1. Blocking I/O vs Non Blocking I/O
가. 기초 개념
•
Blocking I/O: I/O 작업을 요청한 스레드는 작업이 완료될 때까지 기다립니다.

•
Non-Blocking I/O: I/O 작업을 요청한 스레드는 작업이 완료될 때까지 기다리지 않고, 요청에 대한 현재 상태를 즉시 반환합니다. 다른 I/O 요청을 처리할 수 있습니다.
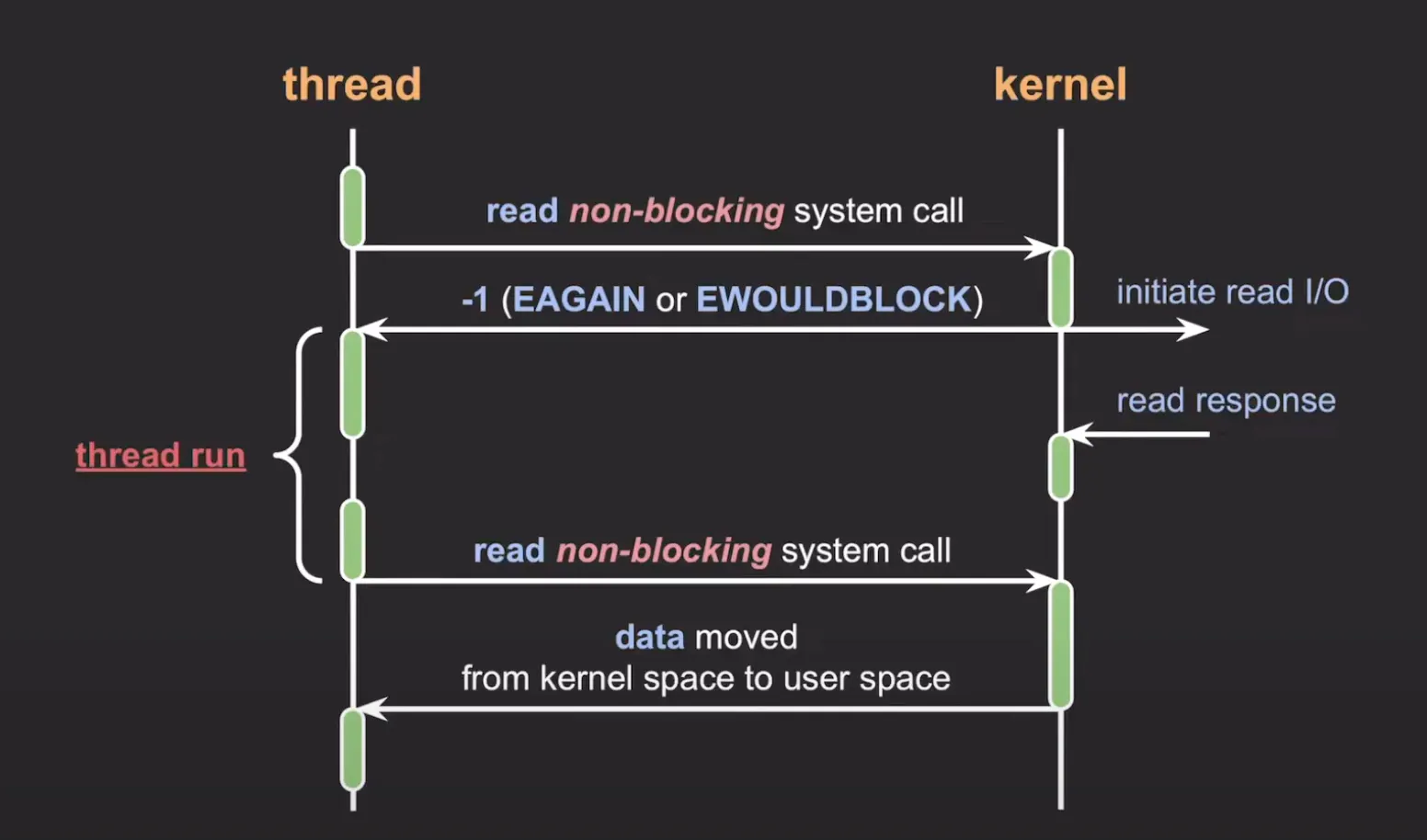
image from 쉬운코드, https://www.youtube.com/watch?v=mb-QHxVfmcs
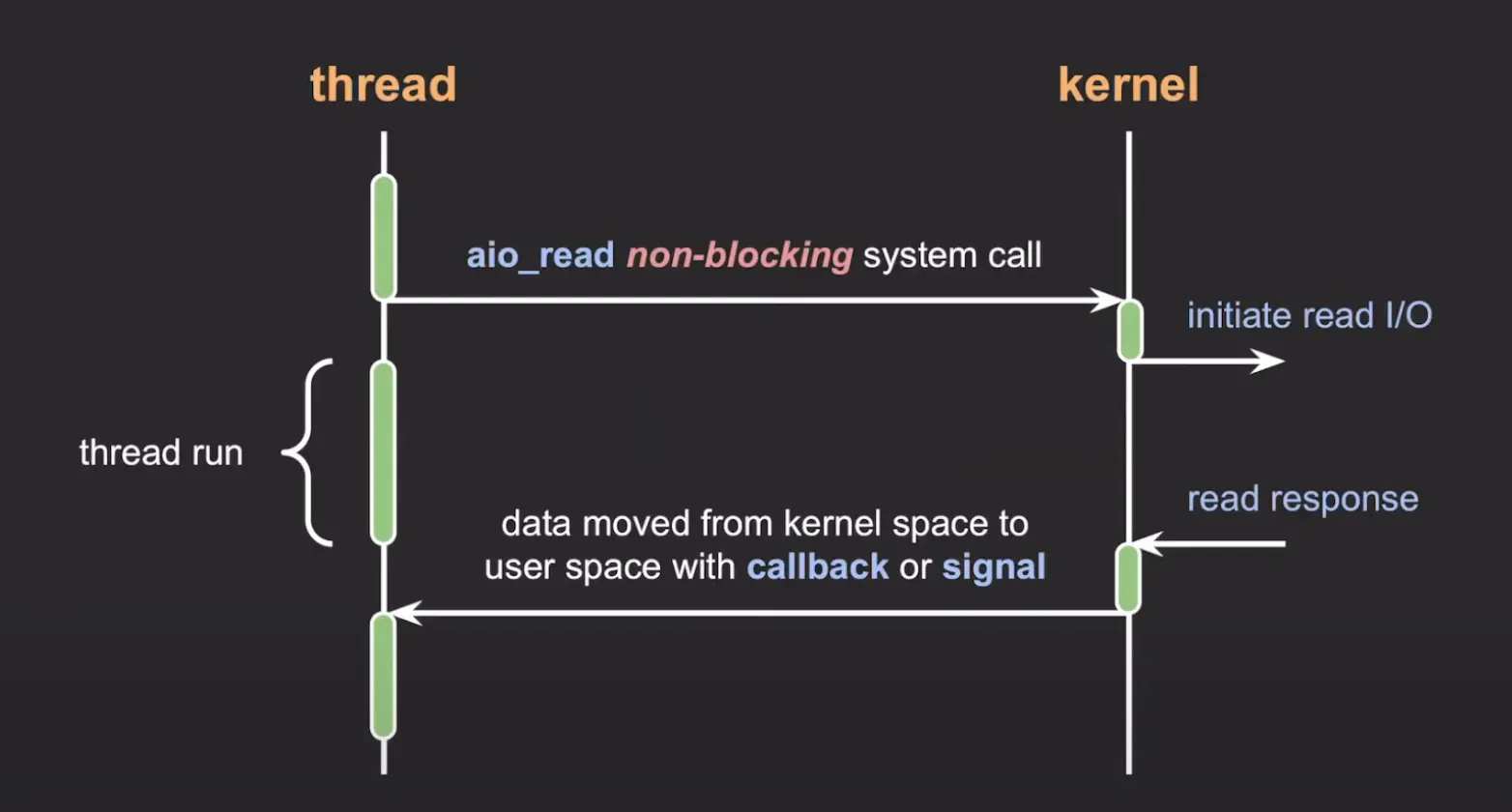
참고로 I/O 작업 완료 확인은 CPU가 소모되기 때문에 이를 최적화하는 방법이 여러 가지 있습니다. 하나는 I/O multiplexing 방식으로, 여러 개의 I/O 요청에 대한 작업 완료 확인을 한 번에 처리하는 방식입니다. 다른 방법으로 callback(or signal)을 시발점으로 데이터를 커널에서 사용자 공간으로 이동시키는 방식이 있습니다.
•
Synchronous: 순차적 실행을 의미하며, 맥락에 따라 다양하게 해석될 수 있습니다.
Synchronous Programming: 여러 작업을 순차적으로 실행하도록 프로그래밍하는 것입니다. 다시 말해, 첫 번째 작업을 실행하고 끝이나면, 두 번째 작업을 실행한다는 뜻입니다.
Synchronous I/O: Blocking I/O와 동일하게 볼 수 있습니다. 또는 IBM 문서에 따르면 I/O 작업을 요청하는 스레드가 작업 완료를 응답으로 받아서 직접 확인하는 방식을 말합니다.
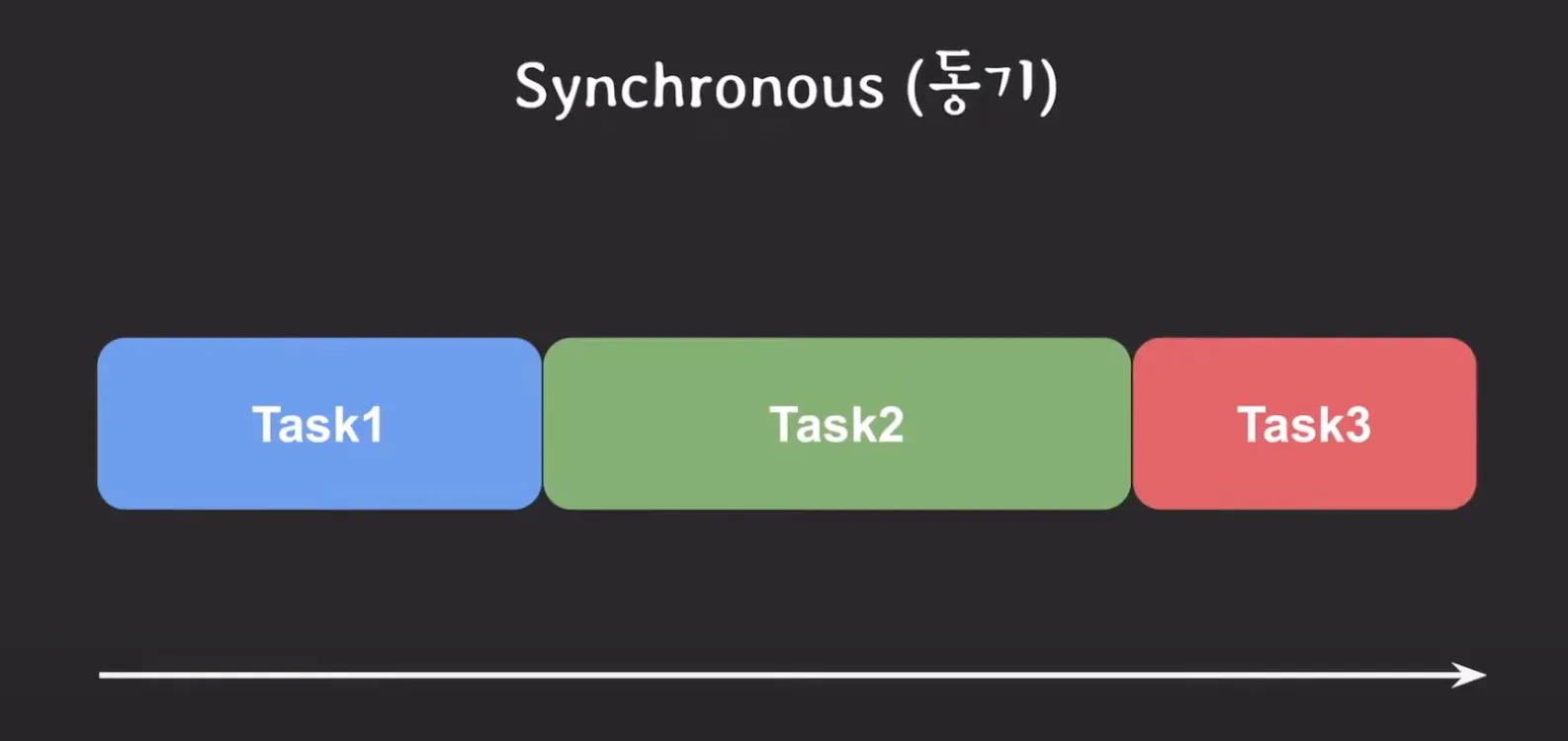
•
Asynchronus: 독립적 실행을 의미하며, 맥락에 따라 다양하게 해석될 수 있습니다.
