1. 테이블에서 데이터 검색

2. 정렬과 연산
3. 데이터의 추가, 삭제, 갱신
4. 집계와 서브쿼리
5. 데이터베이스 객체 작성과 삭제
6. 복수의 테이블 다루기
가. 집합연산
1) UNION, 합집합
•
UNION은 SELECT 명령 사이에 추가하여 사용한다
•
중복되는 요소에 대해 한 번만 결과로 출력한다
•
;는 마지막 SELECT 명령 뒤에 붙는다
// sample1_a: a(1, 2, 3)
// sample1_b: a(2, 10, 11)
SELECT * FROM sample1_a
UNION
SELECT * FROM sample1_b; // 결과: a(1, 2, 3, 10, 11)
SQL
복사
•
테이블 전체의 열을 대상(SELECT *)으로 UNION을 실행할 경우, UNION으로 묶이는 열의 개수와 자료형이 같아야 한다
•
단, SELECT에서 *가 아니라 열을 지정하는 경우에는 자료형이 같아야 한다
•
ORDER BY는 마지막 SELECT 명령 뒤에 붙인다
•
각각의 테이블의 해당하는 열의 이름이 다를 경우 AS를 활용하여 같은 별칭을 부여하고 이를 기준으로 정렬한다
→ 각각의 테이블의 열의 이름이 다를 경우 에러 발생
→ 합집합의 결과이기 때문에 같은 열의 이름으로 결과들이 나열되는 형식을 지켜야 함
// sample2: a(4, 6, 9)
// sample3: b(4, 6, 11)
SELECT a AS c FROM sample2
UNION
SELECT b AS c FROM sample3 ORDER BY c; // 결과: c(4, 6, 9, 11)
SQL
복사
•
UNION ALL, 중복을 허용하여 모든 요소를 나열함
// sample1_a: a(1, 2, 3)
// sample1_b: a(2, 10, 11)
SELECT * FROM sample1_a
UNION ALL
SELECT * FROM sample1_b; // 결과: a(1, 2, 2, 3, 10, 11)
SQL
복사
2) INTERSECT, 교집합
•
MYSQL에서 지원하지 않음
3) EXCEPT, 차집합
•
MYSQL에서 지원하지 않음
나. JOIN, 테이블 결합
1) 곱집합과 교차결합(Cross Join)
•
교차결합(Cross Join)의 문법
→ 테이블 사이에 쉼표(,) 사용
→ FROM 구에 복수의 테이블을 지정하면 교차결합을 실행함
// sample2_x: x(a, b)
// sample2_y: y(1, 2)
SELECT * FROM sample2_x, sample2_y;
// 결과
// x(a, b, a, b)
// y(1, 1, 2, 2)
SQL
복사
•
합집합과 테이블 결합의 차이
→ 집합연산은 행방향으로 확대: 같은 열을 갖고 있는 두 테이블이 합쳐짐으로써 같은 열 내 행 요소들이 늘어나는 형태
→ 테이블 결합은 열방향으로 확대: 다른 열을 갖고 있는 두 테이블이 합쳐짐으로써 열 요소가 늘어남
2) 내부결합(Inner Join)
•
내부결합(Inner Join)이란 교차결합으로 생성된 행 요소 중에서 결합조건에 따라 원하는 조합으로 결합된 것
→ 결합조건: 교차결합으로 생성된 요소 중에서 원하는 조합을 추려내는 조건
•
테이블 결합에는 내부 결합을 주로 사용함
→ 교차결합은 조합의 수가 너무 많이 증가함
SELECT 상품.상품명, 재고.재고량 FROM 상품, 재고
WHERE 상품.상품코드 = 재고.상품코드 // 결합조건
AND 상품.상품분류 = '식료품'; // 검색 조건
SQL
복사
3) INNER JOIN 명령으로 내부결합
•
내부결합에 대한 위의 쿼리는 구식
•
INNER JOIN 명령을 사용하는 것이 일반적
•
