1. QuerySet 기본
가. QuerySet
1) QuerySet 정의
•
일련의 조작을 통해 얻어진 모델 객체 집합
2) QuerySet 구성
•
QuerySet 구성: 1개의 메인 쿼리(Query)와 0개 이상의 추가 쿼리(QuerySet)으로 구성됨
→ 추가 쿼리의 경우, prefetch_related() 호출에 따라 생성됨
3) QuerySet 내부
•
QuerySet 내부 요소
→ query: 메인 쿼리
→ _prefetch_related_lookups: 역방향 참조 필드
→ _result_cache: 메인 쿼리와 추가 쿼리의 결과를 임시로 저장하는 캐쉬
→ _iterable_class: QuerySet의 반환 포맷
class QuerySet:
query = Query()
_prefetch_related_lookups = ('fertilizations')
_result_cache = [Model(1), Model(2), Model(3).....]
_iterable_class = ModelIterable
Python
복사
4) Chaining filters
•
QuerySet에 대한 정제 작업 결과가 QuerySet 형태로 반환되어, 반환결과에 다른 정제 작업을 추가할 수 있다
>>> Entry.objects.filter(
... headline__startswith='What'
... ).exclude(
... pub_date__gte=datetime.date.today()
... ).filter(
... pub_date__gte=datetime.date(2005, 1, 30)
... )
SQL
복사
나. RawQuerySet
1) RawQuerySet
•
RawQuerySet을 작성하는 것은 메인쿼리를 직접 작성한다는 것
2) query method 활용 제한
•
RawQuerySet 작성 시, 메인 쿼리에 사용되는 메소드(.annotate, .select_related 등) 사용 불가
3) prefetch_related 활용 가능
•
RawQuerySet을 작성하는 것에 추가쿼리 작성은 포함되어 있지 않음
→ 추가 쿼리 메소드 활용 가능
# 나-1)에서 작성된 queryset과 유사 동작
raw_queryset = (User.objects
.raw('SELECT * , fertiliztion_count,
FROM CattleBreeding m
JOIN on m.f_id = f.id
JOIN on m.cat_id = cat.id')
.prefetch_related('cat_fertilizations', 'cat_pregnancy')
)
Python
복사
2. QuerySet API
가. Methods Returning QuerySet
1) filter
•
전달된 조회 매개변수(lookup parameters)에 매칭되는 objects로 구성된 QuerySet 반환
→ 복수의 매개변수가 전달될 경우, 기본적으로 AND 연산으로 처리됨
→ 전달된 매개변수를 토대로 OR 연산으로 작업할 경우, Q objects 활용
2) exclude
•
filter와 반대
3) annotate
•
QuerySet 내 각각의 Object에 대해 일련의 Query Expression에 따라 추가적인 정보 제공
→ keyword 인자를 전달함으로써 추가적인 정보에 대한 이름을 지정할 수 있음
→ Custmoers.objects.annotate(city_count=Count('city')
SELECT City,
COUNT(City) AS CITY_COUNT
FROM Customers
GROUP BY City;
SQL
복사
4) alias
•
이어서 사용될 chaining filter에서 재사용하기 위해 일련의 Query Expression에 따라 정보를 제공하는 것
→ annotate의 경우 Query Expression에 추가적인 정보를 주석화하는 것이 목적이지만 alias의 경우 다음 chaining filter에서 재사용되는 것이 목적
→Custmoers.objects.alias(city_count=Count('city').filter(city_count__gt=5)
SELECT City,
COUNT(City) AS CITY_COUNT
FROM Customers
GROUP BY City
HAVING CITY_COUNT > 5
ORDER BY City;
SQL
복사
•
바로 이어서 chaining filters 사용 가능 경우
→ annotate, exclude, filter, order_by, update
•
추가 주석처리 후 chaining filters 사용 가능 경우
→ 위 메소드 외의 메소드를 이어서 사용할 경우(ex aggregate)
→Blog.objects.alias(entries=Count('entry')).annotate(entries=F('entries'),).aggregate(Sum('entries'))
5) distinct
6) values, values_list
•
values: QuerySet 내 객체에 대해 model instance가 아니라 dictionary 형태로 반환
# This list contains a Blog object.
>>> Blog.objects.filter(name__startswith='Beatles')
