가. 기초 개념
•
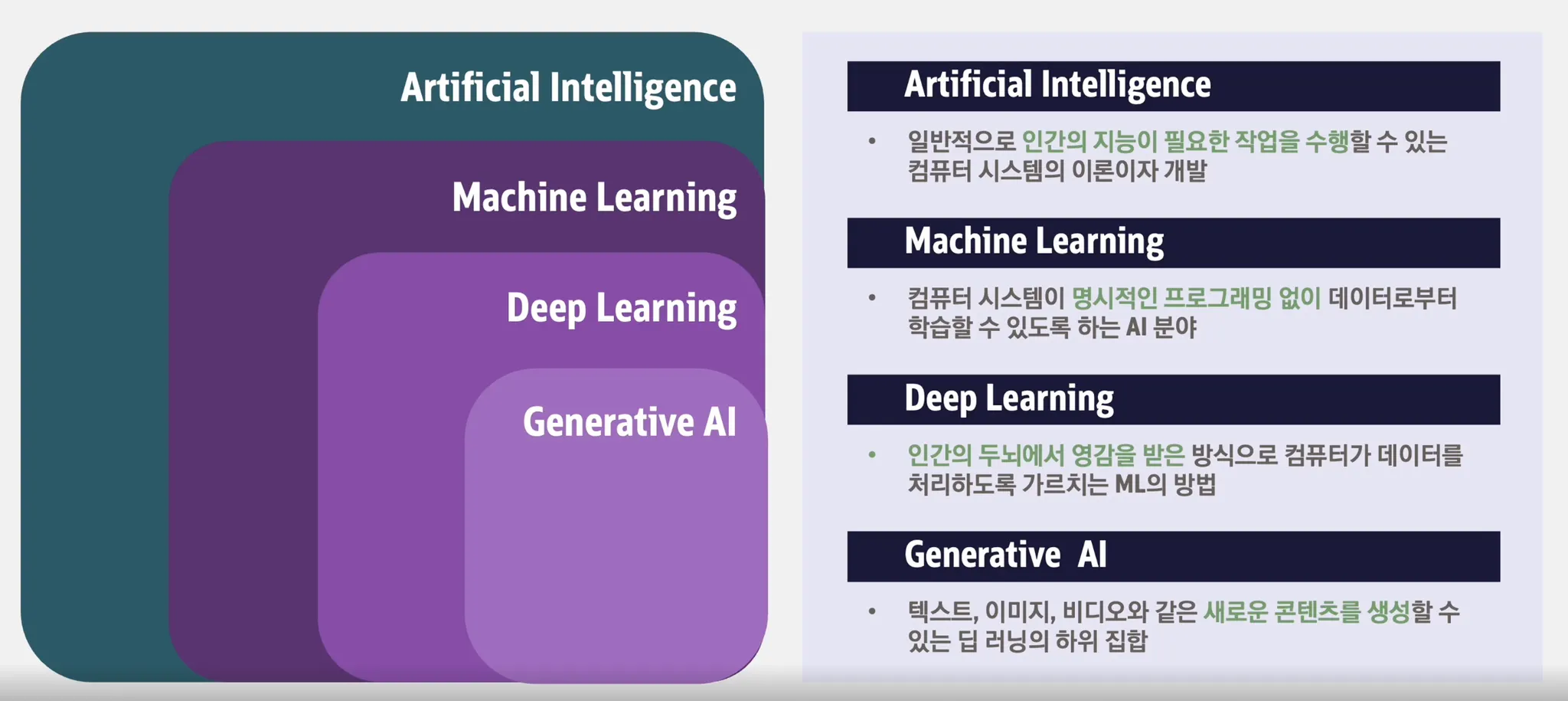
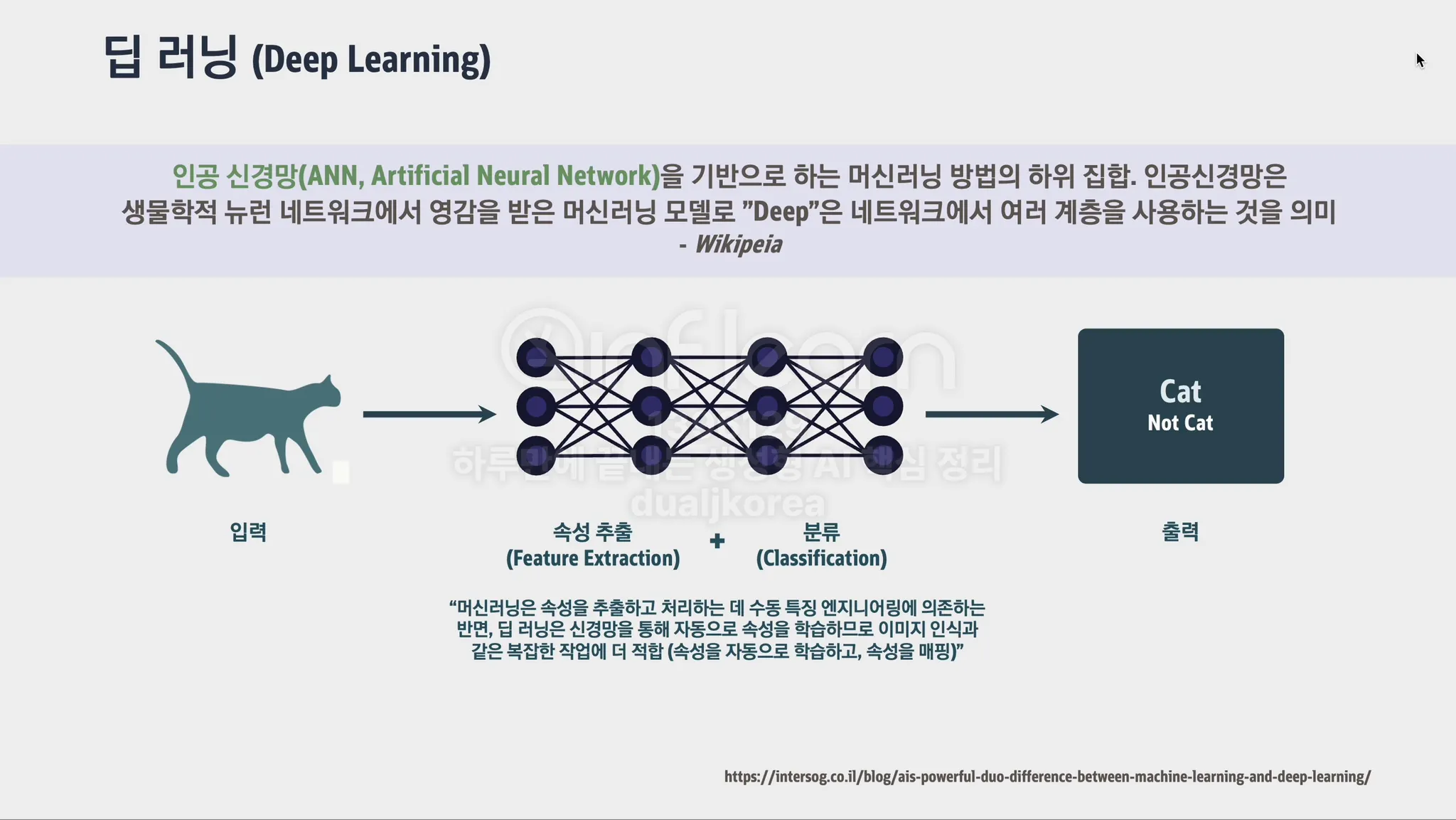
ANN(인공 신경망, Artificial Neural Network): 생물학적 신경망을 본떠 만든 컴퓨팅 모델로, 여러 Layer의 Node들이 연결되어 데이터를 처리하고 패턴을 학습합니다. 이 신경망은 주어진 데이터에서 규칙이나 특징을 찾아내어 예측하는 데 사용됩니다. 예를 들어, 이미지나 텍스트 데이터를 입력하면, 그 속의 숨겨진 패턴이나 구조를 인식해 결과를 도출합니다.