Asynchronus Programming: 여러 작업을 독립적으로 실행하도록 프로그래밍합니다. 첫 번째 작업을 실행하고 끝나지 않아도, 두 번째 작업을 실행합니다.
Asynchronous I/O: Non Blocking I/O와 동일하게 볼 수 있습니다. 또는 IBM 문서에 따르면 I/O 작업을 요청하는 스레드가 작업 완료를 직접 확인하지 않고, callback(or noti)을 받아서 확인하는 방식을 말합니다. 또는 Blcoking I/O로 동작하는 작업을 다른 스레드에게 위임하고 본 스레드는 다른 작업을 동시에 처리하는 방식으로도 말합니다.
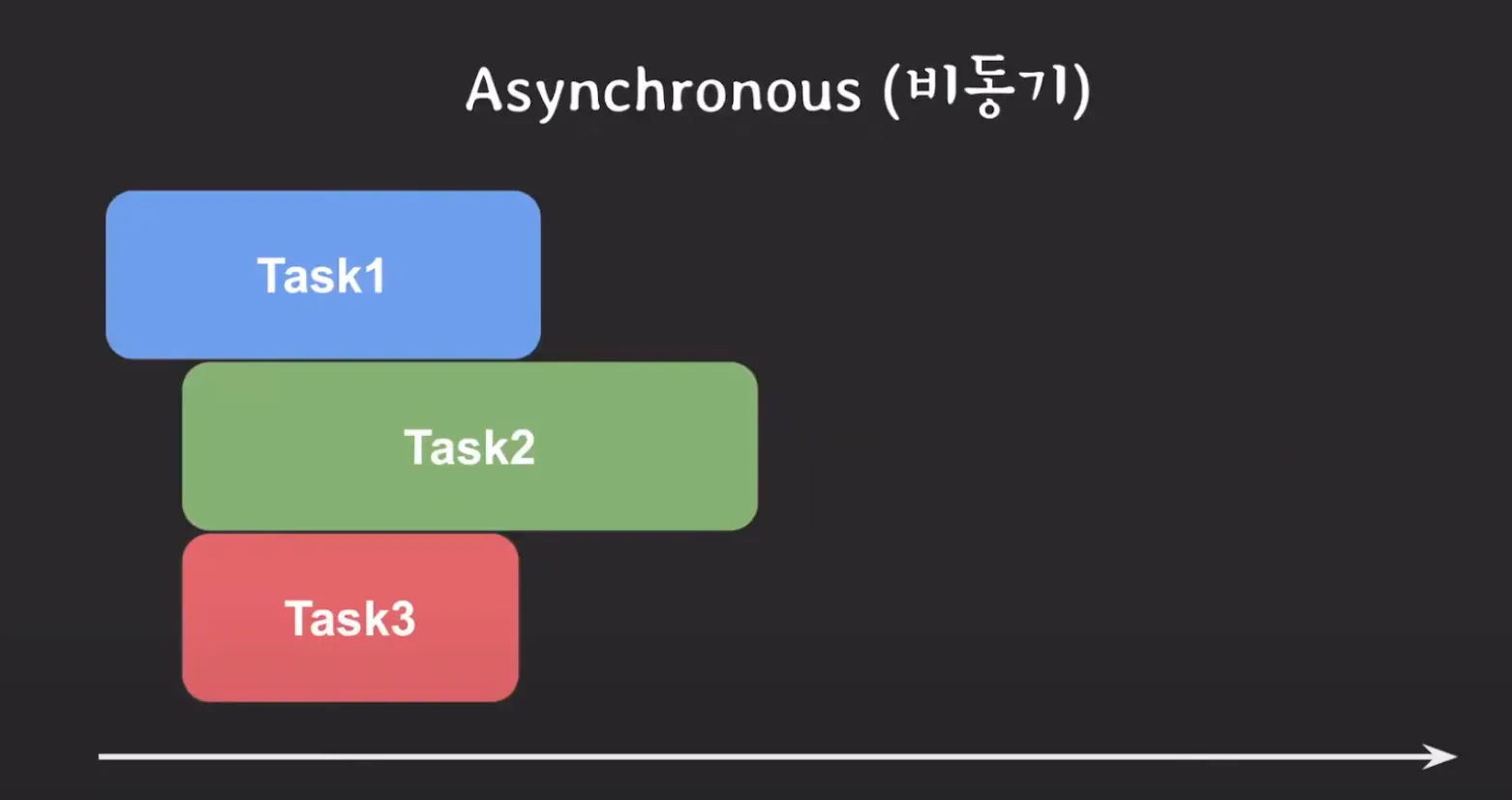
image from 쉬운코드, https://www.youtube.com/watch?v=EJNBLD3X2yg
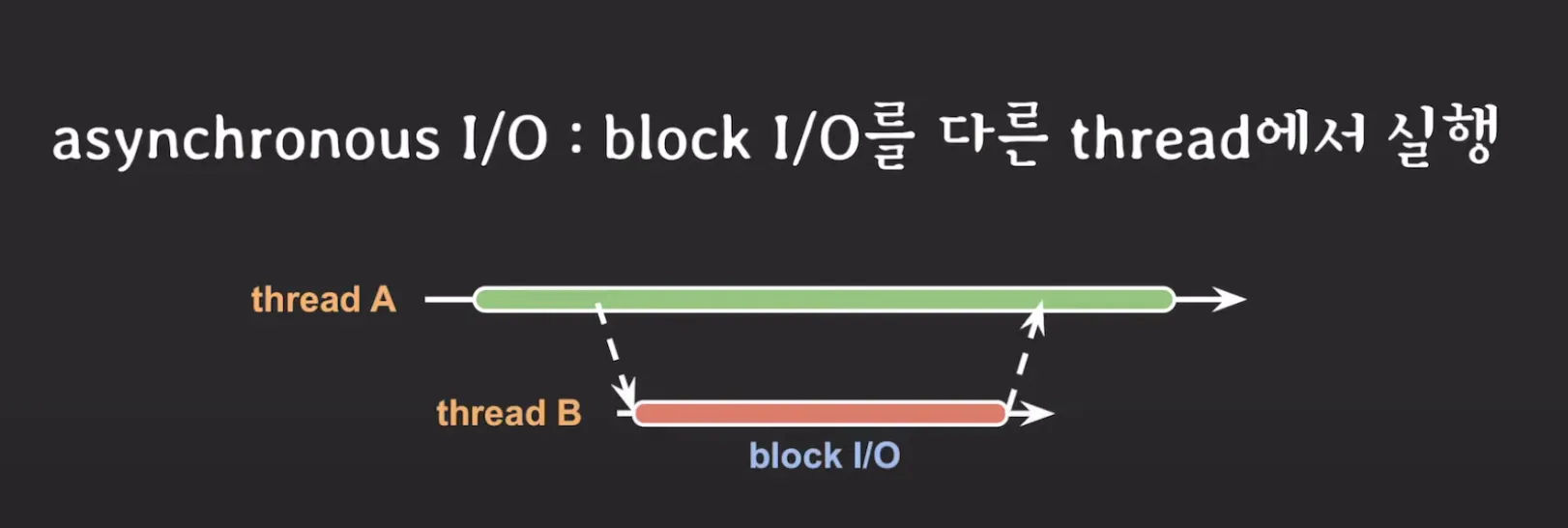
image from 쉬운코드, https://www.youtube.com/watch?v=EJNBLD3X2yg
나. Non Blocking I/O 이점(vs. Blocking)
•
요청 처리 스레드를 대기(Block)시키지 않기 때문에 스레드 간 Context Switching 비용을 최소화할 수 있습니다.
이하 이미지와 같이 두 개의 사용자 요청이 발생할 때, Blocking 방식이라면 두 개의 요청 처리 스레드가 필요합니다. 스레드의 대기 시간이 길어지면 OS의 Scheduler가 해당 스레드가 점유하고 있는 CPU Time을 해지하고 다른 스레드에게 넘겨줍니다. 이러한 과정을 위해 Context Switching이 발생하는데, 스레드의 상태를 저장하고 불러오는 과정에서 성능 상 비용이 발생합니다. 반면 Non Blocking 방식이라면 한 개의 스레드로도 복수의 사용자의 요청을 모두 처리할 수 있기 때문에 Context Switching 비용이 최소화할 수 있습니다.