<QuerySet [<Blog: Beatles Blog>]>
# This list contains a dictionary.
>>> Blog.objects.filter(name__startswith='Beatles').values()
<QuerySet [{'id': 1, 'name': 'Beatles Blog', 'tagline': 'All the latest Beatles news.'}]>
SQL
복사
•
values_list: QuerySet 내 객체에 대해 model instance가 아니라 튜플 형태로 반환
>>> Entry.objects.values_list('id', 'headline')
<QuerySet [(1, 'First entry'), ...]>
>>> from django.db.models.functions import Lower
>>> Entry.objects.values_list('id', Lower('headline'))
<QuerySet [(1, 'first entry'), ...]>
SQL
복사
→ values_list에 매개변수로 flat=True을 전달하면 소괄호가 없는 순수한 값으로 이루어진 리스트를 전달 가능
list(Farm.objects.values_list('id', flat=True))
# [97, 96, 95, 2, 1]
list(Farm.objects.values_list('id'))
# [(97,), (96,), (95,), (2,), (1,)]
list(Farm.objects.values('id'))
# [{'id': 97}, {'id': 96}, {'id': 95}, {'id': 2}, {'id': 1}]
Python
복사
→ values, values_list 사용 목적: QuerySet 내 객체를 모델 인스턴스로 다루지 않고 내부의 값만을 출력함으로써 성능면에서 이점을 활용할 경우
→ 더이상 내부 객체를 모델 인스턴스로 사용하지 않기 때문에 다중관계(1:N, N:M) 관계에서 사용하는 것은 부적절
# author와 entry의 관계가 1:N일 경우, 같은 author에 대해 entry의 개수만큼 열이 반복됨
>>> Author.objects.values_list('name', 'entry__headline')
<QuerySet [('Noam Chomsky', 'Impressions of Gaza'),
('George Orwell', 'Why Socialists Do Not Believe in Fun'),
('George Orwell', 'In Defence of English Cooking'),
('Don Quixote', None)]>
Python
복사
나. Methods Not Returning QuerySet

이하 메소드의 경우, Lazy loading이 아니라 매번 호출 시 매번 DB에 query함
1) count
•
QuerySet에 매칭되는 객체의 수를 정수형 타입으로 반환함
# Returns the number of entries whose headline contains 'Lennon'
Entry.objects.filter(headline__contains='Lennon').count()
Python
복사
•
count는 SELECT COUNT(*)에 매칭되므로 최종적으로 원하는 것이 객체의 목록이 아니라 연산된 숫자라면 count를 사용하는 것이 바람직함
→ 관련 객체의 목록을 모두 파이썬으로 가져와서 len()을 사용하는 것은 성능 상 이점이 없음
→ 단, 객체의 총 수 외에도 해당 쿼리셋으로 추가적인 작업을 해야할 경우 len() 활용 권장
2) latest(max), earliest(min)
•
latest: 테이블 내 가장 마지막 객체를 반환
→ 일종의 최대값 반환
•
erliest: 테이블 내 가장 앞의 객체를 반환
•
객체의 순서는 메소드에 전달된 매개변수를 기준으로 함
→ Entry.objects.latest('pub_date', '-expire_date')
→ 순서 우선순위는 pub_date, expire_date의 순서와 같음
3) first, last
•
first: QuerySet 내 가장 첫번째 객체를 반환함
•
last: QuerySet 내 가장 마지막 객체를 반환함