◦
Layer(레이어): 신경망에서 입력 데이터가 처리되는 단계 또는 층을 의미합니다. 각 레이어는 데이터를 변환하여 다음 레이어에 전달하며, 여러 레이어가 함께 작동해 복잡한 패턴을 학습합니다. 예를 들어, 이미지 신경망에서 첫 번째 레이어는 간단한 선을 인식하고, 마지막 레이어는 전체 이미지를 이해하는 역할을 할 수 있습니다.
◦
Node(노드): 레이어 안에 있는 작은 계산 단위입니다. 노드는 하나의 입력을 받아 처리하고, 이를 기반으로 출력을 생성합니다. 각 노드는 수학적 연산을 통해 데이터를 처리하고, 이를 다음 레이어나 노드로 전달합니다. 노드는 뉴런과 유사한 개념으로 이해할 수 있습니다.
•
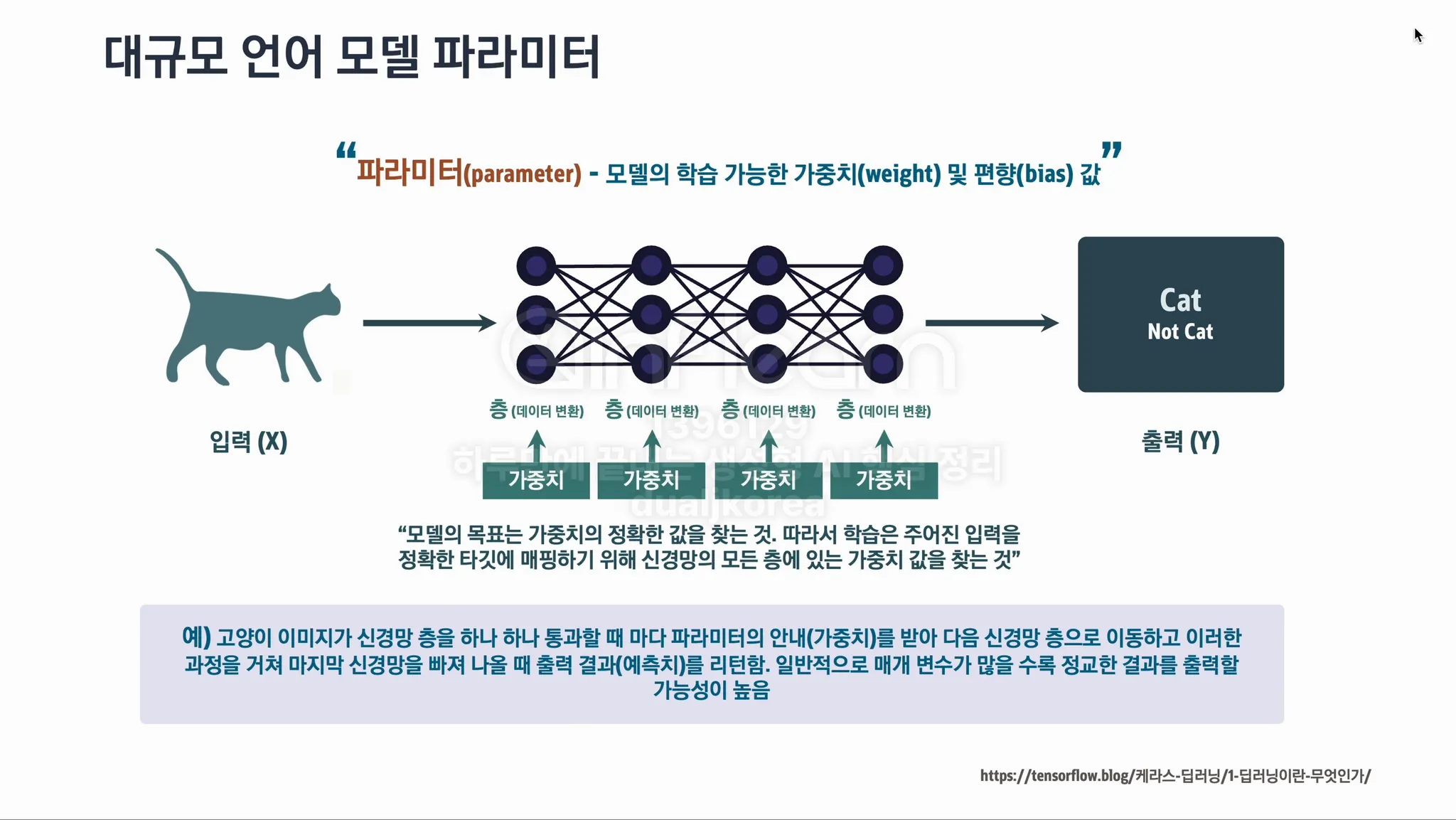
Parameter(파라미터): 모델이 학습 과정에서 조정하는 값입니다. 가중치(weight)와 편향(bias) 같은 값들이 이에 해당하며, 신경망이 데이터를 처리하고 결과를 예측하는 데 중요한 역할을 합니다. 이 값들이 최적화되면 모델의 예측 성능이 향상됩니다.
◦
Weight(가중치): 입력 데이터가 노드에 전달될 때, 그 중요도를 결정하는 값입니다. 신경망은 각 입력에 대한 가중치를 학습하는데, 이 가중치가 높을수록 해당 입력이 결과에 더 큰 영향을 미치게 됩니다. 학습 과정에서 가중치는 조정되어 모델이 더 정확한 예측을 할 수 있도록 합니다.
◦
Bias(편향): 데이터를 처리할 때 가중치가 곱해진 입력 값에 추가되는 값입니다. Bias는 가중치와 함께 모델이 더 유연하게 학습할 수 있도록 도와줍니다. 모델이 입력에 대한 예측을 만들 때 어느 정도의 기본값을 추가해주는 역할을 합니다.
