는 것을 권장한다.
2) 테스트 시작 시점에 데이터 정리할 것
•
테스트 시작 시점에 데이터를 정리하면 실수로 DB에 테스트 데이터가 남는 것을 방지할 수 있다. 반면 테스트 종료 시점에 데이터를 정리할 경우, 의도치 않게 테스트가 중단되어 DB에 데이터가 남을 수 있다.
3) 인메모리 DB는 피할 것
•
테스트 환경에는 인메모리를 쓰고 운영 환경은 그렇지 않다면 일관성 부족에 따른 문제가 발생한다. 거짓 양성과 거짓 음성이 발생하여 테스트의 전체적인 가치를 떨어뜨릴 수 있다.
나. 테스트 코드 재사용
1) 비지니스 로직과 관련 없는 코드를 추출할 것
•
통합 테스트 간 재사용이 가능한 부분 중 비지니스 로직과 관련 없는 부분을 별도로 추출하는 방법을 권장한다. 추출한다면 테스트 코드 간 재사용을 할 수 있고 비지니스 로직 부분을 드러낼 수 있기 때문에 테스트의 가독성을 높일 수 있다.
2) 준비 구절 코드 재사용
•
Object Mother 패턴의 활용을 권장한다. 단위 테스트 코드 내 비공개 팩토리 메소드를 정의하여 주요 엔티티에 대한 준비 코드를 줄일 수 있다. 이 때, 팩토리 메소드 내 인자로 핵심 매개변수를 전달하여 테스트 케이스에 대한 가독성을 높일 수 있다. 단, 선택적 인수를 강조할 수 있는 환경에서만 해당 가독성 효과를 볼 수 있다.
3) 실행 구절 코드 재사용
•
SUT 호출부가 포함된 대리자 메서드를 사용하여 실행 구절을 줄일 수 있다.
4) 검증 구절 코드 재사용
•
준비 구절과 같은 헬퍼 메소드를 만들어서 검증 구절을 간소화할 수 있다.
다. 테스트 대상
1) 읽기 보다는 쓰기 중심으로
•
DB와 연관된 시나리오 중 치명적인 부작용은 대게 쓰기와 연관되어 있다. 반면 읽기의 경우, 부작용이 크지 않다. 따라서 DB 통합 테스트의 검증 대상은 읽기 보다는 쓰기 기능에 집중되어야 한다.
2) 레파지토리는 테스트의 대상이 아니다
•
레파지토리는 세부 구현사항에 해당된다. 따라서 레파지토리에 대한 직접 검증 보다는 레파지토리에 대한 실제 인스턴스가 주입된 비지니스 로직을 테스트하는 것이 적절하다.
라. 용어 정리
1) 상태 기반 DB 배포 방식 vs 마이그레이션 기반 DB 배포 방식
•
상태 기반 DB 배포 방식: 개발 내내 모델 DB를 유지하고, 모델 DB에 대한 DDL을 기반으로 운영환경의 DB를 유지한다. 이 때, DDL은 비교 도구를 토대로 모델 DB를 기반으로 스크립트가 생성된다.
•
마이그레이션 기반 DB 배포 방식: 스키마의 변경내역이 형상관리시스템에 남기 때문에 별도의 DDL 스크립트가 필요 없다.
마. 기타 질문
1) (p.348) 도메인 주도 설계에서 하나의 비지니스 연산에서 둘 이상의 집계를 수정하면 안되는 이유는?
2) (p.348) 하나의 비지니스 연산 안에서 비관계형 데이터베이스의 둘 이상의 document를 수정하면 안되는 이유는?
•
하나의 비지니스 연산 안에 둘 이상의 document를 수정할 경우, 트랜잭션이 지원되지 않는다. 따라서 하나의 비지니스 연산이 중간에 실패할 경우, 일부의 document에는 수정사항이 반영되고, 나머지에는 반영되지 않을 수 있다.
•
위와 같은 이유로 비관계형 데이터베이스를 채택한다면 비지니스 연산을 고려하여 하나의 document 단위를 잘 설계해야 한다.
3) (p. 352) ‘데이터베이스 트랜잭션에 각 테스트를 래핑하고 커밋하지 않기’ 방법을 사용하면 추가 트랜잭션으로 인해 운영 환경과 다른 설정이 생성된다는게 무슨 말이지?