# 이하 두개의 QuerySet의 연산결과는 동일하다
p = Article.objects.order_by('title', 'pub_date').first()
try:
p = Article.objects.order_by('title', 'pub_date')[0]
except IndexError:
p = None
Python
복사
5) exists
•
QuerySet 내 특정 객체가 존재하면 True 반환, 없다면 False 반환
entry = Entry.objects.get(pk=123)
if some_queryset.filter(pk=entry.pk).exists():
print("Entry contained in queryset")
Python
복사
6) bulk_create
•
리스트 형태로 bulk_create 메소드에 전달
dogs = []
dogs.append(Dog(name='test'))
dogs.append(Dog(name='hello'))
dogs.append(Dog(name='MJ'))
Dog.objects.bulk_create(dogs)
Python
복사
7) bulk_update
•
수정된 모델 객체를 리스트 형태로 bulk_update로 전달
•
모델 내 수정 대상이 되는 필드를 리스트 형태로 전달
# dogs from 'bulk_create' example
dogs[0].name='1'
dogs[1].name='2'
dogs[2].name='3'
Dog.objects.bulk_update(dogs, ['name'])
Python
복사
8) retrive in bulk
•
in_bulk(id_list=None, , field_name='pk')
•
첫번째 인자는 인덱스 리스트
→ 인덱스에 해당하는 필드명의 기본값은 ‘id’임
retrived_objects = Blog.objects.in_bulk(id_list)
Python
복사
•
두번째 매개변수로 필드명 지정 가능
→ field_name으로 PK 필드명을 지정할 수 있음
→ filed_name은 반드시 Unique 제약이 걸려 있거나 distinct로 유일성이 보장된 필드여야 함
Blog.objects.distinct('name').in_bulk(field_name='name')
Python
복사
9) delete in bulk
•
filter 메소드로 해당되는 객체에 대해 일괄 조회 후 삭제
id_list = [id for id in range(0, 10)]
Blog.objects.filter(pk__in=id_list).delete()
Python
복사
라. Field Lookups
•
조건 키워드
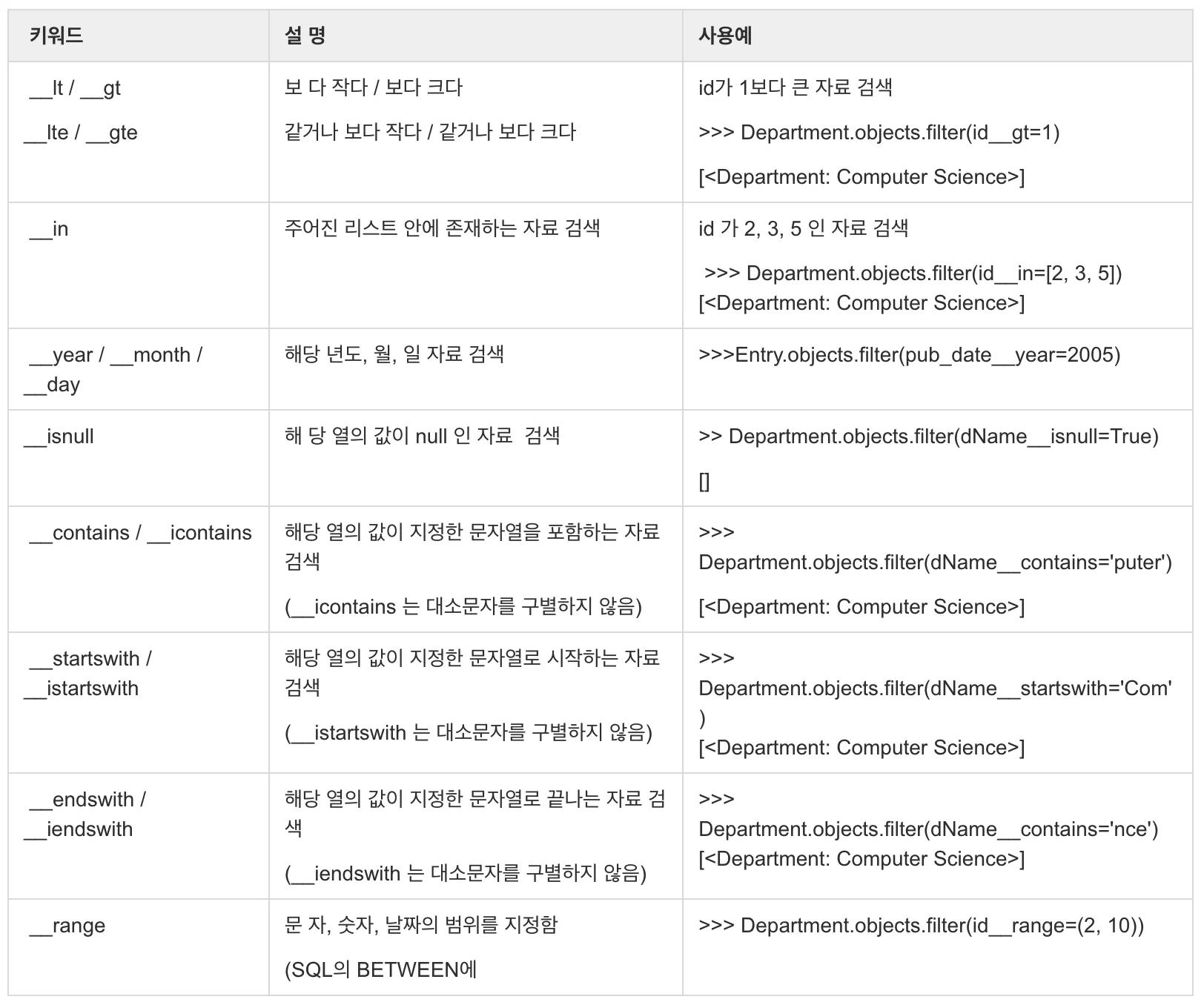
image from https://brownbears.tistory.com/63
3. Aggregation
집계 방식은 'QuerySet 전체에 대한 집계'와 'QuerySet 내 각각의 객체에 대한 집계'로 나눌 수 있음
가. 전체에 대한 집계
1) aggregate method
•
QuerySet을 통해 집계된 값(aggregate values)을 dictionary 형태로 반환함
>>> q = Blog.objects.aggregate(number_of_entries=Count('entry'))
{'number_of_entries': 16}
Python
복사
나. 각 객체에 대한 집계
1) annotate method
•
aggregate method와 사용법은 동일함
→ keyword 명시, 집계함수 사용 등
2) annotate vs aggregate
•
annotate의 경우 QuerySet 객체 내 하위 객체에 대한 집계 결과를 각 객체에 명시하여 반환
→ aggregate의 경우 QuerySet 객체를 대상으로 집계된 결과 반환
•
annotate의 경우 반환 시 QuerySet 형태이므로 반환결과 재사용 가능
→ aggregate의 경우 name-value 쌍으로 이뤄진 dictionary 형태로 반환
3) annotate 주의사항
•
annotate 활용하여 복수의 테이블에 걸쳐 집계 메소드 이용 시 의도치 않은 결과 반환 가능
→ subquery 대신 join을 사용함에 따라 아래와 같은 결과 발생??