•
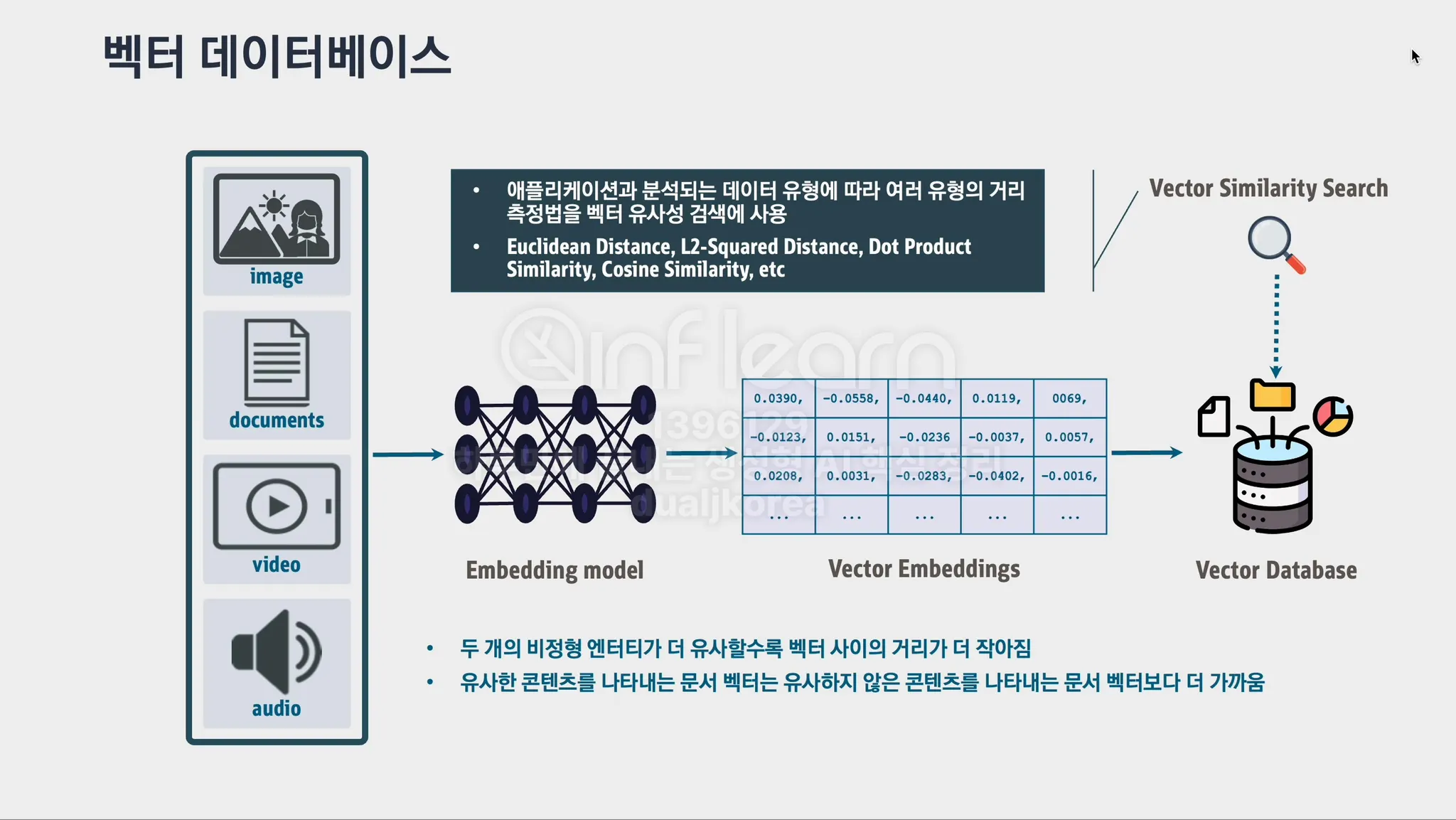
Vector(벡터): 컴퓨터가 텍스트나 이미지를 이해할 수 있도록 숫자로 표현한 값들의 집합입니다. 데이터의 특징을 수치화하여 벡터로 변환하면 컴퓨터가 쉽게 처리할 수 있습니다.
◦
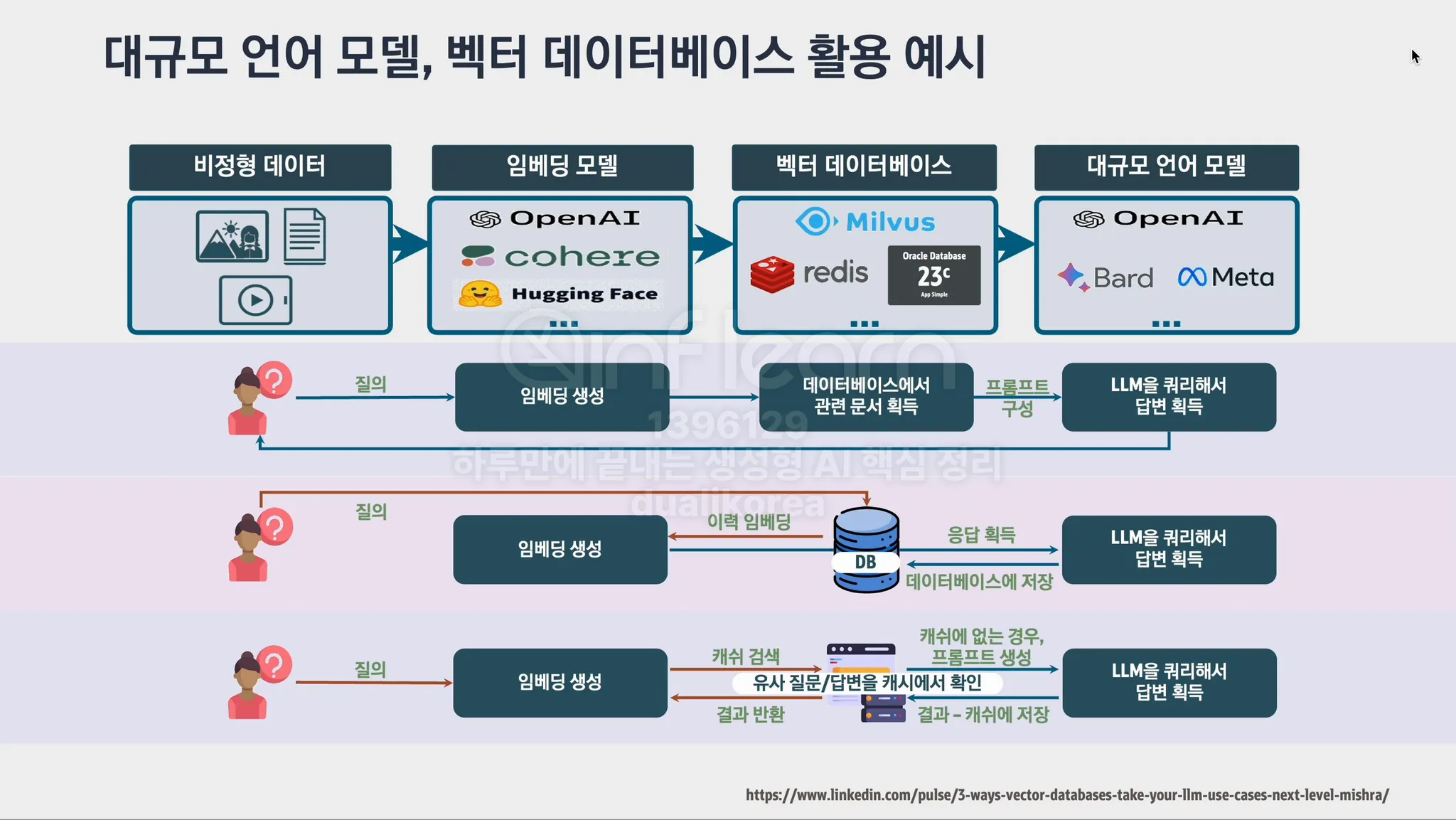
Vector DB(벡터 데이터베이스): 벡터로 표현된 데이터를 저장하고 빠르게 검색할 수 있는 데이터베이스입니다. 예를 들어, 이미지나 텍스트를 벡터로 변환한 후, 유사한 벡터를 검색할 때 사용됩니다.
◦
Word Vector(단어 벡터): 단어를 수치로 표현한 벡터입니다. 단어 간의 유사성을 수치적으로 표현할 수 있으며, 단어 벡터는 단어의 의미를 수학적으로 나타낸다고 볼 수 있습니다.