결합조건을 ON 구에서 정의하고 검색조건을 WHERE 구에서 정의
SELECT 상품.상품명, 재고.재고량
FROM 상품 INNER JOIN 재고
ON 상품.상품코드 = 재고.상품코드 // 결합 조건
WHERE 상품.상품분류 = '식료품'; // 검색 조건
SQL
복사
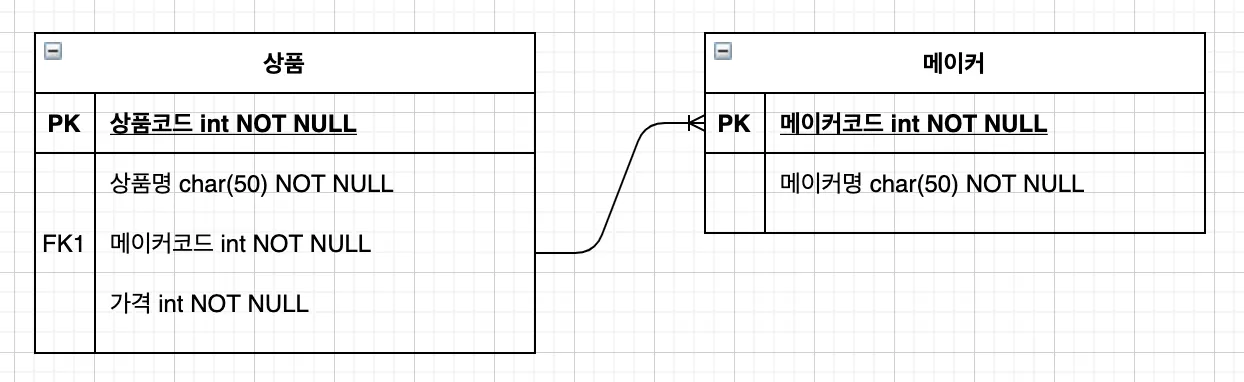
4) 내부결합 활용
•
상품 테이블과 메이커 테이블에 내부결합을 활용하여 상품명, 메이커명을 출력
→ 상품 테이블(상품코드, 상품명, 메이커코드, 가격)
→ 메이커 테이블(메이커코드, 메이커명)
•
매번 테이블 명을 쓰는 것은 번거로우므로 아래와 같이 FROM 구에서 별칭을 선언하는 것이 일반적
SELECT S.상품명, M.메이커명
FROM 상품 S INNER JOIN 메이커 M
ON S.메이커코드 = M.메이커코드 // 결합조건
SQL
복사
•
테이블 간 관계
→ 메이커코드 기준으로 상품 테이블은 같은 메이커코드를 갖는 여러개의 상품 행이 존재
→ 메이커 테이블에서 메이커코드는 유일한 값을 가짐
→ 상품:메이커=N:1 관계(다대일)
•
기본키: 특정 테이블에서 유일한 값을 가지며 특정 행의 인덱스의 역할
→ 메이커 테이블의 메이커코드가 기본키
•
외래키: 다른 테이블의 기본키를 참조하는 열
→ 상품 테이블의 메이커코드가 외래키
5) 외부결합
•
출력하려는 데이터가 다른 한쪽의 테이블에 추가되지 않았을 경우, NULL 출력하기 위해 사용
•
LEFT JOIN
→ 기준이 되는 테이블을 왼쪽에 배치
SELECT S.상품명, M.메이커명
FROM 상품 S LEFT JOIN 메이커 M
ON S.메이커코드 = M.메이커코드 // 결합조건
WHERE S.상품명 = '식료품';
SQL
복사
다. 관계형 모델
1) 관계형 모델과 SQL
•
관계형 모델은 RDBMS의 이론적 토대임
2) 관계형 모델과 SQL의 용어 차이
•
관계형 모델의 용어와 SQL의 용어에는 차이가 존재
•
왼쪽이 SQL, 오른쪽이 관계형 모델
•
Table = Relation
•
행(Row) = 튜플(tupple)
•
열(Column) = 속성(Attribute)
7. 데이터베이스 설계
가. 데이터베이스 설계
1) 물리명과 논리명
•
물리명: SQL로 삽입할 테이블이나 열의 이름
→ RDBMS에 적용하는 이름에는 제약사항이 존재하므로 일상용어를 사용하는데 한계가 있음
→ 물리명은 변경이 어려움
•
논리명: 설계상의 테이블이나 열의 이름
→ 일상용어를 사용하여 이름짓기 가능
→ 변경이 자유로움
2) 고정길이와 가변길이
•
상품번호와 같이 고정된 길이의 데이터라면 자료형 정의 시, 길이를 고정하는 것을 권고
•
비고 또는 게시글의 내용 등의 경우, 저장할 데이터의 크기가 일정하지 않으므로 가변길이의 자료형 사용 권고
•
LOB(Large Object): 게시글의 내용 등의 데이터는 LOB 자료형을 사용한다. 다만 인덱스를 지정할 수 없음
3) 기본키
•
기본키로 사용할 열에 대해 AUTO_INCREMENT를 지정하면 행의 값이 자동증가
•
기본키로 지정한 열에는 UNIQUE or PRIMARY KEY를 지정하여 유일성을 보장해야 함
나. ER 다이어그램
1) ER 다이어그램이란
•
테이블 또는 개체 간의 연계 표현
2) ER 다이어그램 규칙
•
각 테이블 또는 개체는 사각형으로 표현
•
테이블과 속성(열)에 대한 이름은 주로 논리명으로 표시
•
기본키는 속성 중에서 상위에 표시
•
테이블 간의 연계는 선으로 표현
→ 선을 연결할 때, 각 테이블의 기본키와 외래키를 지점을 기준으로 한다
→ 선에 연계의 타입을 명시할 수 있다.