>>> book = Book.objects.first()
>>> book.authors.count()
2
>>> book.store_set.count()
3
>>> q = Book.objects.annotate(Count('authors'), Count('store'))
>>> q[0].authors__count
6
>>> q[0].store__count
6
JavaScript
복사
다. Aggregation & Joining
1) 사용법
•
double underscore 사용하여 joined field 사용
# annotate 적용
Store.objects.annotate(min_price=Min('books__price'), max_price=Max('books__price'))
# aggregate 적용
Store.objects.aggregate(min_price=Min('books__price'), max_price=Max('books__price'))
Python
복사
2) Deep Joined Field
•
double underscore 연달아 적용하여 double joined field 사용
Store.objects.aggregate(youngest_age=Min('books__authors__age'))
Python
복사
라. With other methods
1) filter & exclude
2) values
•
values로 전달한 매개변수에 따라 'group by'된 값을 전달한다
# 모든 작가('name' 중복 관계 없이)의 책(하위 객체)의 평점 평균에 대해 집계
Author.objects.annotate(average_rating=Avg('book__rating'))
# name이 같은 작가는 하나로 통합된 상태에서 name이 중복된 작가의 모든 책에 대한 평점 평균을 집계
Author.objects.values('name').annotate(average_rating=Avg('book__rating'))
Python
복사
•
'group by'하여 의도한 결과를 반환하기 위해 'annotate'와 'values'의 위치를 신경써야 한다
4. Query-related tools
가. related_name
1) 정방향 관계에서 설정
•
외래키를 가지고 있는 모델에서 related_name 설정 방법
→ 외래키를 가지고 있는 모델을 참조하고 있는 모델(부모 모델)에서 외래키를 가지고 있는 모델을 할당할 필드에 대한 이름 지정
•
1:1 관계 예제
•
1:N 관계 예제
2) 역방향 관계에서 설정
•
외래키를 가지고 있지 않은 모델에서 related_name 설정 방법
→ 외래키가 없는 모델(부모 모델)에서 외래키를 가지고 있는 모델을 할당할 필드에 대한 이름 지정
•
1:1 관계
•
1:N 관계
나. F()
1) 정의
•
정의: 모델 필드 값 표현
→ 변형된 모델 필드 값, annotated column 포함
2) 특징
•
F()로 지정된 필드에 대해 연산은 파이썬 메모리로 가져오지 않고 DB 내에서 수행함
•
복수의 파이썬 쓰레드가 DB 내 특정 필드를 동시 참조하여 작업을 수행할 때, 각각의 쓰레드는 다른 쓰레드에 의해 변형된 필드가 아니라 원본 필드 참조
→ RDBMS는 트랜잭션의 동시성을 보장하기 때문임. 이를 파이썬 코드상으로 구현하는 것은 비용이 큼
3) F() in filters
•
filter() 내 전달할 매개변수로 DB 내 필드(파이썬 변수나 상수가 아니라)를 사용할 경우 활용 가능
# Entry 객체 중 number_of_comments 필드 값이 number_of_pingbacks 필드 값 보다 큰 경우 조회
Entry.objects.filter(number_of_comments__gt=F('number_of_pingbacks'))
Python
복사
•
double underscore: 모델 간 관계를 확장하여 JOIN 연산을 통해 지정된 필드를 참조함
# authors의 이름과 blog의 이름이 같은 경우 조회
Entry.objects.filter(authors__name=F('blog__name'))
Python
복사
4) F() with annotations
•
모델 내 필드를 참조하여 동적 필드 생성
company = Company.objects.annotate(
chairs_needed=F('num_employees') - F('num_chairs'))
Python
복사
•
동적 필드 생성 시 참조하는 필드의 데이터타입이 다를 경우, 원하는 데이터타입을 명시
from django.db.models import DateTimeField, ExpressionWrapper, F
Ticket.objects.annotate(
expires=ExpressionWrapper(
F('active_at') + F('duration'), output_field=DateTimeField()))
Python
복사
다. Q()
1) 정의
•
Complex SQL 조건 표현식
2) 특징
•
QuerySet 조건식을 복합적 구성할 때 활용됨
→ QuerySet method, filter()에 전달된 매개변수는 AND 연산으로 전달됨
•
F()와 마찬가지로 Q() 표현식으로 지정된 조건은 DB 내에서 연산됨
3) Complex lookups
•
AND, OR 연산 적용
→ Q 산술식이 나열되면 AND로 묶임
→ | 연산자를 전달함으로써 OR로 묶임
Poll.objects.get(
Q(question__startswith='Who'),
Q(pub_date=date(2005, 5, 2)) | Q(pub_date=date(2005, 5, 6))
)
## Same as above
SELECT * from polls WHERE question LIKE 'Who%'
AND (pub_date = '2005-05-02' OR pub_date = '2005-05-06')
Python
복사
•
파이썬 매개변수 조건 보다 Q() 조건식이 선 정의돼야 함
# VALID QUERY
Poll.objects.get(
Q(pub_date=date(2005, 5, 2)) | Q(pub_date=date(2005, 5, 6)),
question__startswith='Who',
)
# INVALID QUERY
Poll.objects.get(
question__startswith='Who',
Q(pub_date=date(2005, 5, 2)) | Q(pub_date=date(2005, 5, 6))
)
Python
복사
6. Query Optimization
가. SELECT N+1 Problem
1) 현상
•
연관 관계를 가진 엔티티의 레코드를 N건 조회 시, 조회한 엔티티가 참조하는 엔티티의 속성을 조회할 때 추가적으로 관련 쿼리를 N건 조회하는 현상
•
예를 들어, Author:Post=1:N 관계이고 Post의 레코드가 3건일 때, 각 포스트의 Author의 이름(name)을 조회하면 생성되는 쿼리의 수는 4(1+3)개가 된다
→ 1건: 모든 Post 조회
→ 3건: 각각의 Post와 연관된 Author 이름 조회
2) 해결방법
•
정방향, 역방향 관계를 고려하여 쿼리 요청을 최소화하는 방향으로 접근
•
쿼리 요청의 최소화가 반드시 성능 향상으로 연결되지는 않음
→ 다만, 다수의 경우 쿼리 요청의 최소화가 성능 향상으로 이어짐
3) select_related vs prefetch_related
•
대상 관계
→ 정방향 관계(1:1, 1:N): select_related 사용
→ 역방향 관계(N:1, N:M): prefetch_related 사용
→ 정방향 역방향 혼합 관계: OneToOne 필드와 Foreign Key 대상으로 select_related 사용하고 ManyToMany 필드에는 prefetch_related 사용
•
동작방식
→ select_related: JOIN 쿼리를 생성하여 DB 내 데이터 조회
→ prefetch_related: 각각의 모델에 대한 쿼리를 생성하여 DB 내 데이터를 가져온 후 웹 어플리케이션에서 JOIN에 해당하는 작업 수행