◦
Top-k Vector(탑-k 벡터): 벡터 검색에서 가장 유사한 상위 k개의 벡터를 반환하는 방식입니다. 예를 들어, 입력된 단어에 대해 가장 가까운 단어 벡터 k개를 찾는 과정입니다.
•
Tokenization(토큰화): 텍스트를 가장 작은 의미 단위인 '토큰'으로 쪼개는 과정입니다. 예를 들어, 문장을 단어, 글자 또는 하위 단위로 나눌 수 있습니다. 이는 LLM이 텍스트를 이해하고 처리하는 데 필수적인 단계입니다.
•
Embedding(임베딩): 단어, 문장 또는 데이터를 숫자로 된 벡터로 변환하여 컴퓨터가 이해할 수 있도록 하는 과정입니다. 이를 통해 단어들 간의 의미적 유사성을 수학적으로 표현할 수 있습니다. 예를 들어, '고양이'와 '개'라는 단어가 의미적으로 가깝다면, 임베딩 벡터도 비슷한 값이 됩니다.
•
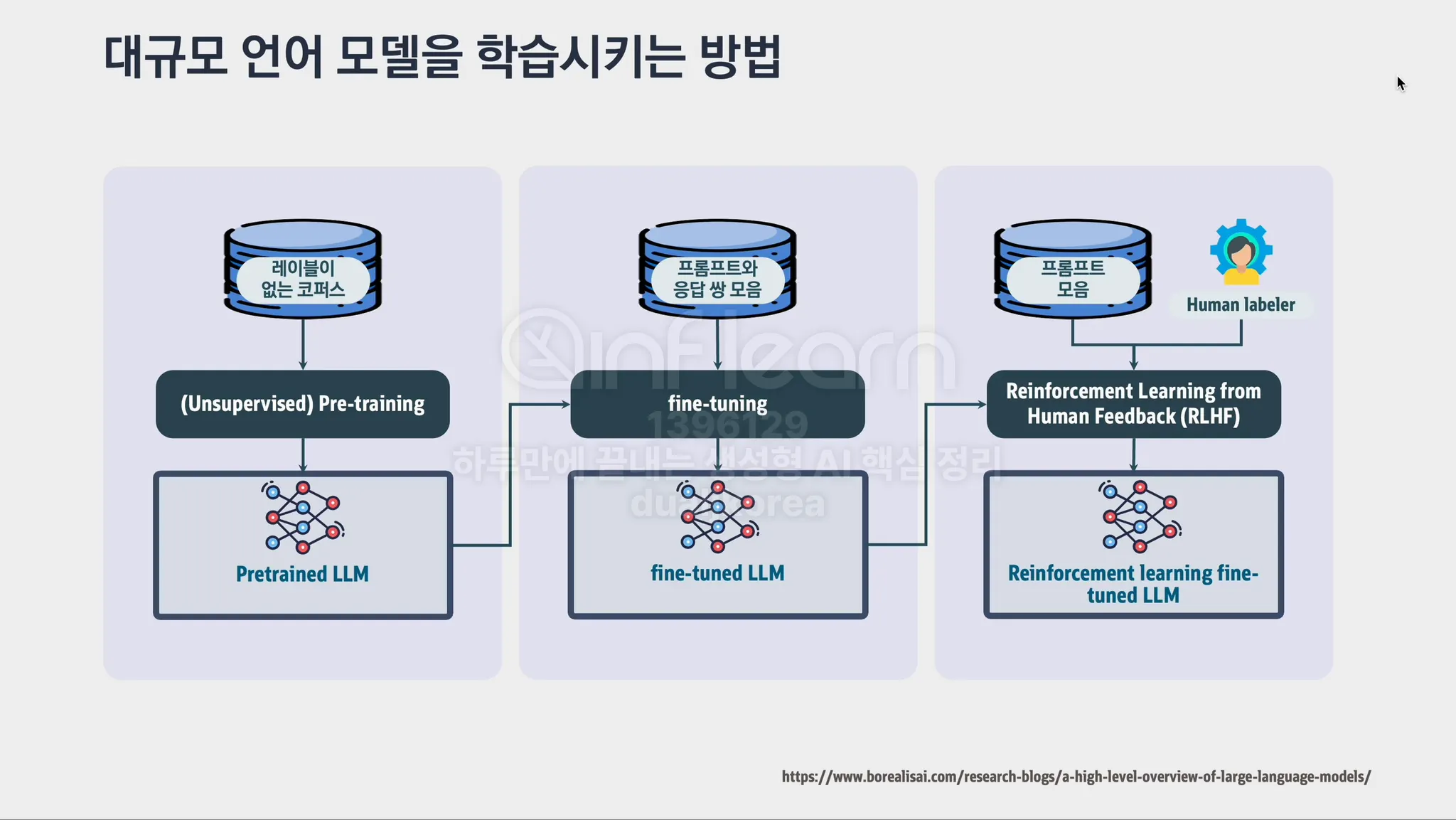
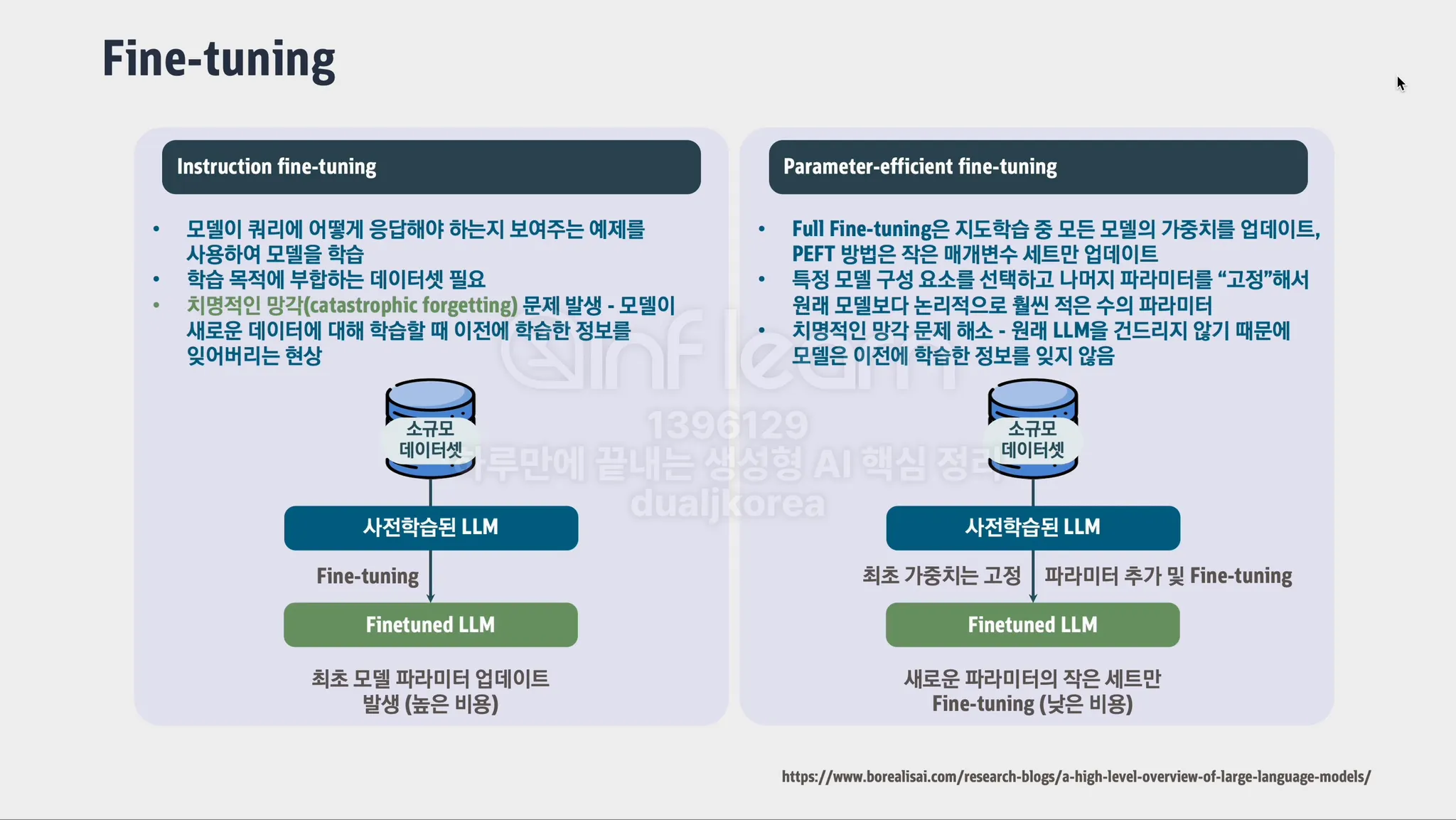