→ 연계의 타입: 1:1, 1:N, N:N
다. 정규화
1) 정규화란
•
정규화의 기본 개념
가) 테이블의 중복 또는 반복되는 부분을 찾아내는 것
나) 분할된 테이블에 기본키를 작성하는 것
•
정규화의 목적: 하나의 데이터가 한 곳에 저장되도록 개선하는 것
•
정규화 목적달성에 따른 이점: 데이터 검색 및 변경 비용을 낮출 수 있음
가) 데이터 변경사항이 발생하면 수정할 부분을 최소화할 수 있음
→ 데이터 중복이 일반화된다면, 특정 데이터가 존재하는 곳을 검색하고 모두 변경함에 따라 변경비용이 높아질 것
나) 특정 테이블의 인덱스 재설정 억제
1. 테이블이 생성되면 '클러스터링 인덱스'에 따라 기본키를 기준으로 테이블에 대한 인덱스가 자동으로 생성됨
→ 외부키(forien key)에도 인덱스가 생성됨
2. 정규화가 되면 적절한 기본키가 지정됨. 적절한 기본키는 특정 테이블의 내부적으로만 사용되고, 유일하고 고유하기 때문에 변경될 일이 없음.
3. 적절한 기본키는 변경되지 않으므로 테이블에 변경사항이 발생해도 '클러스터링 인덱스'가 재실행되지 않기 때문에 결과적으로 인덱스 재설정이 발생하지 않음.
•
정규화는 제1정규화부터 순차적으로 실행
•
정규화 실행시점은 데이터베이스 설계 또는 기존 시스템을 재점검하는 경우
2) 제1정규화
•
제1정규화 목표: 하나의 셀에 하나의 값만 지정 & 기본키 지정
•
RDBMS는 제1정규화를 전제함
•
제1정규화 과정
→ STEP 1. 복합적인 값에 대해 분할(하나의 셀에 하나의 값)
→ STEP 2. 테이블 분할에 따른 중복되는 행(or 튜플) 제거
→ STEP 3. 기본키 지정
•
제1정규화 실습
기본 보기
Search
STEP 1. 복합적인 값에 대한 분할
기본 보기
Search
STEP 2. 테이블 분할에 따른 중복행 제거
기본 보기
Search
기본 보기
Search
STEP 3. 기본키 지정
•
주문 테이블의 경우 주문번호를 기본키로 지정
•
주문상품 테이블의 경우 주문번호와 상품코드를 묶어서 기본키로 지정
3) 제2정규화
•
제2정규화 목표: 기본키의 일부에서 발생하는 부분 함수종속성 제거
•
부분 함수종속성: 기본키 자체가 아닌 기본키를 구성하는 열(or 속성)에 특정 열이 종속되는 것