나. select_related
1) 동작 방식
•
정방향 관계에서 DB 조회 시 연관된 데이터를 한번에 조회함
•
select_related 미사용 예시
# Hits the database.
e = Entry.objects.get(id=5)
# Hits the database again to get the related Blog object.
b = e.blog
Python
복사
code from https://docs.djangoproject.com/en/4.0/ref/models/querysets/
•
select_related 사용 예시
# Hits the database.
e = Entry.objects.select_related('blog').get(id=5)
# Doesn't hit the database, because e.blog has been prepopulated
# in the previous query.
b = e.blog
Python
복사
code from https://docs.djangoproject.com/en/4.0/ref/models/querysets/
2) 사용 방법
•
•
중첩 연관 관계에서도 효과적으로 활용 가능
→ 중첩 연관 관계의 사용 예시
# Hits the database with joins to the author and hometown tables.
b = Book.objects.select_related('author__hometown').get(id=4)
p = b.author # Doesn't hit the database.
c = p.hometown # Doesn't hit the database.
# Without select_related()...
b = Book.objects.get(id=4) # Hits the database.
p = b.author # Hits the database.
c = p.hometown # Hits the database.
Python
복사
code from https://docs.djangoproject.com/en/4.0/ref/models/querysets/
→ 위 코드의 모델 관계
class City(models.Model):
# ...
pass
class Person(models.Model):
# ...
hometown = models.ForeignKey(
City,
on_delete=models.SET_NULL,
blank=True,
null=True,
)
class Book(models.Model):
# ...
author = models.ForeignKey(Person, on_delete=models.CASCADE)
Python
복사
code from https://docs.djangoproject.com/en/4.0/ref/models/querysets/
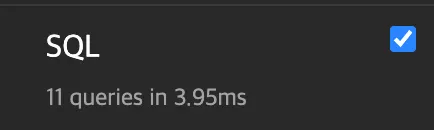
3) 성능 비교
•
1:1 or 1:N 관계에서 외래키를 필드로 가진 모델의 queryset에서 select_related 메소드의 매개변수로 외래키를 전달
→ before
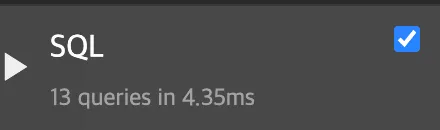

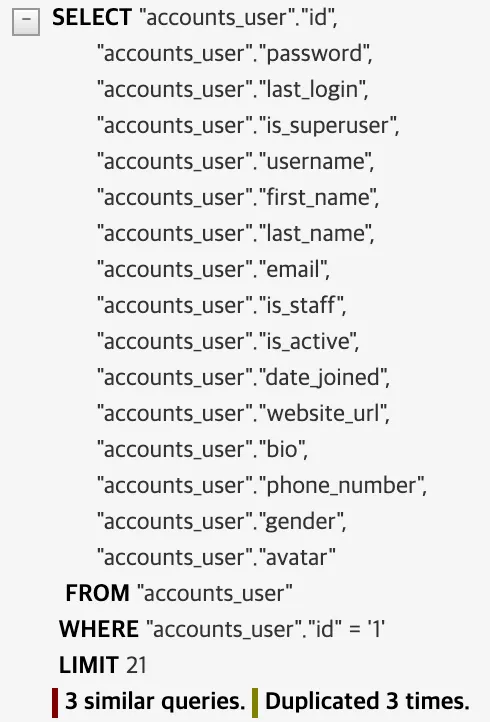
→ after

다. prefetch_related
1) 동작 방식
2) 사용 방법
•
•
select_related, prefetch_related 함께 활용 가능
→ prefetch_related만 사용할 경우, 3개 쿼리 발생(restaurants, pizzas, toppings)
Restaurant.objects.prefetch_related('best_pizza__toppings')
Python
복사
→ select_related, prefetch_related 함께 활용할 경우, 2개 쿼리 발생(restaurants & pizzas, toppings)
Restaurant.objects.select_related('best_pizza').prefetch_related('best_pizza__toppings')
Python
복사
→ 이하 참고 모델
class Topping(models.Model):
name = models.CharField(max_length=30)
class Pizza(models.Model):