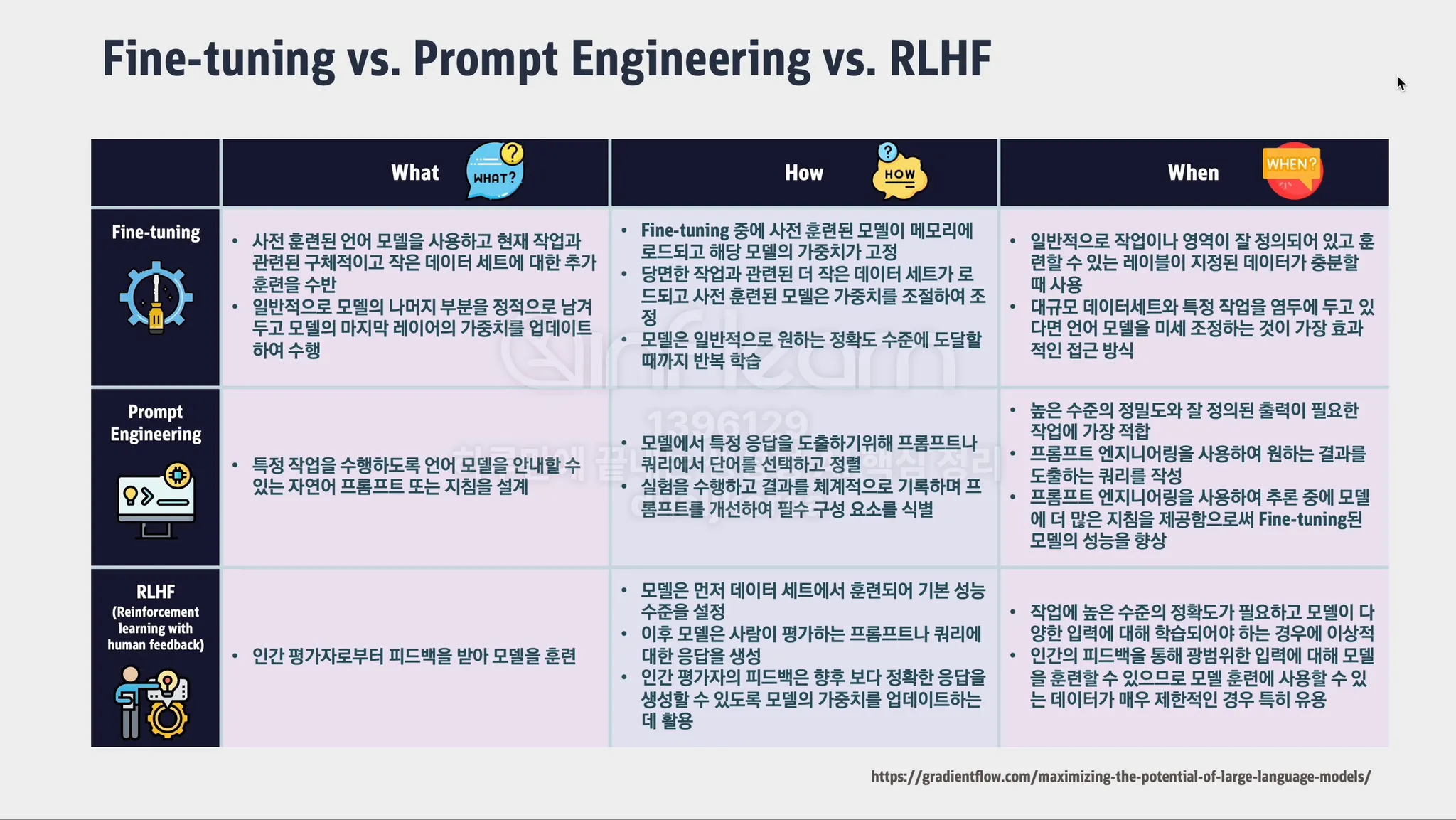
Fine Tuning(파인튜닝): 사전 학습된 모델을 특정 목적에 맞게 추가로 학습시키는 과정입니다. 예를 들어, 일반적인 언어 모델에 특정 분야(예: 의학, 법률)의 데이터를 추가로 학습시켜 해당 분야에 특화된 모델을 만드는 것을 의미합니다.
•
RLHF(강화학습, Reinforcement Learning from Human Feedback): 인간이 LLM이 생성한 결과물에 대해 피드백을 제공하고, 그 피드백을 바탕으로 모델이 더 나은 결과를 내도록 학습시키는 방법입니다. 이를 통해 사람의 의도에 더 부합하는 답변을 생성하게 됩니다.
◦
Label(레이블): 데이터에 대한 정답 또는 참조 값입니다. 지도 학습에서 모델이 학습할 때 사용되며, 예를 들어 이미지 분류에서 '고양이' 또는 '개'와 같은 값이 레이블입니다.
•
Prompt Engineering(프롬프트 엔지니어링): 원하는 결과를 얻기 위해 LLM에 적절한 질문이나 명령(프롬프트)을 설계하는 과정입니다.