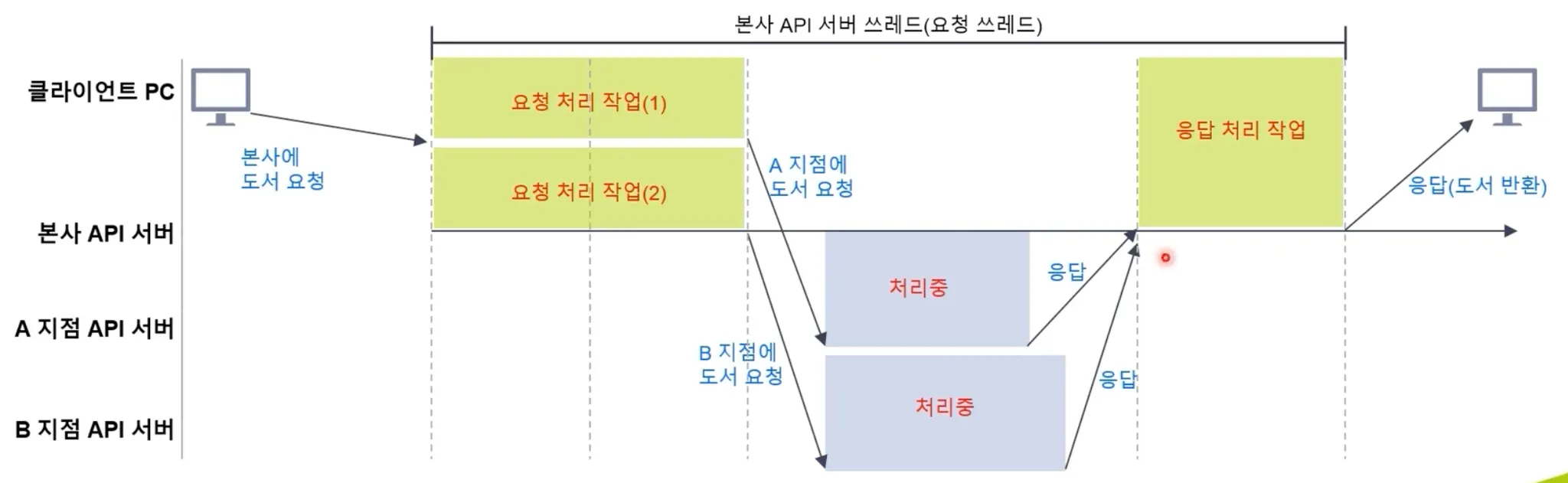
•
대규모 동시 요청에 따라 발생하는 메모리 이슈에서 자유롭습니다.
Blocking 방식에서는 하나의 사용자 요청에 대해 하나의 스레드를 할당시키기 때문에 사용자의 동시 요청수에 비례하여 메모리를 할당해야 합니다. 예를 들어, 동시 접속자 수가 5만명이라면 50GB의 추가 메모리가 필요합니다. 반면 Non Blocking 방식은 적은 수의 스레드로도 다수의 동시 요청을 처리할 수 있기 때문에 메모리 이슈에서 자유롭습니다.
•
요청 처리 스레드 관리에 따른 응답 지연 가능성이 낮습니다.
Blocking I/O의 스레드 풀에 사용 가능한 스레드가 없을 경우, 응답 지연 발생합니다. 더불어 스레드 풀에 스레드를 반납하더라도 다시 사용 가능하도록 전환하는 과정에서 응답 지연이 발생합니다. Non Blocking 방식의 경우, 요청 처리 스레드가 I/O 작업을 기다리는 동안 차단되지 않고 즉시 응답하기 때문에 응답 지연 가능성이 낮습니다.
다. Non Blocking I/O 단점(vs. Blocking)
•
비동기 논블락킹 방식으로 실행되기 때문에 코드 작성 및 디버깅이 실행 흐름이 직관적이지 않습니다. 만약 하나의 요청에서 세 개의 외부 API를 호출하는 상황에서 네트워크 통신 예외가 발생한다면 어떤 API가 원인인지 찾기 어렵습니다. 왜냐하면 각각의 API 호출 처리가 순차적이지 않기 때문입니다.
•
Blocking과 Non Blocking 방식이 섞여 있으면 Non Blocking 방식의 이점을 발휘할 수 없습니다. 이벤트루프가 스레드가 블락되면 다른 io처리도 블락되기 때문입니다.
•
CPU Bound 작업의 경우 성능 상 이점이 없습니다. 이벤트 루프가 블락되기 때문입니다.
2. WebFlux 개요
가. 기초 개념
•
Reactive System: 클라이언트의 요청에 대한 높은 반응성에 중점을 두고 설계된 시스템입니다. Reactive System은 Reactive Manifesto에 따라 다음의 네 가지 설계적 특징이 있습니다. 즉각적이고 안정적인 응답 속도를 유지(Responsive)하고, 결합 발생에도 빠르게 회복(Resilient)되고, 높은 트래픽에도 유연(Elastic)하며, 비동기 메시지 통신에 의존(Message Driven)합니다.
•
Reactive Programming: Reactive System을 구축하기 위한 프로그래밍 모델입니다. Reactive Programming은 다음의 세 가지 특징이 있습니다. 데이터 소스에 변경이 있을 때마다 데이터를 전파하고, 선언형 프로그래밍 기법을 사용하며, 함수형 패러다임을 따릅니다.
•
Reactive Streams: Reactive Programming의 명세로, Non blocking Back Pressure를 활용하여 Data Stream을 Async 처리하기 위한 표준입니다. Reactive Streams의 구현체로 Reactor, RxJava, Java 9 Flow API 등이 있습니다.
•
Data Stream: 시간의 흐름에 따라 연속적으로 발생하는 데이터 또는 이벤트 시퀀스입니다.
•
Spring Reactive Stack: 대규모 동시 요청을 효과적으로 처리하기 위해 요청부터 응답까지의 전 과정을 non blocking 방식으로 처리하는 스프링 기술 집합입니다. 데이터 접근 기술, 보안 기술, 서버 엔진(기본 Netty), 프레임워크 등에서 Spring MVC Stack과 차이가 있습니다.
•
Spring WebFlux: Spring Reactive Stack의 non blocking 웹 어플리케이션 프레임워크입니다.
나. Non Blocking 처리 흐름
•
요청 핸들러 스레드가 사용자 요청을 받으면 요청 이벤트를 이벤트 큐에 푸시합니다.
•
이벤트 루프 스레드는 이벤트 큐에서 이벤트 꺼내고, 논블락킹 방식으로 처리합니다. 콜백을 등록합니다.
•
각 요청의 내부 작업이 완료되면 이벤트 큐에 작업 완료 이벤트가 푸시됩니다.
•
이벤트 루프가 작업 완료 이벤트를 꺼내고, 콜백 함수를 호출합니다.
•
콜백 함수 호출에 따라 요청 핸들러 스레드는 사용자에게 응답을 전달합니다.
다. WebFlux 적합한 시스템
•
적합 - 마이크로 서비스 기반 시스템
동시성: 비동기 논블로킹 I/O 모델을 사용하여 많은 요청을 동시에 처리할 수 있습니다. 이는 마이크로 서비스 아키텍처에서 서비스 간의 통신이 빈번할 때 매우 유리합니다. Spring MVC는 각 요청에 대해 스레드를 할당하고, 블로킹 I/O 작업이 끝날 때까지 대기합니다. 이는 많은 요청을 처리할 때 스레드가 부족해지거나 성능이 저하될 수 있습니다.
자원 관리: 적은 수의 스레드로 많은 요청을 처리할 수 있어 CPU와 메모리 사용이 최적화됩니다. OS는 적은 스레드로 더 많은 작업을 수행할 수 있어, 스레드 관리 오버헤드가 줄어듭니다. Spring MVC는 스레드당 요청 처리 방식으로 인해 더 많은 메모리와 CPU 자원을 소비하게 됩니다.
확장성: 비동기 작업을 통해 각 마이크로 서비스가 독립적으로 확장 가능하여, 전체 시스템의 확장성이 크게 향상됩니다. Spring MVC는 스레드 풀 크기를 늘려야만 확장할 수 있으며, 이는 한계가 있습니다.
•
적합 - 스트리밍 또는 실시간 시스템에 Spring WebFlux를 사용할 경우 어떤 이점을 기대할 수 있는가?
실시간 처리: 비동기 스트림을 통해 데이터를 즉시 처리하고 전달할 수 있습니다. 이는 실시간 채팅, 주식 거래 등과 같은 시스템에서 중요한 역할을 합니다. Spring MVC는 블로킹 I/O로 인해 실시간 데이터 처리에서 지연이 발생할 수 있습니다.
지연 시간: 비동기 모델로 인해 데이터를 처리하고 응답하는 시간이 짧아져, 사용자 경험이 향상됩니다. 동기 처리 방식으로 인해 각 요청이 완료될 때까지 대기해야 하므로, 전반적인 지연 시간이 길어질 수 있습니다.
자원 사용: 스트리밍 데이터를 처리할 때 블로킹 없이 지속적으로 데이터를 전달할 수 있어, 자원의 사용이 최적화됩니다. 스트리밍 데이터를 처리할 때, 각 요청이 블로킹 되므로 더 많은 스레드가 필요하며, 이는 자원 낭비로 이어질 수 있습니다.
•
적합 - 네트워크 접속이 느린 클라이언트의 요청이 빈번한 시스템에 WebFlux를 사용할 경우 어떤 이점을 기대할 수 있는가?
비동기 처리: 네트워크가 느린 클라이언트의 요청을 비동기적으로 처리하여, 스레드가 차단되지 않고 다른 작업을 계속할 수 있습니다. Spring MVC는 요청을 블로킹 방식으로 처리하므로, 네트워크가 느린 클라이언트가 많을 경우 스레드가 차단되어 전체 시스템 성능이 저하될 수 있습니다.
처리량: 느린 네트워크 상태에서도 많은 수의 요청을 동시에 처리할 수 있어, 서버의 처리량이 높아집니다. 동기 방식으로 인해 스레드가 요청 대기 상태로 오래 머물러야 하므로, 서버의 처리량이 감소합니다.
서버 안정성: 비동기 모델은 네트워크 지연으로 인한 스레드 차단을 방지하여, 서버의 안정성을 유지합니다. 네트워크 지연이 많은 경우, 블로킹 스레드가 쌓여 서버가 불안정해질 수 있습니다.
•
부적합 - CPU Bound 시스템에 Spring WebFlux는 왜 성능 상 큰 이점이 없는가?
CPU Bound 애플리케이션에서는 Spring MVC가 더 적합할 가능성이 높습니다. 각 요청이 별도의 스레드에서 처리되므로 CPU 자원을 최대한 활용할 수 있습니다. 반면, Spring Webflux의 비동기 및 논블로킹 접근 방식은 CPU 사용률을 최적화하기보다는 I/O 대기 시간 최소화에 더 초점을 맞추고 있습니다. 따라서 계산 집중적인 작업이 주된 애플리케이션에는 Spring MVC가 더 효과적인 선택일 수 있습니다. 이벤트루프 스레드가 비지니스 로직을 처리하므로 CPU Time이 많이 소모되는 작업이 할당되면, 블락킹되어 다른 io 처리가 지연될 수 있습니다.
3. Reactor 개요
가. 기초 개념
•
Reactor: 스프링 진영에서 개발한 JVM 기반의 Reactive Streams의 구현체입니다.
•
Publisher: Reactive Streams의 주요 인터페이스로, 데이터를 Sequence의 형태로 발행합니다. Reactor의 Publisher는 Mono와 Flux가 있습니다.
•
Subscriber: Reactive Streams의 주요 인터페이스로, Sequence 형태의 데이터를 받아서 처리합니다. Subscriber는 Sequence의 subscribe 함수의 람다 표현식으로 사용됩니다.
•
Sequence: Publisher가 발행하는 데이터의 연속적인 흐름입니다. Operator의 체인 형태로 정의됩니다.
•
Operator: Reactor에서 Sequence를 처리하는 연산자입니다. 자바 스트림의 연산자와 유사합니다.
나. 핵심 프로세스
•
Publisher가 Sequence를 발행합니다.