•
운영 환경에서 하나의 SUT 내 여러 개의 트랜잭션으로 구분될 경우가 존재할 수 있다. 만약 SUT를 하나의 트랜잭션으로 묶어버린다면 운영 환경과 다른 환경에서 테스트한다는 의미이다.
•
같은 맥락에서 통합 테스트 시 Transactional 어노테이션을 붙이는 것은 안티패턴이다. 각 테스트 케이스의 시작단계에서 테스트 데이터를 리셋하는 작업이 필요하다. 테스트 데이터에 대한 bulk delete, bulk insert 사용하여 데이트 데이터 환경을 초기화할 수 있다.
4) (p. 358) 준비 구절에서 팩토리 메소드는 단위 테스트 클래스에 두라는 말이 맞는가?
•
맞다. 단위 테스트와 통합 테스트의 SUT는 다르므로 준비구절에서 다른 팩토리 메소드가 필요하다. 단위 테스트와 통합 테스트 환경에서 동일한 준비구절이 필요하다면 별도의 헬퍼 클래스를 둘 수도 있다.
12. 안티패턴의 이유와 개선 방법은?
가. 비공개 메소드 테스트
1) 안티패턴인 이유
•
비공개 메소드는 식별할 수 있는 동작이 아니기 때문에 세부 구현사항에 해당한다. 세부 구현사항을 테스트하는 것은 리팩토링 내성을 저하시키므로 피해야 한다.
2) 개선 방법
•
식별 가능한 동작에 대해 검증하여 비공개 메소드는 간접적으로 검증하는 것이 바람직하다. 만약 식별 가능한 동작으로 비공개 메소드의 모든 복잡도를 검증할 수 없다면 비공개 메소드에서 복잡한 로직에 대한 로직을 별도의 클래스로 추출하고 추출한 클래스를 추상화하여 테스트해야 한다.
나. 비공개 상태 노출
1) 안티패턴인 이유
•
테스트만을 위해 비공개 상태가 노출되면 회귀 방지 효과가 떨어진다. SUT에 대한 접근 방식은 테스트 코드나 제품 코드나 같아야 회귀 방지(테스트 목표)에 대한 신뢰를 가질 수 있다.
2) 개선 방법
•
테스트 편의를 위한 비공개 상태 노출 금지
다. 테스트에 도메인 지식 유출
1) 안티패턴인 이유
•
도메인 지식에 대한 유출은 결국 세부 구현사항에 대한 테스트로 이어질 가능성이 높다.
2) 개선 방법
•
블랙박스 테스트 관점에서 테스트 케이스를 작성해야 한다.
라. 테스트에만 필요한 코드를 제품 코드에 추가
1) 안티패턴인 이유
•
제품 코드의 전체적인 유비비용이 증가한다.
2) 개선 방법
•
테스트에만 필요한 코드는 테스트 클래스에 작성해야 한다.
마. 정적 메소드로 시간 처리
1) 안티패턴인 이유
•
정적 메소드로 시간을 표현하면 시간에 대한 내부 구현가 가려진다. 가령 초의 단위는 sec, mil sec, nano sec인지 명시적으로 확인할 수 없다. 테스트 시 확인하기 어렵다.

2) 개선 방법
•
시간은 현재 시간이 아니라 일반 값을 사용할 때, 추후 stub으로 검증하기 좋다. 따라서 정적 메소드를 통한 시간 보다는 명시적인 시간으로 대체하는 것이 바람직하다.
참고 자료
•
Vladimir Khorikov - Unit Testing
•
회귀 용어 뜻, 위키피디아 참고
•
•
•
Domain Service
◦
Domain Service vs Application Service, Vladimir Khorikov Blog Post
◦
Domain Logic, Vladimir Khorikov Blog Post
◦
Domain Model Isolation, Vladimir Khorikov Blog Post
◦
Service in DDD, Lev Gorodinski 블로그 포스팅
•
•
순환 복잡도
◦
추가 설명, 위키피디아
•
•
샘플 프로젝트 구현
◦
프로젝트 코드, GitHub 링크
◦
Test Framework: Kotest, 공식문서 참고
◦
Test Style: 우형블로그 참고
◦
◦
Mocking: MockK, 공식문서 참고
◦
Application Framework: Spring Shell, Baeldung 참고