•
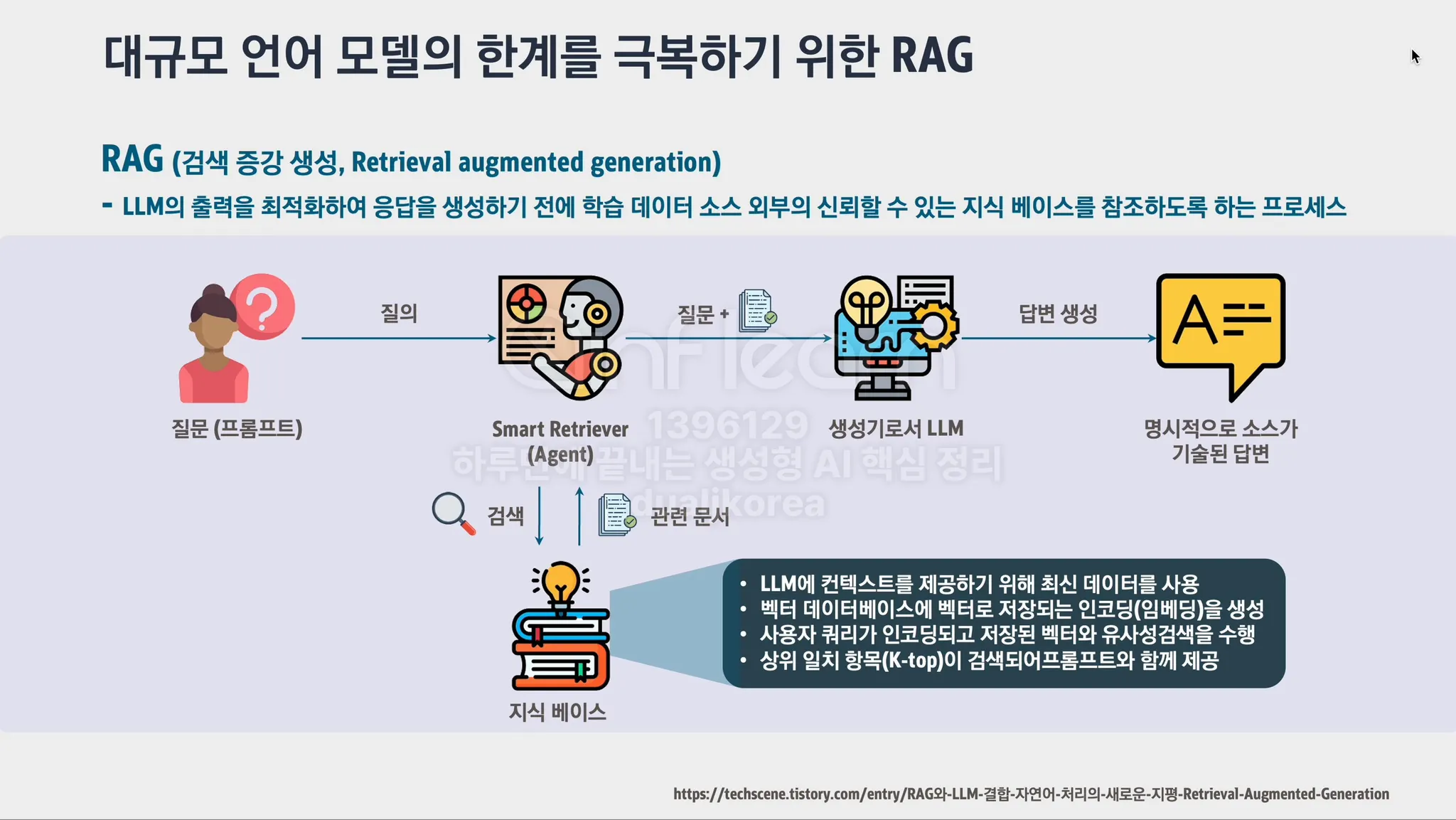
RAG(검색 증강 생성, Retrieval Augmented Generation): LLM이 답변을 생성할 때, 사전에 학습한 정보 외에도 외부 지식(예: 데이터베이스, 웹페이지 등)을 검색하여 활용하는 방식입니다. 이로 인해 최신 정보나 모델이 학습하지 않은 데이터를 참고할 수 있게 됩니다.
•
LLaMA(LLM Meta AI): Meta(구 페이스북)에서 개발한 대규모 언어 모델(LLM)입니다. 오픈소스로 공개되어 상업적으로도 사용 가능하며, 자연어 처리(NLP)와 관련된 다양한 작업에 활용됩니다.
•
Transformer(트랜스포머): 현재의 대규모 언어 모델(LLM)의 핵심 구조로, 입력 데이터의 관계를 효과적으로 분석하여 정보를 처리합니다. 주로 자연어 처리에서 사용되며, 기존의 순차적 모델보다 더 빠르고 효율적입니다.
•
Self-attention(자기 주의): 트랜스포머에서 사용하는 메커니즘으로, 문장 내의 각 단어가 다른 단어들과 어떻게 연관되는지를 계산하는 방법입니다. 이 덕분에 모델은 문맥을 더 잘 이해할 수 있게 됩니다.
AI 핵심 개념 정리
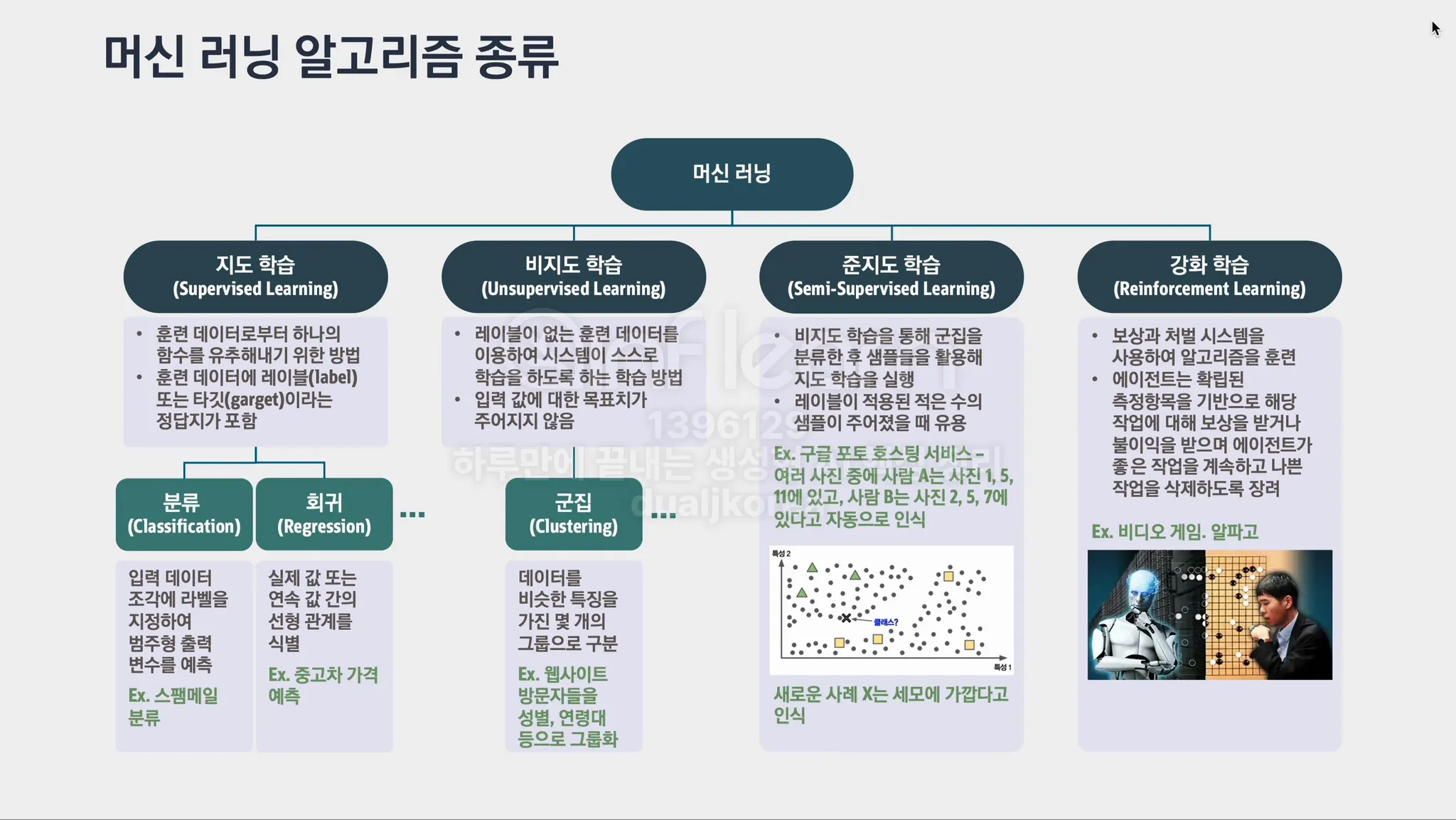
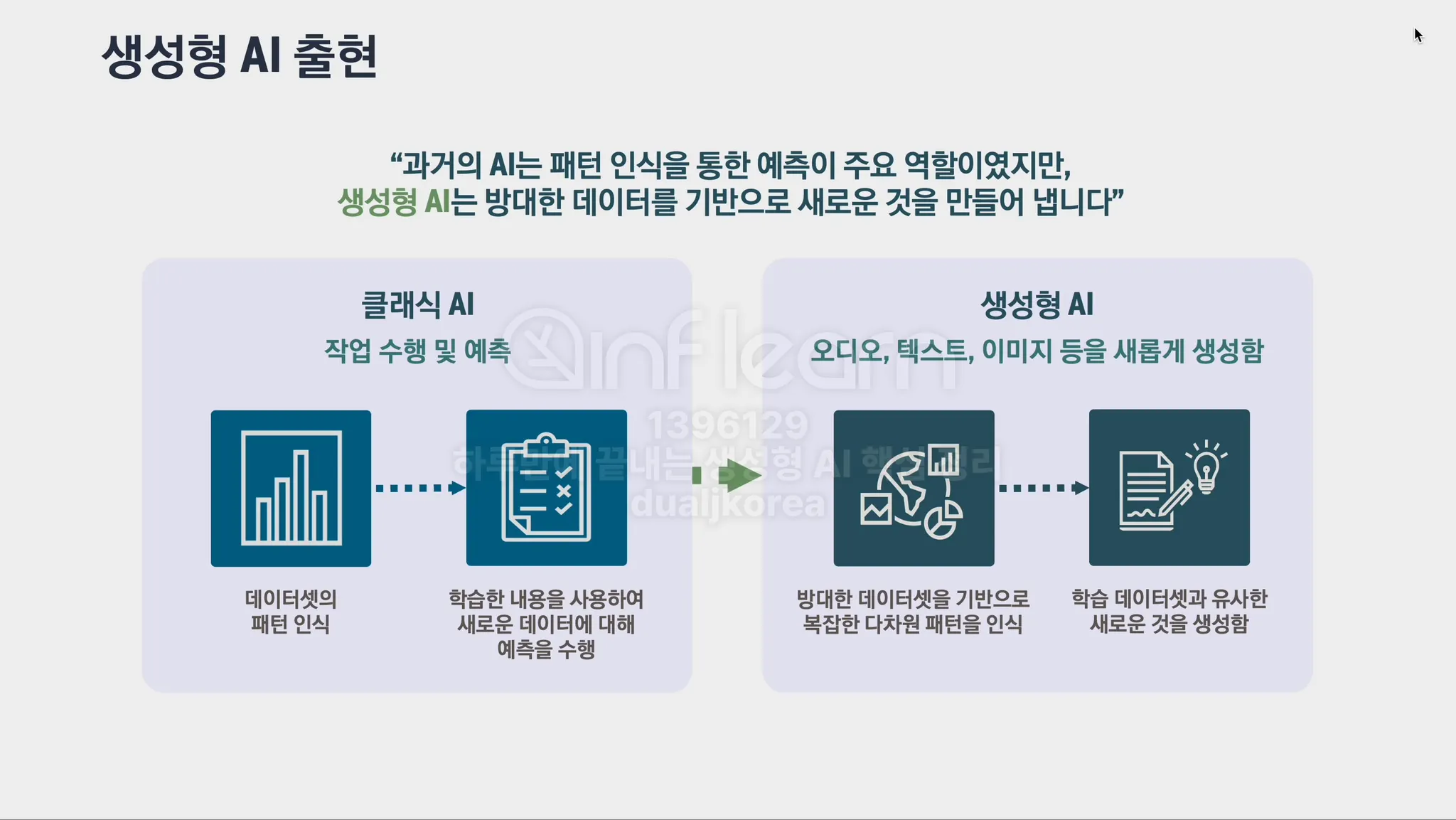
패턴 인식 기반 ML vs 인공 신경망 기반 ML

나. 프롬프트 엔지니어링
답변의 구조에 대한 설명과 예시 그리고 예외를 제공하는 방법
Few Shot Prompting
답변의 역할을 지정하고 예시를 제공하는 방식
답변의 포맷 지정
답변 길이 지정
문장 구조화
few shot 기법
텍스트 감정추론
text_1 = f"""
차 한 잔 만드는 것은 쉽습니다! 먼저 물을 끓이세요. \
그 동안 컵을 가져와 그 안에 차를 담으세요. 물이 충분히 뜨거워지면, \