•
Operator를 활용해서 Sequence를 가공합니다.
•
가공된 데이터를 Subscriber에 전달합니다.
4. Publisher 개요
가. 기초 개념
•
Mono: 0~1개의 데이터를 emit하는 Publisher입니다. HTTP 요청에 대한 응답을 받아서 처리할 때 주로 사용합니다.
•
Flux: 0~N개의 데이터를 emit하는 Publisher입니다. Publisher를 concat 연산자로 합쳐서 Sequence를 발행할 수 있습니다.
나. Mono 핵심 프로세스
•
예제 코드 해석: Mono.empty()는 비어있는 Sequence를 발행합니다. 가공할 데이터가 없으므로, subscribe의 세 번째 람다 표현식(completion)이 실행됩니다.
public class MonoSample {
public static void main(String[] args) {
Mono.empty() // empty는 0개의 sequence를 발행하는 연산자
.subscribe( // empty operator 기준 downstream
data -> Logger.info("# emitted data: {}", data),
error -> {},
() -> Logger.info("# emitted onComplete signal")
);
}
}
Java
복사
•
마블 다이어그램: 타임라인을 기반으로 Sequence의 정상, 실패, 성공 처리를 표현합니다.
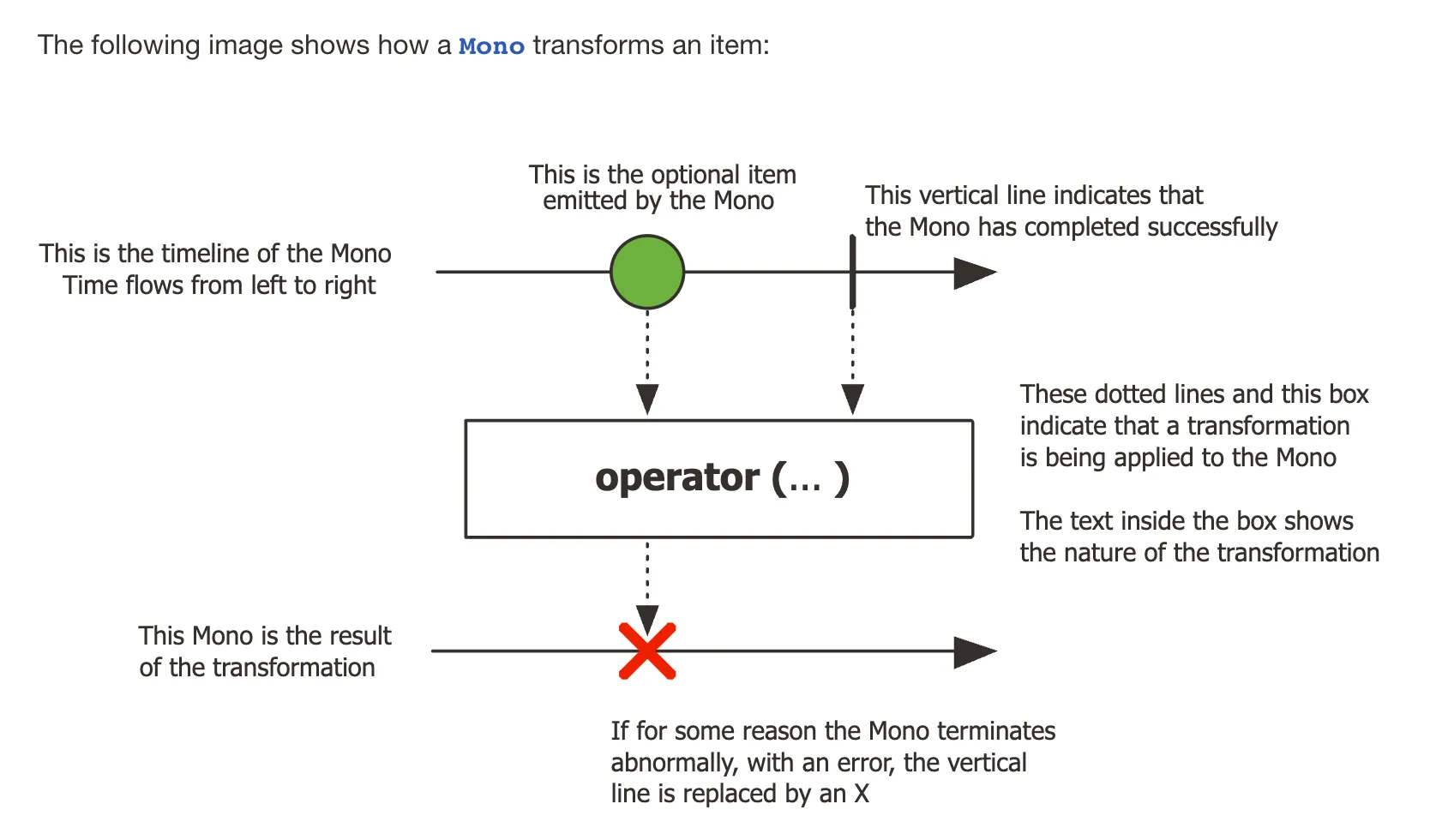
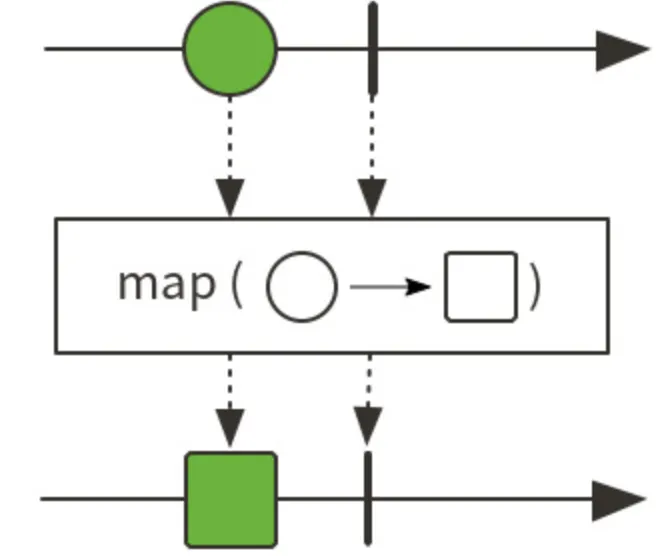
image from https://gngsn.tistory.com/226
다. Flux 핵심 프로세스
•
예제 해석: Flux Publisher의 sequence를 합쳐서 List 컬렉션 타입의 sequence로 구성하여 발행합니다.
public class FluxExample04 {
public static void main(String[] args) {
Flux.concat(
Flux.just("Venus", "Sun"),
Flux.just("Earth"),
Flux.just("Mars"))
.collectList()
.subscribe(planetList -> Logger.info("# Solar System: {}", planetList));
}
}
Java
복사
•
마블 다이어그램: Mono와 달리 Flux는 복수의 아이템으로 구성된 Sequence에 대한 정상, 실패, 성공 처리를 표현합니다.
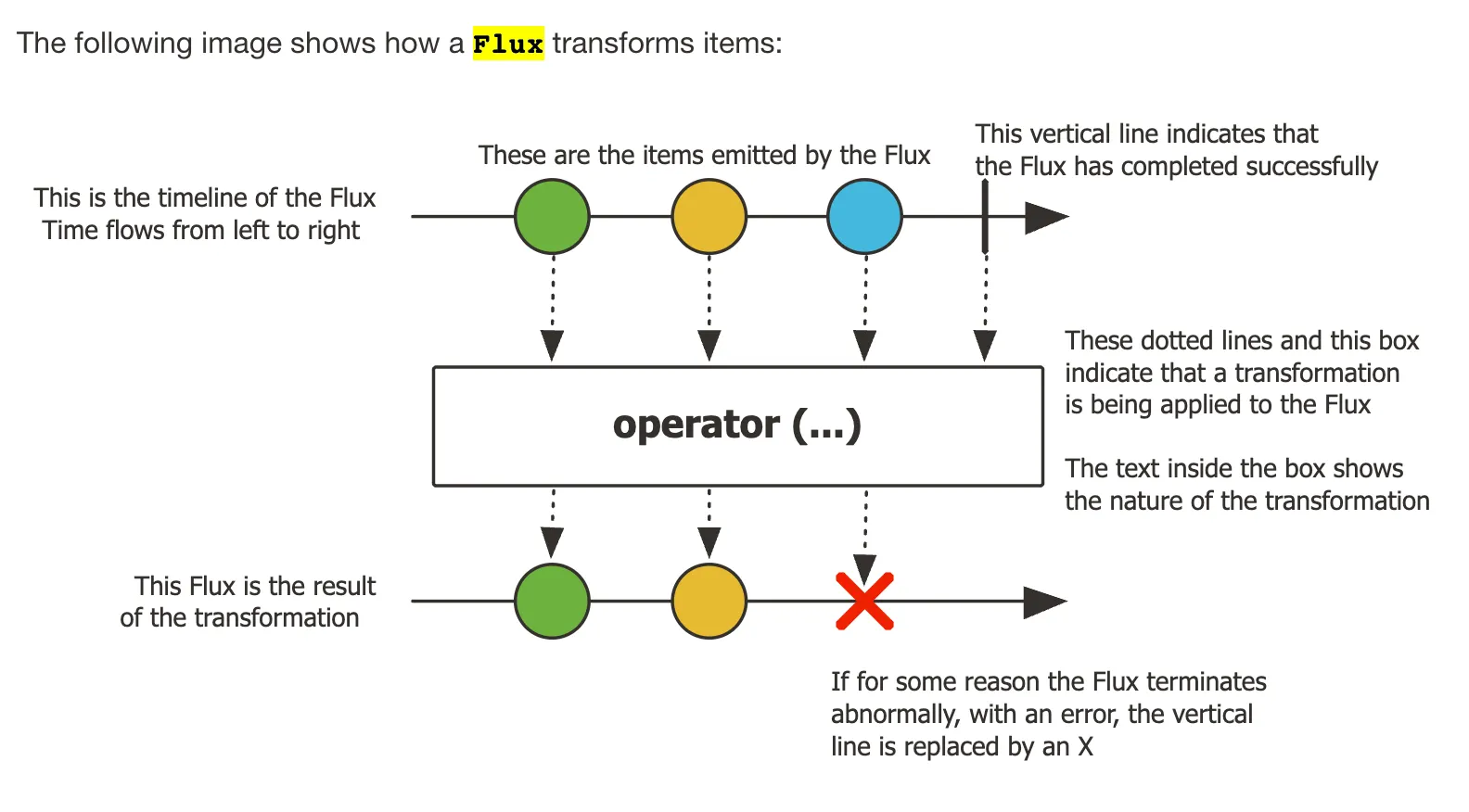
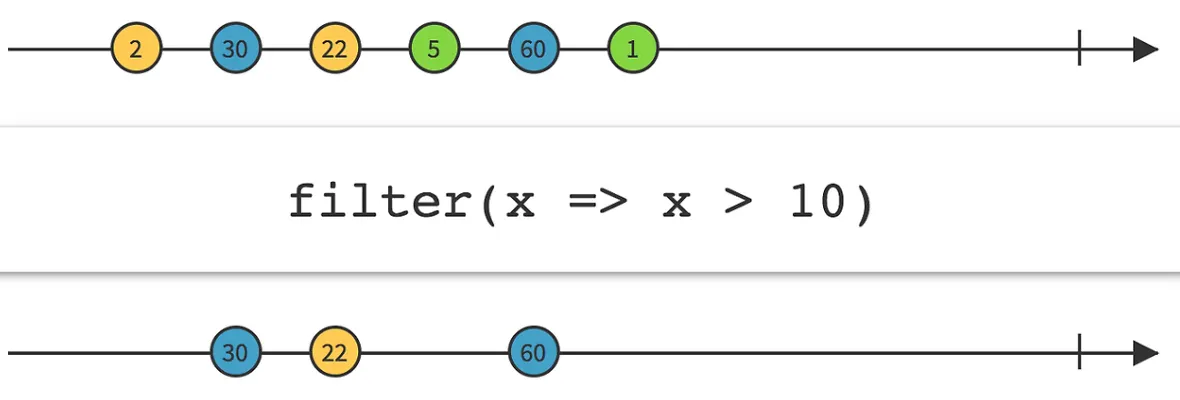
image from https://gngsn.tistory.com/226
라. Mono, Flux 예시코드
@RestController
public class AppController {
private final UserRepository userRepository;
public AppController(UserRepository userRepository) {
this.userRepository = userRepository;
}
// 모든 사용자 정보 반환
@GetMapping("/users")
public Flux<User> getAllUsers() {
return userRepository.findAll();
}
// 특정 ID의 사용자 정보 반환
@GetMapping("/user/{id}")
public Mono<User> getUserById(@PathVariable String id) {
return userRepository.findById(id);
}
// 뉴스 이벤트를 실시간 스트리밍
@GetMapping(path = "/news", produces = "text/event-stream")
public Flux<ServerSentEvent<String>> streamNews() {
return Flux.interval(Duration.ofSeconds(1)) // 1초 간격으로 이벤트 발생
.map(seq -> ServerSentEvent.<String>builder()
.id(String.valueOf(seq))
.event("news-event")
.data("News update at " + new Date())
.build());
}
}
Java
복사
5. Sequence 개요
가. 기초 개념
•
Cold Sequence: Subscriber가 구독한 시점과 관계없이 Publisher가 emit한 모든 데이터가 포함되어 있습니다.