name = models.CharField(max_length=50)
toppings = models.ManyToManyField(Topping)
def __str__(self):
return "%s (%s)" % (
self.name,
", ".join(topping.name for topping in self.toppings.all()),
)
class Restaurant(models.Model):
pizzas = models.ManyToManyField(Pizza, related_name='restaurants')
best_pizza = models.ForeignKey(Pizza, related_name='championed_by', on_delete=models.CASCADE)
Python
복사
3) 성능 비교
•
M:N 또는 N:1 관계에서 외래키를 필드로 가진 모델의 queryset에서 prefetch_related 메소드의 매개변수로 해당 외래키 전달
→ before
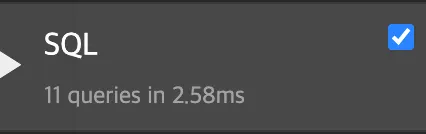


→ after
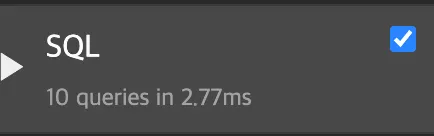

7. know-hows
가. Django Migration
1) Migration Process
•
모델 변경사항 발생
→ makemigrations 명령 실행
→ makemigrations 명령에 따라 migration 파일 내 모델 변경사항에 대한 조작 명령 생성
•
migration 파일 생성
→ migrate 명령 실행
→ 모델 변경사항이 실제 DB에 반영됨
2) Migration File Managing
•
migration file 압축 명령을 통해 다수의 migration file을 줄일 수 있음
→ squashmigrations
•
migration file 임의 삭제 금지
→ migration file은 DB에 모델에 대한 변경이력이 누적되어 있음
•
migration file간 종속성 존재
→ migration file 내 dependencies 항목 참고
dependencies = [
migrations.swappable_dependency(settings.AUTH_USER_MODEL),
]
Python
복사
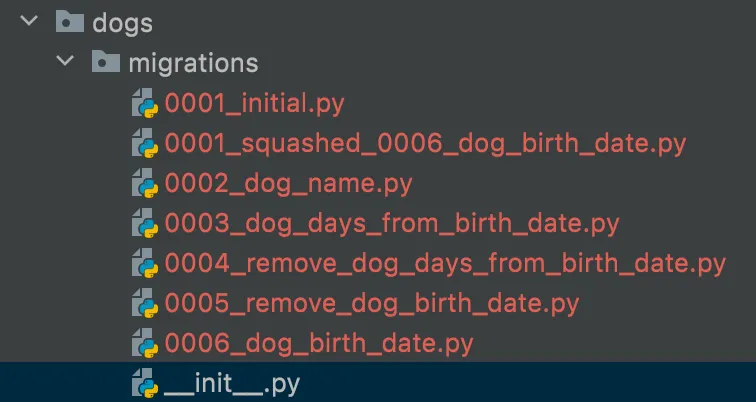
3) Squash Migration Files
•
Before
•
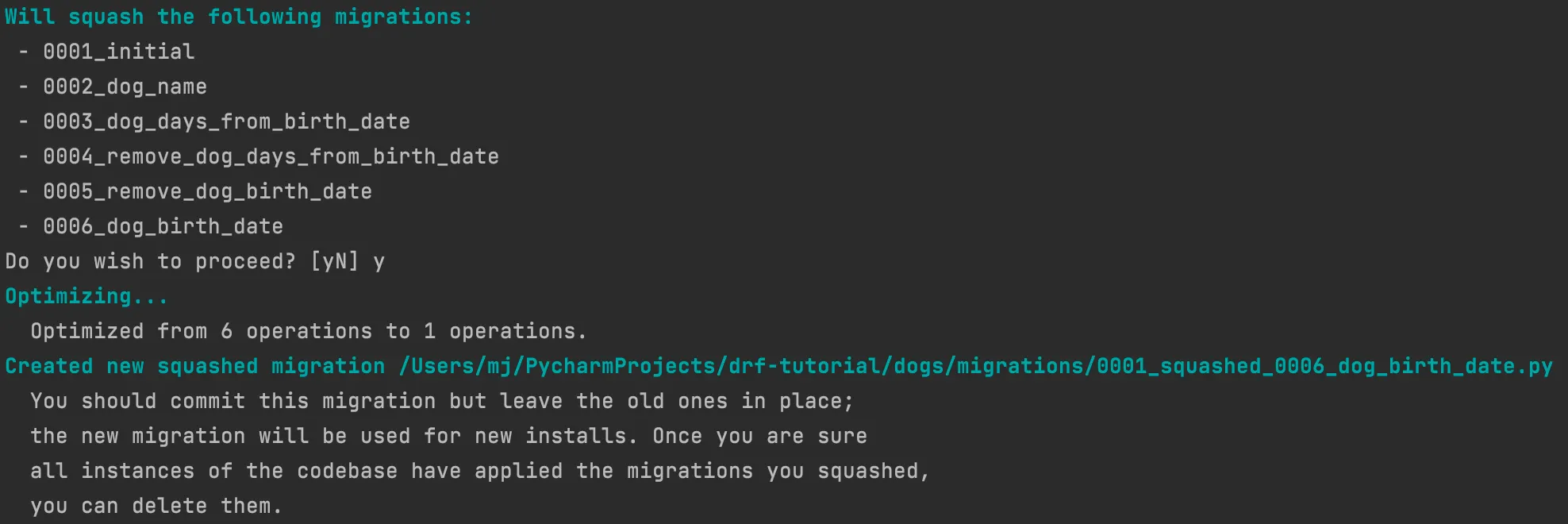
squashmigrations 명령 실행
→ python manage.py squashmigrations dogs 0006
→ squashmigrations process
•
After
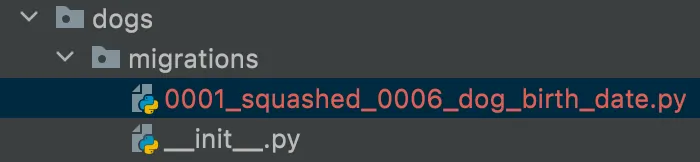
4) Squashing Migration Process
Squash 전후의 모든 migration file이 django_migrations 테이블 이력으로 남게되는 단점이 있음
•
기존 데이터 백업
→ 기존 DB 내 데이터 백업(export SQL Dump)
→ DB에서 migration files 관리하고 있다면 migration file도 백업
•
Squash 명령 실행
→ python manage.py squashmigrations <app> <migration file>
→ ex) python manage.py squashmigrations cow 0006
•
기존 migration file 제거
→ squash 명령에 따라 불필요해진 migration file 삭제
→ DB(django_migrations)에서 관리하는 migration file 목록에서 기존 migration file 제거
•
DB 내 관련 테이블 제거
→ squashed migration file에 의해 migrate 실행 시 정상적으로 DB 테이블 생성되는 지 확인하는 절차
•
빌드 및 배포(또는 migrate 명령 실행)
→ python manage.py migrate <app>
→ ex) python manage.py migrate cow
•
데이터 복원
→ 백업한 SQL Dump를 import하여 새로 생성된 DB 테이블에 기존 데이터 복원
5) Recommended Migration Process
다음의 방법으로 feature별로 미적용된 마이그레이션 파일을 관리 권장
•
주의사항!!