그냥 차를 티백 위에 따르세요. 차가 우러나올 수 있도록 잠깐 기다려주세요. \
몇 분 후에 티백을 빼내세요. 원한다면 설탕이나 우유를 넣어 맛을 조절할 수 있습니다. \
그럼 끝났어요! 맛있는 차 한 잔이 완성되었습니다.
"""
prompt = f"""
삼중 쿼테이션으로 감싸진 문장이 있습니다.
만약 문장 구조가 순서가 있으면, 다음과 같이 한글로 정리하시오.
스텝 1 - ...
스텝 2 - ...
...
스텝 N - ...
문장 구조에 순서가 없으면 \"순서가 없음\" 이라고 적으시오.
\"\"\"{text_1}\"\"\"
"""
스텝 1 - 물을 끓이세요.
스텝 2 - 컵을 가져와 차를 담으세요.
스텝 3 - 뜨거워진 물을 티백 위에 따르세요.
스텝 4 - 차가 우러나올 수 있도록 기다려주세요.
스텝 5 - 티백을 빼내세요.
스텝 6 - 설탕이나 우유를 넣어 맛을 조절할 수 있습니다.
스텝 7 - 완성된 맛있는 차를 즐기세요.
Plain Text
복사
lamp_review = """
침실용으로 좋은 램프가 필요했고, 이 제품은 추가 수납 공간이 있으면서도 가격이 너무 비싸지 않았습니다.\
빨리 받았어요. 램프의 스트링이 운송 중에 끊어졌는데, 회사가 기꺼이 새로운 것을 보내주었습니다. \
몇 일 안에 도착했습니다. 조립하기 쉬웠어요. 부품이 빠져 있었는데, 그들의 지원팀에 연락하여 빠르게 부품을 받았습니다! \
Lumina는 고객과 제품을 소중히 여기는 훌륭한 회사로 보입니다!!
"""
prompt = f"""
리뷰 문구에서 다음 내용을 추출하시오.
- 감정 (긍정 혹은 부정)
- 리뷰어가 분노를 표시하였는가? (예 혹은 아니오)
- 리뷰어가 구매한 아이템
- 아이템을 만든 회사
답변 포맷을 JSON 객체로 하고, "감정", "분노", "아이템", "브랜드"를 키로 정의함.
정보가 없으면, "N/A"로 표기함.
최대한 간결하게 작성할 것.
"분노"의 값은 불리언으로 함.