•
Hot Sequence: Publisher가 emit한 데이터 중 Subscriber가 구독한 시점 이후의 데이터만 포함되어 있습니다. share 연산자로 hot sequence를 만들 수 있습니다.
나. 데이터 흐름 비교
•
Cold Sequence 예제 코드: 구독 시점과 관계 없이 모든 데이터가 포함되어 있기 때문에 ‘red’, ‘yellow’, ‘pink’를 두 번 출력합니다.
public class ColdSequenceExample {
public static void main(String[] args) {
Flux<String> coldFlux = Flux.fromIterable(Arrays.asList("RED", "YELLOW", "PINK"))
.map(String::toLowerCase);
coldFlux.subscribe(country -> Logger.info("# Subscriber1: {}", country));
Logger.info("-------------------------");
coldFlux.subscribe(country -> Logger.info("# Subscriber2: {}", country));
}
}
Java
복사
•
Hot Sequence: share 연산자로 concertFlux는 hot sequence로 생성합니다. 첫 번째 publisher는 모든 singer를 출력하지만, 두 번재 publisher는 중간의 singer부터 출력합니다.
public class HotSequenceExample {
public static void main(String[] args) {
Flux<String> concertFlux =
Flux.fromStream(Stream.of("Singer A", "Singer B", "Singer C", "Singer D", "Singer E"))
.delayElements(Duration.ofSeconds(1)).share(); // share() 원본 Flux를 여러 Subscriber가 공유한다.
concertFlux.subscribe(singer -> Logger.info("# Subscriber1 is watching {}'s song.", singer));
TimeUtils.sleep(2500);
concertFlux.subscribe(singer -> Logger.info("# Subscriber2 is watching {}'s song.", singer));
TimeUtils.sleep(3000);
}
}
Java
복사
6. Backpressure 개요
가. 기초 개념
•
Back Pressure: Subscriber의 데이터 처리 역량에 따라 데이터의 흐름을 제어하는 기능입니다. Subscriber의 데이터 처리 역량 보다 Publisher가 더 많은 데이터를 발행할 때, Back Pressure가 동작하여 데이터의 양을 제어합니다.
나. Publisher와 Subscriber 통신 프로세스
•
onSubscribe: 통신의 시작을 알리는 신호입니다. Subscriber가 Publisher를 구독할 때, Publisher는 Subscriber에게 Subscription 객체를 전달하는 onSubscribe 신호를 보냅니다. 이 Subscription 객체를 통해 Subscriber는 요청(request)을 보내거나 구독을 취소(cancel)할 수 있습니다.
•
onNext: 데이터 항목을 Subscriber에게 전달할 때 사용되는 신호입니다. Publisher는 Subscriber로부터 받은 요청(request(n))에 따라 데이터를 보낼 수 있으며, 이 때 각 데이터 항목은 onNext 메소드를 통해 전달됩니다. Subscriber는 onNext를 통해 전달받은 데이터를 처리합니다.
•
onError: 에러 처리를 위한 신호입니다. 데이터 처리 과정에서 에러가 발생하면, Publisher는 onError 신호를 보내어 Subscriber에게 에러 상황을 알립니다. 이 신호가 전달되면 스트림은 종료되며, 더 이상의 onNext 또는 onComplete 신호는 발생하지 않습니다.
•
onComplete: 스트림이 성공적으로 완료되었음을 알리는 신호입니다. 모든 데이터가 정상적으로 처리되었을 때, Publisher는 onComplete 신호를 보내어 데이터 스트림의 종료를 알립니다. 이 신호가 전송된 후에는 더 이상의 onNext 신호가 발생하지 않습니다.

다. Backpressure 기본 원리
•
Subscriber가 현재 처리할 수 있는 데이터의 수를 Publisher에게 지속 공유합니다.
•
(Subscriber → Publisher) Subscriber에서 처리 가능한 데이터의 개수를 Publisher에게 공유합니다.
•
(Publisher → Subscriber) Publisher에서는 처리 가능 데이터 만큼만 Subscriber에게 emit합니다.
라. Backpressure 전략
•
BUFFER 전략: 버퍼가 가득 찬 이후로 emit되는 데이터를 일단 버퍼 내 저장하여 오버플로우를 발생시킵니다. 이후 버퍼 내의 데이터를 폐기합니다. BUFFER DROP-LATEST 전략의 경우, 버퍼에 가장 마지막에 들어온 데이터를 제거합니다. 반면 BUFFER DROP-OLD 전략은 가장 오래된 데이터를 제거합니다.
순간적인 데이터 처리 폭주가 예상되지만, 이후에 소비자가 이를 따라잡을 수 있는 경우와 시스템에 메모리 여유가 많아 일시적인 데이터 폭주를 감당할 수 있을 때 적용할 수 있습니다.
•
DROP 전략: 버퍼가 가득한 찬 이후로 emit되는 데이터는 버퍼 밖에서 즉시 폐기됩니다. 버퍼가 빈 시점부터 데이터를 버퍼에 저장합니다. 실시간 센서 데이터 스트림에서 최신 상태 정보만 중요할 때. 비즈니스 로직상 일부 데이터 유실이 서비스에 큰 영향을 미치지 않을 때 적용할 수 있습니다.
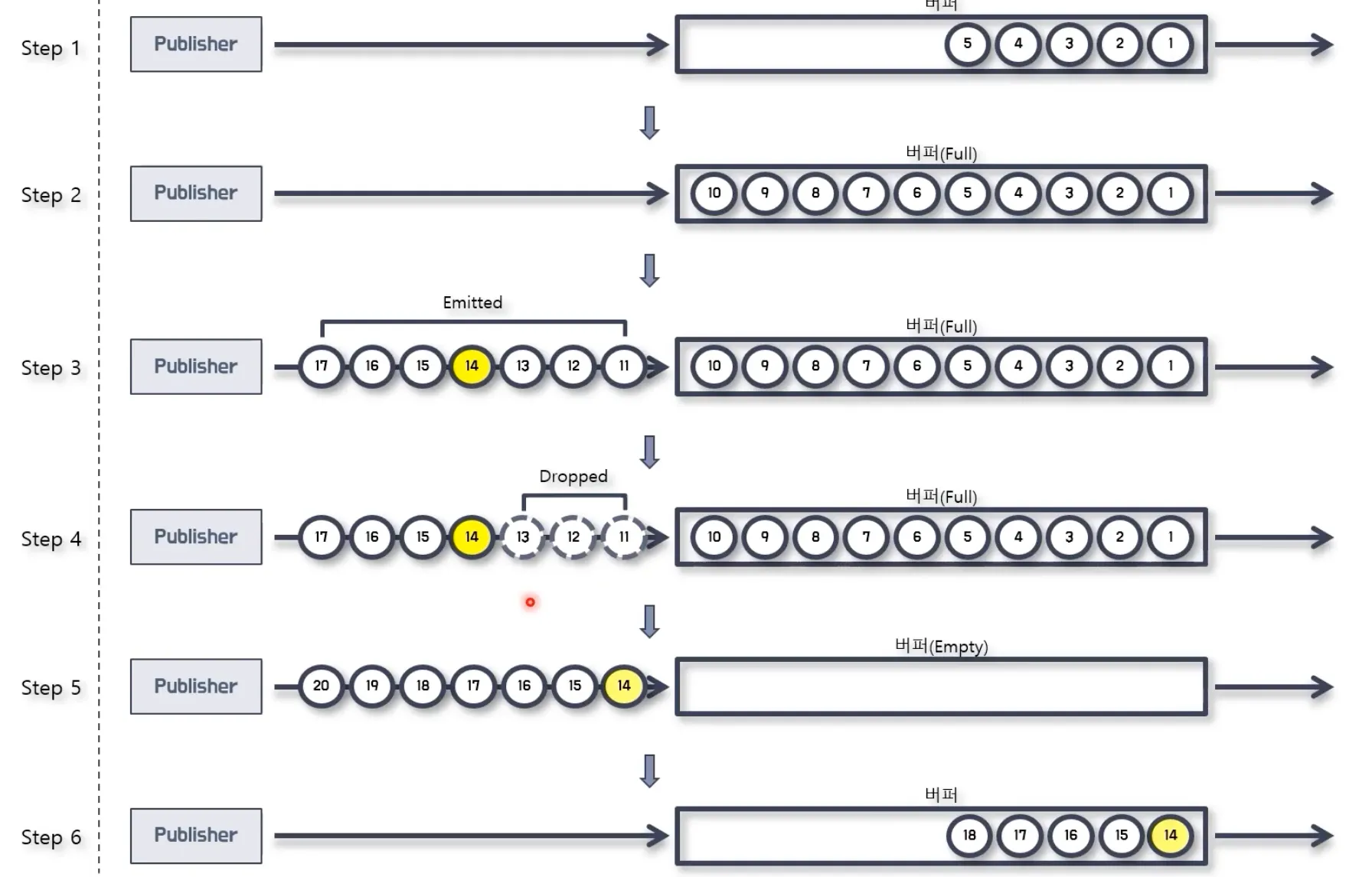
•
LATEST 전략: 버퍼가 가득한 찬 이후로 emit되는 데이터는 버퍼 밖에서 폐기됩니다. 단, 버퍼 밖에서 대기하는 데이터가 하나라면 즉시 폐기되지 않고 그 이후로 들어오는 데이터가 있을 시 첫 번째 대기 데이터가 폐기됩니다. 버퍼가 빈 시점부터 데이터를 폐기하지 않고 버퍼에 저장합니다. 최신 상태 정보가 중요하고 이전 데이터가 필요 없는 경우(예: 최신 주식 가격, 실시간 게임 상태) 또는 최신 정보만 필요로 하는 사용자 인터페이스 업데이트 등에 적용할 수 있습니다.