→ 마이그레이션 파일을 축약 후 migrate 명령 시, DB 내 새로운 필드를 추가하고 그 안에 데이터를 갱신한 것이 있다면 모두 제거됨
→ 예를 들어, vaccine과 vaccination 모델 간 M:N 관계를 구축하고 연결 모델을 생성 및 그 안에 데이터를 추가함. 그 후에 마이그레이션 파일을 축약하고 migrate 명령을 실행 했다면 연결 모델 내 추가한 데이터는 모두 제거됨
•
작업 전 상태
→ 0088 ~ 0090 마이그레이션 파일 존재
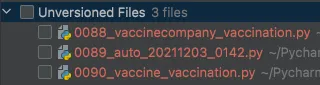
•
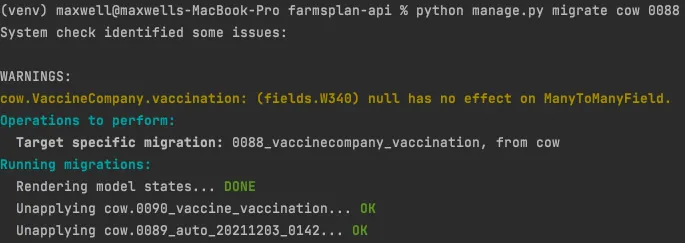
migrate 적용 시점 변경
→ 0090, 0089 마이그레이션 파일 미적용
→ python manage.py migrate <app> <0088 migration file>
→ or 모든 migration 파일을 하나로 관리할 경우: python manage.py migrate <app> zero
•
migration 파일 삭제
→ 0088 이후(0089 파일부터 포함)에 생성된 마이그레이션 파일 삭제
→ or 모든 migration 파일을 하나로 관리할 경우: 모든 마이그레이션 파일 삭제(__init.py__ 제외)

•
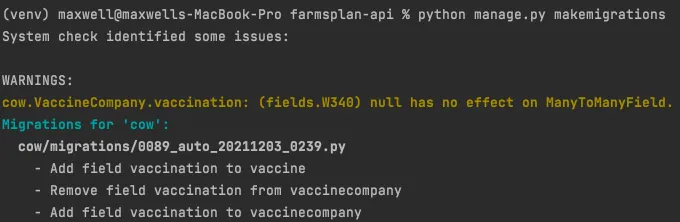
•
migration 파일 생성 확인
→ 0089 마이그레이션 파일 재생성(기존의 0089, 0090의 DDL 모두 포함)
•
django_migrations 테이블 내 기존 이력 제거
→ django_migrations 테이블 내 기존 이력 데이터(migration files)가 남아있다면 재생성된 migration file을 제외한 나머지 파일을 테이블 내에서 제거
6) Recommanded Migration Process 적용 결과
•
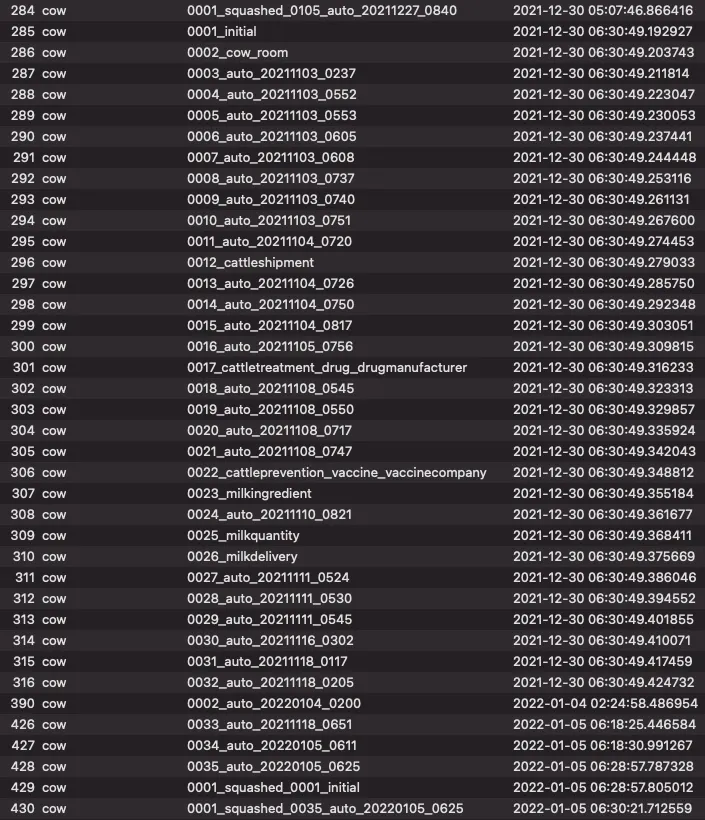
Recommanded Migration Process 적용 후, django_migrations 테이블에서 아래와 같은 결과 확인
•
Before(in django_migrations table)
•
After(in django_migrations table)

7) DB Data 보존한 상태에서 migration file 정리 방법
•
이하 참고

•
기본이 되는 migration file이 우선 적용되지 않으면 아래와 같은 에러 발생
→ django.db.migrations.exceptions.InconsistentMigrationHistory: Migration admin.0001_initial is applied before its dependency account.0001_initial on database 'default'.