리뷰 문구: '''{lamp_review}'''
"""
response = get_completion(prompt)
print(response)
{
"감정": "긍정",
"분노": false,
"아이템": "램프",
"브랜드": "Lumina"
}
Plain Text
복사
prod_review = """
내 딸의 생일을 위해 이 판다 인형을 샀는데, \
딸 애는 그것을 정말 좋아해서 어디든지 가져다닌다. \
부드럽고 너무 귀여워서, 얼굴도 친근한 느낌이다. \
하지만 내가 지불한 가격에 비해 조금 작은 편이다. \
같은 가격으로 더 큰 옵션이 있을 것 같아서 아쉽다. \
예상보다 하루 일찍 도착해서, 좋았다.
"""
prompt = f"""
상품 가격 관점에서 피드백을 주기위한 목적으로 상품 리뷰를 요약할 것.
백슬래시로 구분된 리뷰를 30단어 이내로 한글로 요약하고,
상품의 가격과 가치에 포커스하여 요약할 것.
리뷰 : ```{prod_review}```
"""
response = get_completion(prompt)
print(response)
가격에 비해 조금 작지만 부드럽고 귀여운 판다 인형. 딸이 좋아하며 가치는 있지만 크기에 아쉬움이 있음. 예상보다 빠른 배송으로 만족.
Plain Text
복사
prod_review = """
내 딸의 생일을 위해 이 판다 인형을 샀는데, \
딸 애는 그것을 정말 좋아해서 어디든지 가져다닌다. \
부드럽고 너무 귀여워서, 얼굴도 친근한 느낌이다. \
하지만 내가 지불한 가격에 비해 조금 작은 편이다. \
같은 가격으로 더 큰 옵션이 있을 것 같아서 아쉽다. \
예상보다 하루 일찍 도착해서, 좋았다.
"""
prompt = f"""
배송 팀에 피드백을 주기위한 목적으로 상품 리뷰를 요약할 것.
백슬래시로 구분된 리뷰를 30단어 이내로 한글로 요약하고, \
주문과 배송 항목으로 구분하여 요약할 것.
리뷰 : ```{prod_review}```
"""
주문: 딸의 생일을 위해 구매한 판다 인형, 딸이 좋아하고 부드럽고 귀엽지만 가격에 비해 조금 작음.
배송: 예상보다 하루 일찍 도착하여 만족함.
Plain Text
복사
python 실습환경 구축
파이썬 가상환경 설정
brew 기반 아나콘다 설치
brew install --cask anaconda
아나콘다 활성화
/opt/homebrew/anaconda3/bin/conda init zsh
source ~/.zshrc
base 환경 자동 비활성화
conda config --set auto_activate_base false
conda deactivate
가상환경 설정 및 활성화
conda create -n demo python=3.11.7
conda activate demo
vscode 가상환경 선택
vscode 마켓플레이스에서 python extension 설치 필요
shift + command + p로 명령 팔레트 실행 후
python: interpreter 선택
필요한 의존성 설치
pip install streamlit openai langchain langchain_community tiktoken chromadb python_dotenv
다. 챗봇
새로운 정보를 추가하여 답변하는 방법
파인튜닝
기존에 학습된 데이터 외의 새로운 데이터를 영구히 보존하도록 LLM을 학습시킬 때 사용합니다. 특히 외부에 공개할 수 없는 내부의 데이터를 토대로 모델을 학습시키는 경우에도 활용할 수 있습니다.
OpenAI에서는 파인튜닝 함수(fine_tuning)를 제공합니다.
파인튜닝 프로세스에 컴퓨팅 리소스가 많이 들지만 OpenAI 서비스를 이용하면 상대적으로 저렴하게 간편하게 만들 수 있습니다.
RAG
추가 에이전트
추가 에이전트를 통해서 정보의 샘플을 제공한 후, 응답 과정에서 샘플을 참고하도록 하는 방법이 정보의 정확성 면에서 낫습니다. 인터넷 뉴스 검색 에이전트를 활용하면 질문의 키워드에 해당하는 뉴스를 검색하고, 검색 결과를 LLM 모델이 요약하는 형태로 응답을 전달할 수 있습니다. 이 경우, 출처를 응답에 포함할 수 있기 때문에 정보의 신뢰성이 크게 높아집니다.
라. Text Completion API
1) 기초개념
Embedding vs Text Completion
2) Text Completion 주요 매개변수 이해
from openai import OpenAI
client = OpenAI()
response = client.completions.create(
model="gpt-3.5-turbo-instruct",
prompt="",
temperature=1,
max_tokens=2048,
top_p=1,
frequency_penalty=0,
presence_penalty=0
)
Python
복사
3) Text Completion with HIstory
•
응답을 요청할 때, 프롬프트와 더불어 기존 질의응답에 대한 데이터를 함께 전달함으로써 Few Shot Prompting 방식으로 이후의 응답을 얻도록 유도할 수 있습니다.
# Note: you need to be using OpenAI Python v1.2.4 for the code below to work
from openai import OpenAI
# make sure you have OPENAI_API_KEY environment variable with API key
# export OPENAI_API_KEY=""
client = OpenAI()
history_message = [
{"role": "system", "content": "You are the best travel agency staff from Superduper travel Inc"},
{"role": "user", "content": "What is captital of South Korea?"},
{"role": "assistant", "content": "Seoul. Thank you for asking Superduper travel Inc"},
{"role": "user", "content": "What is captital of France?"},
{"role": "assistant", "content": "Paris. Thank you for asking Superduper travel Inc"}
]
end_word = 'quit'
print(f"Thank you for visiting Superduper travel Inc. To end the chat, type {end_word}\n\n")
user_question = ""
while True:
user_question = input("Any question? ")
if user_question == end_word:
print(f"Thank you for reaching out to Superduper travel Inc, Bye now!")
break
history_message.append({
"role": "user",
"content": user_question})
completion = client.chat.completions.create(
model="gpt-3.5-turbo",
messages=history_message
)
response = completion.choices[0].message.content
print(response)
history_message.append({
"role": "assistant",
"content": response})
print("\n\n")
Python
복사
4) Tool Calling
마. Fine Tuning
마. 고급 활용
1) 학습 결과
2) 학습 목표
3) 기초개념
•
Prompt Engineering:
◦
Reverse Prompt Engineering:
◦
Zero Shot Prompting:
◦
Few Shot Prompting:
•
Assistants API: OpenAI에서 제공하는 LLM 모델과 tool을 활용하여 특정 목적의 어플리케이션에 적용할 수 있는 OpenAI 서비스입니다.
◦
Assistants:
◦
Thread:
◦
Message:
◦
Run Steps:
◦
Tool Calling:
•
Text Completion:
•
Embedding:
•
Structured Outputs: strict 옵션을
참고: https://www.promptingguide.ai/kr/techniques
4) Prompt Engineering for SW Engineer
•
역할 지정, 시스템 메세지 지정 등
•
OpenAI 공식 가이드 참고
•
이미지 생성 봇 또는 추천 봇
•
사진 촬영 자세를 물어보는건?
5) Llama 활용
6)Image Generation 활용
•
이미지 생성: 미드저니 말고 DELL
•
비디오 생성: D-ID 말고 유튜브에 올린 그 서비스
7)LLM 적용 노아와 신디의 작업물 보자
참고
•
homebrew로 anaconda 설정하기, https://velog.io/@yoonsy/Homebrew로-Anaconda-설치-및-conda-가상환경-셋팅하기
•
OpenAI Prompt Engineering Guide, https://platform.openai.com/docs/guides/prompt-engineering