•
ERROR 전략: Downstream으로 전달할 데이터가 버퍼에 가득 찰 결우, Exception을 발생 시킵니다. 모든 데이터를 처리해야 하며, 데이터 유실이 허용되지 않는 경우. 시스템 과부하를 피하기 위해 빠르게 실패하고 재시도할 수 있도록 설계된 경우 적용할 수 있습니다.
7. Sinks 개요
가. 기초 개념
•
Sinks: signal을 동적으로 제어(push)할 수 있는 publisher입니다. 멀티쓰레딩 환경에서 Thread Safe하게 동작하므로 Processor(Thread Safe X)의 대안이 됩니다.
나. Sinks 생성
•
Sinks 인터페이스 활용: Operator 내외부에서 모두 emit 할 수 있습니다. 더불어 EmitFailureHandler 제공에 따라 멀티 쓰레딩 환경에서 에러 핸들링을 할 수 있습니다.
public class ProgrammaticSinksExample01 {
public static void main(String[] args) throws InterruptedException {
int tasks = 6;
Sinks.Many<String> unicastSink = Sinks.many().unicast().onBackpressureBuffer();
Flux<String> fluxView = unicastSink.asFlux();
IntStream
.range(1, tasks)
.forEach(n -> {
try {
new Thread(() -> {
unicastSink.emitNext(doTask(n), Sinks.EmitFailureHandler.FAIL_FAST);
log.info("# emitted: {}", n);
}).start();
Thread.sleep(100L);
} catch (InterruptedException e) {}
});
fluxView
.subscribe(data -> log.info("# onNext: {}", data));
Thread.sleep(200L);
}
private static String doTask(int taskNumber) {
return "task " + taskNumber + " result";
}
}
Java
복사
•
create operator 활용: Operator 내부에서만 emit 할 수 있습니다.
public class ProgrammaticCreateExample01 {
public static void main(String[] args) throws InterruptedException {
int tasks = 6;
Flux
.create((FluxSink<String> sink) -> {
IntStream
.range(1, tasks)
.forEach(n -> sink.next(doTask(n)));
})
.subscribe(data -> log.info("# onNext: {}", data));
Thread.sleep(500L);
}
private static String doTask(int taskNumber) {
return "task " + taskNumber + " result";
}
}
Java
복사
다. Sinks.One vs Sinks.Many
•
Sinks.One: 단 하나의 데이터만 emit할 수 있고, Mono와 유사합니다. 두 개 이상의 데이터를 emit할 때, 에러를 발생시킬 수 있습니다.
public class SinkOneExample02 {
public static void main(String[] args) {
// emit 된 데이터 중에서 단 하나의 데이터만 Subscriber에게 전달한다. 나머지 데이터는 Drop 됨.
Sinks.One<String> sinkOne = Sinks.one();
Mono<String> mono = sinkOne.asMono();
sinkOne.emitValue("Hello Reactor", FAIL_FAST);
// Sink.One 은 단 한개의 데이터를 emit 할 수 있기때문에 두번째 emit한 데이터는 drop 된다.
sinkOne.emitValue("Hi Reactor", FAIL_FAST);
mono.subscribe(data -> Logger.onNext("Subscriber1 ", data));
mono.subscribe(data -> Logger.onNext("Subscriber2 ", data));
}
}
/* 출력 결과
21:04:42.597 [main] DEBUG reactor.core.publisher.Operators - onNextDropped: Hi Reactor
21:04:42.598 [main] INFO com.itvillage.utils.Logger - # Subscriber1 onNext(): Hello Reactor
21:04:42.598 [main] INFO com.itvillage.utils.Logger - # Subscriber2 onNext(): Hello Reactor
*/
Java
복사
•
Sinks.Many: 여러 데이터를 emit 할 수 있고, Flux와 유사합니다.
public class SinkManyExample02 {
public static void main(String[] args) {
// 하나 이상의 Subscriber에게 데이터를 emit할 수 있다.
Sinks.Many<Integer> multicastSink = Sinks.many().multicast().onBackpressureBuffer();
Flux<Integer> fluxView = multicastSink.asFlux();
multicastSink.emitNext(1, FAIL_FAST);
multicastSink.emitNext(2, FAIL_FAST);
fluxView.subscribe(data -> Logger.onNext("Subscriber1", data));
fluxView.subscribe(data -> Logger.onNext("Subscriber2", data));
multicastSink.emitNext(3, FAIL_FAST);
}
}
/* 출력 결과
21:09:06.700 [main] INFO com.itvillage.utils.Logger - # Subscriber1 onNext(): 1
21:09:06.701 [main] INFO com.itvillage.utils.Logger - # Subscriber1 onNext(): 2
21:09:06.701 [main] INFO com.itvillage.utils.Logger - # Subscriber1 onNext(): 3
21:09:06.701 [main] INFO com.itvillage.utils.Logger - # Subscriber2 onNext(): 3
*/
Java
복사
public class SinkManyExample04 {
public static void main(String[] args) {
// 구독 이후, emit된 데이터 중에서 최신 데이터 2개만 replay 한다.
Sinks.Many<Integer> replaySink = Sinks.many().replay().limit(2);
Flux<Integer> fluxView = replaySink.asFlux();
replaySink.emitNext(1, FAIL_FAST);
replaySink.emitNext(2, FAIL_FAST);
replaySink.emitNext(3, FAIL_FAST);
fluxView.subscribe(data -> Logger.onNext("Subscriber1", data));
replaySink.emitNext(4, FAIL_FAST);
fluxView.subscribe(data -> Logger.onNext("Subscriber2", data));
}
}
/* 출력 결과
21:08:30.029 [main] INFO com.itvillage.utils.Logger - # Subscriber1 onNext(): 2
21:08:30.030 [main] INFO com.itvillage.utils.Logger - # Subscriber1 onNext(): 3
21:08:30.030 [main] INFO com.itvillage.utils.Logger - # Subscriber1 onNext(): 4
21:08:30.030 [main] INFO com.itvillage.utils.Logger - # Subscriber2 onNext(): 3
21:08:30.030 [main] INFO com.itvillage.utils.Logger - # Subscriber2 onNext(): 4
*/
Java
복사
라. Sinks.Many 활용
•
multicast 모드에서 Sinks.Many는 구독 시점 이후에 발생하는 데이터만 구독자에게 전달합니다. 이는 실시간으로 데이터를 전달받고자 할 때 유용합니다. 즉, 구독 시점 이전에 발생한 데이터는 새로운 구독자에게 전달되지 않습니다.
실시간 뉴스 피드, 주식 가격 업데이트 등과 같이 최신 데이터만 중요하고, 구독자가 구독을 시작한 이후 발생한 데이터만 필요로 하는 경우에 적합합니다.
•
replay 모드에서는 Sinks.Many가 발생한 모든 데이터 또는 설정된 크기만큼의 최근 데이터를 새 구독자에게 전달합니다. 이 모드는 모든 데이터 또는 최근 데이터를 구독자에게 다시 제공할 수 있습니다.
채팅 애플리케이션의 메시지 히스토리, 과거의 주요 이벤트를 확인할 필요가 있는 분석 도구 등과 같이 이전 데이터가 여전히 유용하거나 필요한 경우에 적합합니다.
8. Scheduler
가. 기초 개념
•
Scheduler: 특정 스레드에서 실행될 작업을 관리하고 예약하는 역할을 담당합니다.
•
Parallel 연산자: runOn 연산자와 함께 사용되어 여러 스레드에 걸쳐 데이터를 병렬로 처리할 수 있습니다.
•
publishOn 연산자: 연산자 체인의 downstream에서 스레드를 전환하는 데 사용됩니다.
•
subscribeOn 연산자: 연산자 체인의 시작점부터 특정 스레드를 지정하여 작업을 실행할 때 사용됩니다.