ex) user 모델이 정의된 장고 앱이 migrate되기 전에 user 모델을 참조하는 모델들이 정의된 장고 앱이 먼저 migrate되면 에러 발생함.
→ 에러 해결을 위해 user 모델을 참조하는 모델이 정의된 장고 앱을 settings.py와 urls.py에서 주석처리하고 먼저 user 모델을 migrate함. 이때 python manage.py migrate --fake-initial 명령으로 migrate해야 이미 존재하는 테이블 에러를 방지할 수 있음
•
reflect migration files with renamming backoffice app to common app
→ 1. comment out pig, cow, hanwoo apps
→ 2. write down python manage.py migrate --fake-initial in startup file
→ 3. remove comments from pig, cow, hanwoo apps
→ 4. python manage.py migrate --fake-initial
→ 5. remove command of fake migration
나. 관계 설정
1) reverse_name
2) limit_choices_to
3) M:N 관계
•
ManyToMany 필드 정의: 본 필드를 직접 조작할 모델에 정의하는 것을 권장함
•
blank 설정: True 설정 시 부모 모델이 없는 경우에도 데이터 입력 가능
→ 기본값은 False로 설정되어 있음
•
many 설정: ManyToMany 관계이므로 역방향, 정방향 관계 시 관련 필드에 many=true 설정해야 함
•
역방향 관계
→ 코드 참고
•
정방향 관계
→ 코드 참고
다. Bulk Processing
1) bulk_create()
•
객체 리스트를 매개변수로 전달하여 리스트 내 모든 객체에 대한 bulk insert 동작
→ insert query가 n번 반복되는 것을 1번으로 줄일 수 있음
•
예시
sales = []
for row in rows[1:]:
sales.append(Dog(farm_id=1, date=date, weight=weight, price=price))
DogSale.objects.bulk_create(sales)
Python
복사
2) bulk_update()
•
update 대상 필드 리스트를 두번째 매개변수로 전달
Entry.objects.bulk_update(sales, ['left_hand', 'right_hand'])
Python
복사
3) bulk_delete()
•
Entry.objects.all().delete()
라. Transaction
1) @transaction.atomic
•
메소드 전체가 트랜잭션 대상으로 지정하는 방법
from django.db import IntegrityError, transaction
@transaction.atomic
def viewfunc(request):
create_parent()
add_children()
JavaScript
복사
2) with
•
메소드 내 일부 영역만 트랜잭션 대상으로 지정하는 방법
from django.db import IntegrityError, transaction
@transaction.atomic
def viewfunc(request):
create_parent()
with transaction.atomic():
generate_relationships()
add_children()
JavaScript
복사
3) exception
•
transaction.atomic 밖에서 exception handling 가능
→ transaction.atomic 내부에서 트랜잭션에 대한 불린값으로 트랜잭션을 제어하는데 내부에서 예외가 발생하면 해당 불린값에 대한 처리 불능에 따른 에러 발생
from django.db import IntegrityError, transaction
@transaction.atomic
def viewfunc(request):
create_parent()
try:
with transaction.atomic():
generate_relationships()
except IntegrityError:
handle_exception()
add_children()
Python
복사
Reference
•
related_name 설정, https://daeguowl.tistory.com/58
•
•
know-hows by Lee, 이진석, 파이썬/장고 웹서비스 개발 완벽 가이드, https://www.inflearn.com/course/파이썬-장고-웹서비스/dashboard
•
Transaction in Bulk, https://docs.djangoproject.com/en/4.0/topics/db/transactions/
•
Fields look up, https://docs.djangoproject.com/en/3.2/ref/models/querysets/#id4
•
select_related vs prefetch_related
•
prefetch_relaated, https://docs.djangoproject.com/ko/2.1/ref/models/querysets/#prefetch-related
•
DB 수정하지 않고 migration file만 변경, https://wikidocs.net/9926