•
제2정규화 과정: 함수종속성이 존재하는 열을 다른 테이블로 분리
•
제2정규화 실습
기본 보기
Search
함수종속성 제거에 따른 테이블 분할
기본 보기
Search
기본 보기
Search
4) 제3정규화
•
제3정규화 목표: 기본키 이외의 영역에서 발생하는 추이 함수종속성 제거
•
추이 함수종속성: 기본키 외의 열에 테이블의 특정 열이 종속되는 것
•
제3정규화 과정: 추이 함수종속 부분에 대해 테이블 분할 및 기본키 지정
•
제3정규화 실습
기본 보기
Search
추이 함수종속성 제거
기본 보기
Search
기본 보기
Search
5) 정규화 후의 테이블을 ER 다이어그램으로 표현
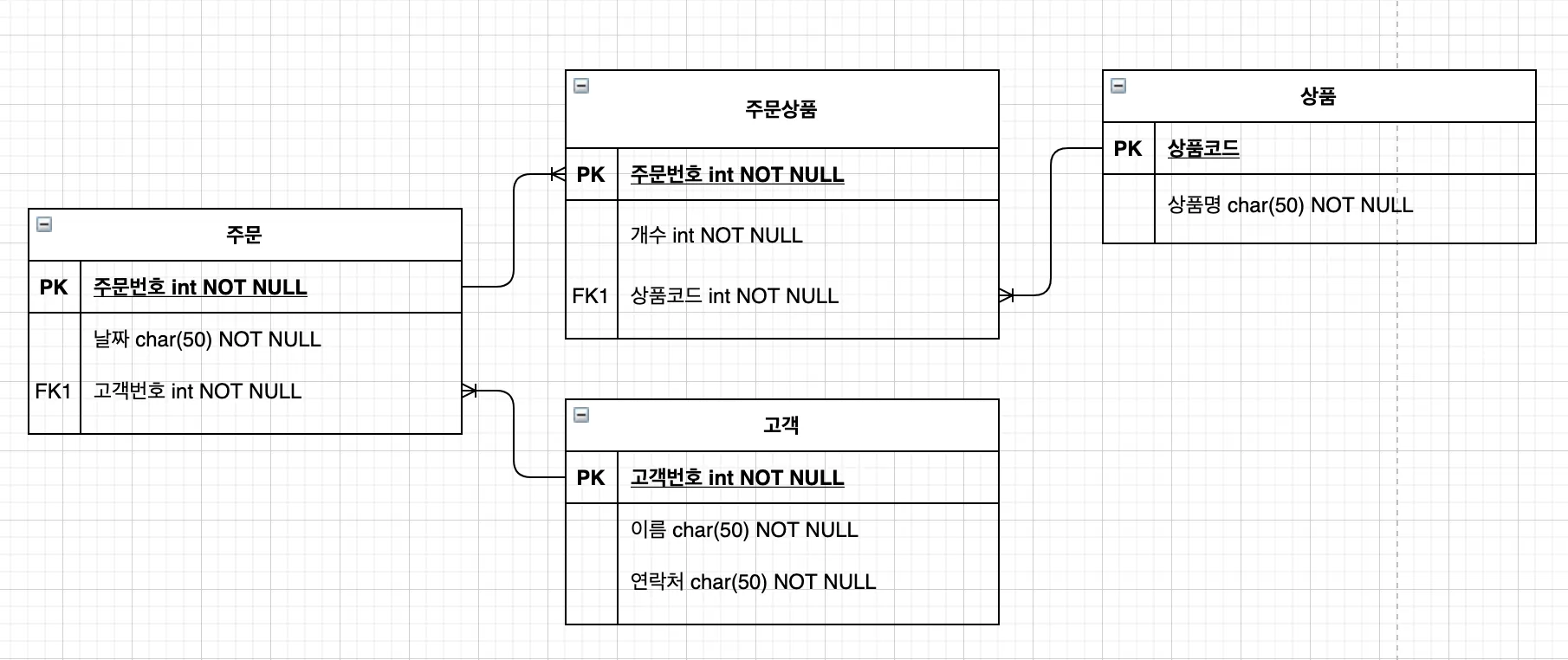
라. 트랜잭션
1) 트랜잭션이란
정의
•
논리적 기능을 수행하기 위해 한꺼번에 실행되어야 할 일련의 연산
→ 여러 단계에 걸쳐서 SQL 명령을 실행하는 경우에 사용함
예시
•
주문발주(논리적 기능)를 수행하기 위해 정의된 Transaction
START TRANSACTION;
INSERT INTO 주문 VALUES(4, '2014-03-01', 1);
INSERT INTO 주문상품 VALUES(4, '0003', 1);
INSERT INTO 주문상품 VALUES(4, '0004', 10);
COMMIT;
SQL
복사
2) 롤백(ROLLBACK)과 커밋(COMMIT)
•
일련의 SQL 명령을 실행한 후, 에러 발생 유무에 따라 롤백과 커밋을 실행함
•
SQL 실행에 따른 연산결과는 임시저장공간에 저장되며 커밋 이후에 실제저장공간에 반영됨
•
롤백: 에러가 발생한 경우, 일련의 SQL 실행에 따른 연산결과가 실제 저장공간에 반영되지 않음
→ 에러가 발생하지 않더라도 롤백을 실행하면 해당 트랜잭션의 연산결과는 파기됨
•
커밋: 에러가 발생하지 않았다면, 일련의 SQL 실행에 따른 연살결과가 실제저장공간에 반영됨
→ 에러가 발생하더라도 커밋을 실행하면 해당 트랜잭션의 연살결과는 실제 저장공간에 반영됨
•
INSERT, UPDATE, DELETE 명령이 실행되면 명령마다 자동으로 Commit이 실행됨
→ START TRANSACTION 입력 시, 위의 자동 커밋의 실행이 중단됨