나. publishOn & subscribeOn 동작
•
publishOn 기본 동작
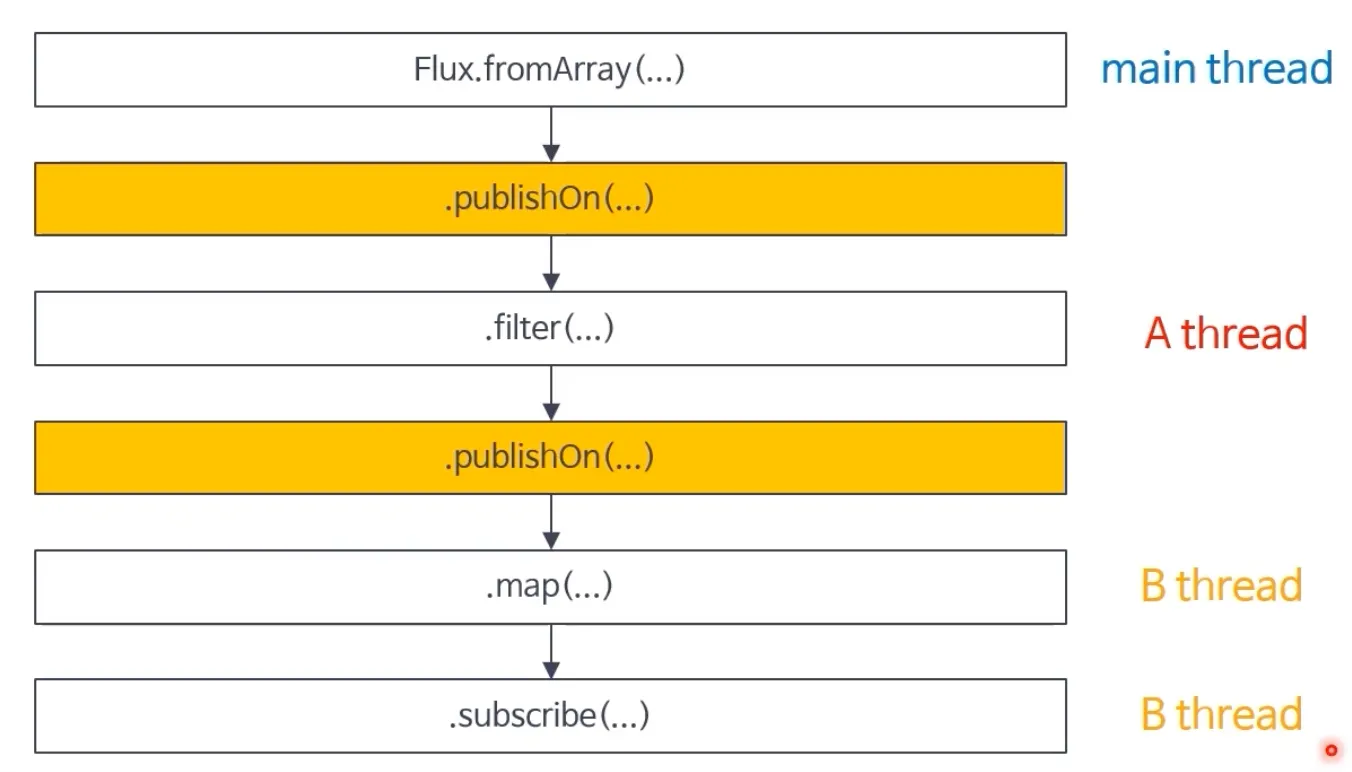
•
subscribeOn 기본 동작

•
publishOn & subscribeOn 동작 1
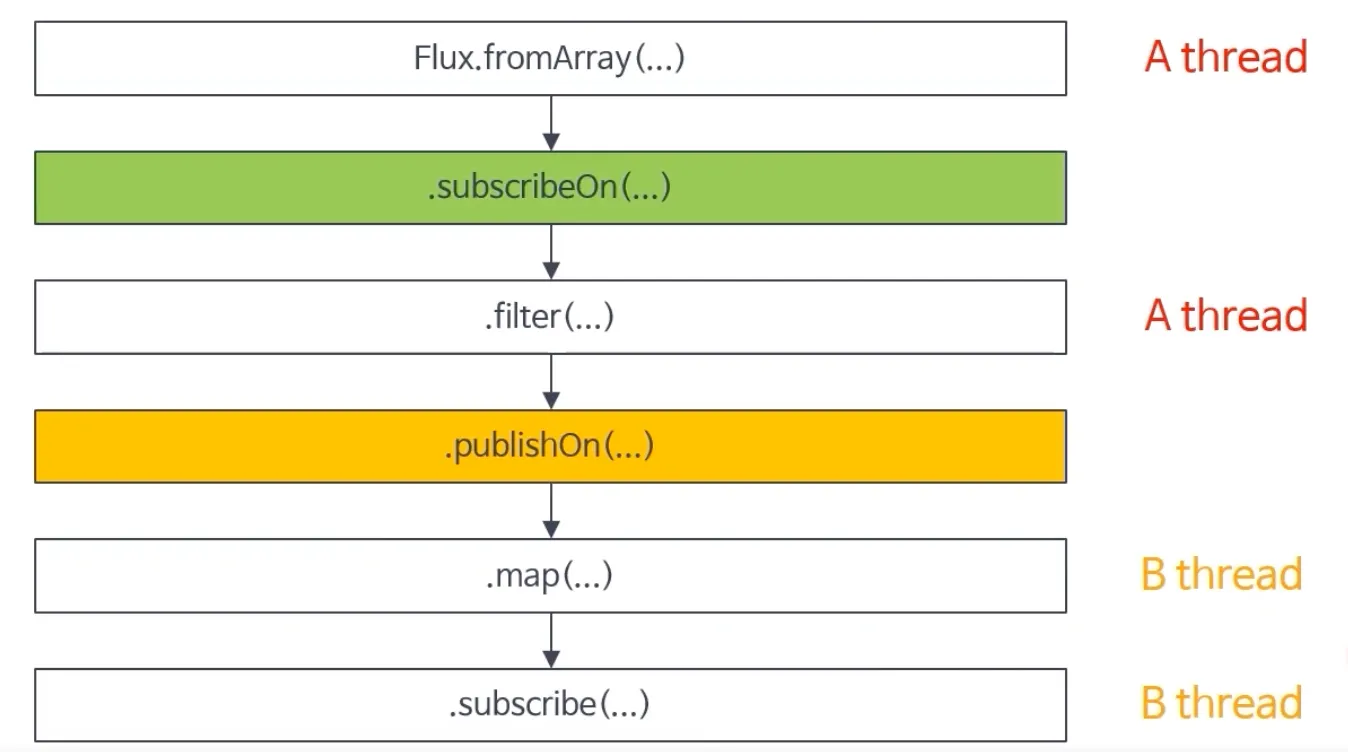
•
publishOn & subscribeOn 동작 2
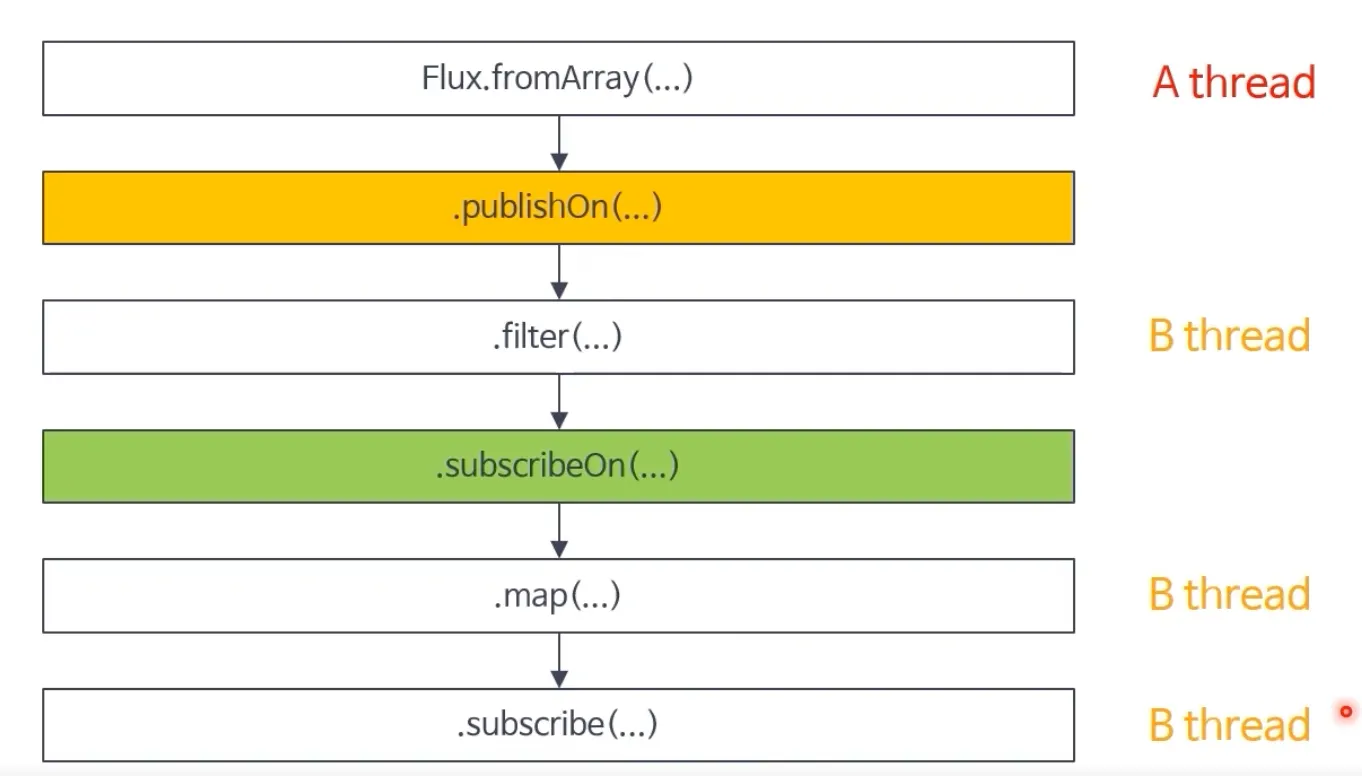
다. Scheduler 종류 및 동작
•
Single: 모든 구독에 대해 스레드 하나를 생성해서 재사용합니다.
•
newSingle: 각각의 구독에 대해 전용 스레드를 생성합니다. 각각의 구독별로 작업 부하를 고립시킬 때 사용하기 적합합니다.
•
BoundedElastic: 스레드의 수를 제한하고, 작업량에 따라 확장됩니다. I/O 작업에 유용합니다.
•
newBoundedElastic: BoundedElastic과 유사하지만 추가적인 옵션을 적용할 수 있습니다.
•
Parallel: 병렬 작업에 대해 스레드 풀 개념을 적용하여 동시 작업에 적용할 수 있습니다.
•
newParallel: Parallel과 비슷하지만 구체적인 스레드의 숫자를 조정하는 등 동시성 수준을 제어할 수 있습니다.
9. Context
가. 기초 개념
•
Context: 별개의 스레드에서도 상태값을 공유할 수 있도록 관리하는 객체입니다. Spring Security에서 사용자 정보가 Static 영역에 Map의 형태로 저장되는 ThreadLocal의 개념과 같은 맥락으로 볼 수 있습니다.
나. Context API
•
Context API는 리액터 프로그래밍에서 컨텍스트를 관리하기 위한 기능을 제공합니다. 이 API를 사용하여 리액티브 스트림 내의 상태를 관리하고 공유할 수 있습니다.
•
Mono나 Flux의 subscriberContext 메소드를 사용하여 Context에 접근하고 값을 설정할 수 있습니다.
다. ContextView API
•
ContextView는 읽기 전용 컨텍스트 뷰를 제공하는 API입니다. 이 API를 통해 현재 컨텍스트의 상태를 조회할 수 있습니다.
•
ContextView를 통해 컨텍스트에 저장된 값을 가져올 수 있으며, 이는 주로 구독 중에 필요한 상태값을 참조하는 데 사용됩니다.
•
ContextView는 컨텍스트의 내용을 안전하게 읽을 수 있도록 보장하며, 컨텍스트를 수정하지 않고 읽기만 할 때 사용됩니다.
라. Context 특징
•
구독마다 하나의 컨텍스트가 생성됩니다. 각 subscriber가 독립적인 상태를 가질 수 있도록 보장합니다. 결과적으로 스레드 안정성을 제공하여, 여러 스레드에서 안전하게 상태값을 접근하고 수정할 수 있습니다.
•
Context를 사용하여 데이터베이스 연결 정보, 사용자 인증 정보, 트랜잭션 정보 등의 다양한 상태값을 리액티브 스트림 전반에 걸쳐 전달하고 관리할 수 있습니다.


라. Schedulers.boundedElastic() 활용
•
블럭킹으로 설계된 외부 API를 호출할 경우,subscribeOn과 Schedulers.boundedElastic()을 사용하면 I/O 바운드 작업이 해당 작업에 적합한 스레드 풀에서 처리합니다. 따라서 Event Loop가 넌블럭킹으로 지속 동작하여 애플리케이션의 전체적인 성능을 향상시킵니다. 논블럭킹으로 설계된 API를 호출한다면 큰 차이가 없습니다.
•
예시 코드
@RestController
public class ApiController {
private WebClient webClient;
public ApiController() {
this.webClient = WebClient.builder()
.baseUrl("http://example.com/api")
.build();
}
@GetMapping("/fetchData")
public Mono<String> fetchData(@RequestParam String userId) {
return Mono.just(userId)
.flatMap(this::simulateExternalCall)
.subscribeOn(Schedulers.boundedElastic())
.contextWrite(Context.of("userId", userId))
.doOnNext(data -> logData(data))
.doOnEach(signal -> logContext(signal.getContextView().get("userId")));
}
private Mono<String> simulateExternalCall(String userId) {
return webClient.get()
.uri(uriBuilder -> uriBuilder.path("/getUserDetails")
.queryParam("id", userId)
.build())
.retrieve()
.bodyToMono(String.class)
.map(response -> "Processed response for User ID: " + userId + " with data: " + response);
}
private void logData(String data) {
System.out.println(Thread.currentThread().getName() + " - " + data);
}
private void logContext(Object userId) {
System.out.println("Current Context User ID: " + userId);
}
}
Java
복사
10. Debugging
가. Debug 모드 활용
•
Hooks.onOperatorDebug() 호출에 따라 Debug 모드 활성화합니다.
•
Operator 체인에서 에러 발생한 Operator의 위치를 확인할 수 있습니다.
•
단 어플리케이션 내 모든 Operator를 캡처하기 때문에 비용이 많이 듭니다. 따라서 최후의 방법으로 활용됩니다.
•
예시 코드
public static void main(String[] args) {
Hooks.onOperatorDebug();
Flux.fromArray(new String[]{"BANANAS", "APPLES", "PEARS", "MELONS"})
.map(String::toLowerCase)
.map(fruit -> fruit.substring(0, fruit.length() - 1))
.map(fruits::get)
.map(translated -> "맛있는 " + translated)
.subscribe(Logger::onNext, Logger::onError);
}
Java
복사
> Task :DebugModeExample04.main()
11:44:51.097 [main] DEBUG reactor.util.Loggers$LoggerFactory - Using Slf4j logging framework
11:44:51.098 [main] DEBUG reactor.core.publisher.Hooks - Enabling stacktrace debugging via onOperatorDebug
11:44:51.148 [main] INFO com.itvillage.utils.Logger - # onNext(): 맛있는 바나나
11:44:51.149 [main] INFO com.itvillage.utils.Logger - # onNext(): 맛있는 사과
11:44:51.149 [main] INFO com.itvillage.utils.Logger - # onNext(): 맛있는 배
11:44:51.156 [main] ERROR com.itvillage.utils.Logger - error happened:
java.lang.NullPointerException: The mapper returned a null value.
at java.base/java.util.Objects.requireNonNull(Objects.java:248)
Suppressed: reactor.core.publisher.FluxOnAssembly$OnAssemblyException:
Assembly trace from producer [reactor.core.publisher.FluxMapFuseable] :
reactor.core.publisher.Flux.map(Flux.java:6020)
com.itvillage.section09.class00.DebugModeExample04.main(DebugModeExample04.java:29)
Error has been observed at the following site(s):
|_ Flux.map ⇢ at com.itvillage.section09.class00.DebugModeExample04.main(DebugModeExample04.java:29)
|_ Flux.map ⇢ at com.itvillage.section09.class00.DebugModeExample04.main(DebugModeExample04.java:30)
Stack trace:
at java.base/java.util.Objects.requireNonNull(Objects.java:248)
Java
복사
나. checkpoint() Operator 활용
•
checkpoint 연산자의 업스트림에서 발생하는 에러를 확인할 수 있습니다. 연산자 체인에서 checkpoint 연산자를 복수 지정하여 원인을 특정할 수 있습니다.
•
예시 코드
public static void main(String[] args) {
Flux.just(2, 4, 6, 8)
.zipWith(Flux.just(1, 2, 3, 0), (x, y) -> x/y)
.checkpoint("CheckpointExample02.zipWith.checkpoint", true)
.map(num -> num + 2)
.checkpoint("CheckpointExample02.map.checkpoint", true)
.subscribe(Logger::onNext, Logger::onError);
}
Java
복사
11:43:53.635 [main] DEBUG reactor.util.Loggers$LoggerFactory - Using Slf4j logging framework
11:43:53.644 [main] INFO com.itvillage.utils.Logger - # onNext(): 4
11:43:53.644 [main] INFO com.itvillage.utils.Logger - # onNext(): 4
11:43:53.644 [main] INFO com.itvillage.utils.Logger - # onNext(): 4
11:43:53.650 [main] ERROR com.itvillage.utils.Logger - error happened:
java.lang.ArithmeticException: / by zero
at com.itvillage.section09.class01.CheckpointExample06.lambda$main$0(CheckpointExample06.java:13)
Suppressed: reactor.core.publisher.FluxOnAssembly$OnAssemblyException:
Assembly trace from producer [reactor.core.publisher.FluxZip], described as [CheckpointExample02.zipWith.checkpoint] :
reactor.core.publisher.Flux.checkpoint(Flux.java:3261)
com.itvillage.section09.class01.CheckpointExample06.main(CheckpointExample06.java:14)
Error has been observed at the following site(s):
|_ Flux.checkpoint ⇢ at com.itvillage.section09.class01.CheckpointExample06.main(CheckpointExample06.java:14)
|_ Flux.checkpoint ⇢ at com.itvillage.section09.class01.CheckpointExample06.main(CheckpointExample06.java:16)
Stack trace:
at com.itvillage.section09.class01.CheckpointExample06.lambda$main$0(CheckpointExample06.java:13)
Java
복사
다. log() Operator 활용
•
Signal Event를 출력하기 때문에 Reactor Sequence에서 이슈의 원인을 특정할 수 있습니다.
•
log 연산자의 카테고리를 활용하여 이슈가 발생한 데이터를 특정할 수 있습니다.
•
예시 코드
public static void main(String[] args) {
Flux.fromArray(new String[]{"BANANAS", "APPLES", "PEARS", "MELONS"})
.subscribeOn(Schedulers.boundedElastic())
.log("Fruit.Source")
.publishOn(Schedulers.parallel())
.map(String::toLowerCase)
.log("Fruit.Lower")
.map(fruit -> fruit.substring(0, fruit.length() - 1))
.log("Fruit.Substring")
.map(fruits::get)
.log("Fruit.Name")
.subscribe(Logger::onNext, Logger::onError);
TimeUtils.sleep(100L);
}
Java
복사
> Task :LogOperatorExample03.main()
11:45:46.507 [main] DEBUG reactor.util.Loggers$LoggerFactory - Using Slf4j logging framework
11:45:46.526 [main] INFO Fruit.Source - onSubscribe(FluxSubscribeOn.SubscribeOnSubscriber)
11:45:46.528 [main] INFO Fruit.Lower - | onSubscribe([Fuseable] FluxMapFuseable.MapFuseableSubscriber)
11:45:46.528 [main] INFO Fruit.Substring - | onSubscribe([Fuseable] FluxMapFuseable.MapFuseableSubscriber)
11:45:46.528 [main] INFO Fruit.Name - | onSubscribe([Fuseable] FluxMapFuseable.MapFuseableSubscriber)
11:45:46.528 [main] INFO Fruit.Name - | request(unbounded)
11:45:46.528 [main] INFO Fruit.Substring - | request(unbounded)
11:45:46.528 [main] INFO Fruit.Lower - | request(unbounded)
11:45:46.529 [main] INFO Fruit.Source - request(256)
11:45:46.530 [boundedElastic-1] INFO Fruit.Source - onNext(BANANAS)
11:45:46.530 [boundedElastic-1] INFO Fruit.Source - onNext(APPLES)
11:45:46.530 [boundedElastic-1] INFO Fruit.Source - onNext(PEARS)
11:45:46.530 [boundedElastic-1] INFO Fruit.Source - onNext(MELONS)
11:45:46.530 [parallel-1] INFO Fruit.Lower - | onNext(bananas)
11:45:46.530 [parallel-1] INFO Fruit.Substring - | onNext(banana)
11:45:46.530 [parallel-1] INFO Fruit.Name - | onNext(바나나)
11:45:46.530 [boundedElastic-1] INFO Fruit.Source - onComplete()
11:45:46.531 [parallel-1] INFO com.itvillage.utils.Logger - # onNext(): 바나나
11:45:46.531 [parallel-1] INFO Fruit.Lower - | onNext(apples)
11:45:46.531 [parallel-1] INFO Fruit.Substring - | onNext(apple)
11:45:46.531 [parallel-1] INFO Fruit.Name - | onNext(사과)
11:45:46.531 [parallel-1] INFO com.itvillage.utils.Logger - # onNext(): 사과
11:45:46.531 [parallel-1] INFO Fruit.Lower - | onNext(pears)
11:45:46.531 [parallel-1] INFO Fruit.Substring - | onNext(pear)
11:45:46.531 [parallel-1] INFO Fruit.Name - | onNext(배)
11:45:46.531 [parallel-1] INFO com.itvillage.utils.Logger - # onNext(): 배
11:45:46.531 [parallel-1] INFO Fruit.Lower - | onNext(melons)
11:45:46.531 [parallel-1] INFO Fruit.Substring - | onNext(melon)
11:45:46.533 [parallel-1] INFO Fruit.Substring - | cancel()
11:45:46.533 [parallel-1] INFO Fruit.Lower - | cancel()
11:45:46.533 [parallel-1] INFO Fruit.Source - cancel()
11:45:46.533 [parallel-1] ERROR Fruit.Name - | onError(java.lang.NullPointerException: The mapper returned a null value.)
11:45:46.534 [parallel-1] ERROR Fruit.Name -
java.lang.NullPointerException: The mapper returned a null value.
Java
복사
11. Testing
가. StepVerifier 활용
•
StepVerifier를 활용하면 Publisher와 Operator 체인으로 구성된 Sequence를 구독할 때의 동작이 예상과 동일한지를 확인할 수 있습니다.
•
Sequence의 실제 Signal이 예상과 같은지 검증합니다.
•
Backpressure, Context 등을 테스트할 수 있습니다.
나. TestPublisher, PublisherProbe 활용
•
TestPublisher는 테스트 목적의 Publisher입니다. 특정 상황을 재현하여 테스트할 때 주로 활용합니다. 그외에도 리액티브 스트림즈 명세에 대한 준수여부를 테스트할 수 있습니다.
•
PublisherProbe는 Operator의 실행 경로를 검증하는데, 조건에 따른 분기에 의해 실행 경로가 의도대로 실행되는지를 테스트합니다.
참고
•
Reactive System 정의, https://reactivemanifesto.org/
•
Reactive Programming 정의, https://en.wikipedia.org/wiki/Reactive_programming
•
Reactive Streams Specification, https://github.com/reactive-streams/reactive-streams-jvm/blob/master/README.md#specification
•
쉬운 코드, Blocking vs Non-Blocking vs Synchronize vs Asynchronize - https://youtu.be/EJNBLD3X2yg?si=b5-g8UORgYQGjzKD, https://youtu.be/mb-QHxVfmcs?si=Olebgdhjg30FRmCO, https://www.youtube.com/watch?v=mb-QHxVfmcs
•
Spring Webflux 공식문서 번역본 - https://godekdls.github.io/Reactive Spring/contents/
•
DevHabit, WebFlux Async Process, https://www.devhabit.org/backend-2/spring-webflux-introduction