1. DB의 용도와 역할
가. 데이터 조작
•
데이터 검색(Read)
•
데이터 갱신(Insert, Update, Delete)
나. 동시성 제어
•
여러 사용자가 동시에 같은 파일에 대해 갱신하려고 할 때, 데이터베이스는 어떻게 처리할 것인가?
→ 옵션1) 최초로 파일을 사용하는 사용자가 있으면 그 다음의 사용자는 파일을 사용할 수 없음
→ 옵션2) 최초로 파일을 사용하는 사용자가 있으면 그 다음의 사용자는 해당 파일을 읽기 전용으로 사용할 수밖에 없음
→ 옵션3) 최초로 파일을 사용하는 사람이 있어도 그 다음의 사용자는 해당 파일을 읽고 갱신할 수 있음
다. 장애 대응
•
데이터베이스 장애를 어떻게 대비할 것인가?
→ 심장정책: 데이터베이스를 구성하는 요소 하나하나에 신경써서 에러 발생 가능성을 사전 차단
→ 신장정책: 미래에 발생할 에러를 모두 예측하고 예방하는 것은 불가능하므로 에러 발생에 대비함
라. 보안
•
데이터베이스의 보안이라는 목표를 어떻게 달성할 것인가?
→ 사용자의 조작 영역을 클라이언트 계층으로 한정함으로써 데이터베이스를 직접 조작할 수 없음
→ 데이터베이스의 데이터에 대한 접근권한을 상승시켜서 접근 자체를 어렵게 함(심지어 DB 관리자도 접근이 어려움)
마. 정합성과 무결성
•
참조 정합성: 데이터가 모순 없이 일관되게 일치함
→ Record의 단일성을 보증
•
데이터 무결성: 데이터가 일관되게 정확함
2. RDBMS
가. RDBMS의 주요한 특징
•
높은 수준의 트랜잭션 지원
•
데이터 정합성을 높이기 위한 설계 노하우 발달
→ 정규화, ER 다이어그램 등
•
관계 설정을 통해 데이터를 여러 개의 테이블에 나누어 저장함으로써 데이터의 중복을 피함
→ 데이터의 무결성을 보장할 수 있음
나. 트랜잭션
1) 트랜잭션이란
2) 트랜잭션의 성질
•
Atomicity: 하나의 트랜잭션으로 묶인 쿼리의 집합은 실행 or 실패
→ 작업의 집합 중 일부만 실행될 수 없음
•
Consistency: 트랜잭션이 정상적으로 실행되면 DB는 항상 일관성 있는 상태를 유지한다
→ 제약조건을 위반하는 트랜잭션은 실행이 중단된다
•
Isolation: 특정 트랜잭션 실행 시, 다른 트랜잭션이 끼어들 수 없음
→복수의 사용자가 접근하더라도 마치 하나의 쿼리는 하나의 사용자가 사용하듯이 작동해야 한다
•
Durability: 트랜잭션이 정상적으로 실행되면 DB에 영원히 반영돼야 함
→ 시스템 장애, 특정 작업이 발생해도 정상적으로 실행된 트랜잭션은 DB에 지속적으로 남아야 한다
다. 정규화
•
SQL 첫걸음 정규화 챕터 참고
라. ERD
•
ERD(Entity Relationship Diagram)
→ Entity 간 관계 도식화
→ Relationship: 두 개 이상의 엔티티 간의 연관성
•
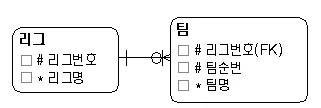
종속관계
→ 팀이 리그의 존재에 의존하는 관계
→ 리그가 존재하지 않는다면 팀도 존재 X
→ 리그(부모 엔티티), 팀(자식 엔티티)
→ 엔티티 관계의 20% 차지
→ 종속관계 장점: 자식 엔티티의 존재로 부모 엔티티의 존재 보장 가능
•
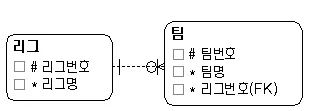
참조관계
→ 팀이 리그의 속성(리그번호)에 의존하는 관계
→ 리그가 존재하지 않더라도 팀은 존재 O
→ 리그(상위 엔터티, Referenced), 팀(하위 엔터티, Referencing)
→ 엔티티 관계의 80% 차지5
→ 참조관계 장점: 요구사항 변경에 따라 구조를 쉽게 수정 가능
•
식별 관계 vs 비식별 관계
→ 식별 관계: 종속관계와 매칭, 부모 엔티티의 PK가 자식 엔티티의 FK이자 PK O
→ 비식별 관계: 참조관계와 매칭, 부모 엔티티의 PK가 자식 엔티티의 FK이지만 PK X
•
키 제약조건
→ Foreign Key: 외래키로 지정된 열은 반드시 다른 테이블의 기본키 열을 가리켜야 함
→ 다른 테이블의 기본키 값이 아니라면 NULL이어야 함
→ Primary Key: 기본키는 테이블의 모든 행을 유일하게 구분할 수 있어야 함
→ Check: 특정 열의 값이 특정 조건에 부합해야 함
CREATE TABLE STUDENT (
ID int ,
Name varchar(255) ,
Age int,
CHECK (Age>=18)
);
SQL
복사
마. 용어정리
1) 용어 비교 정리
•
용어가 다른 이유: 개념적 카테고리에 따라 다루는 내용이 크게 다르기 때문
→ RDBMS의 주요 설계 이론이 관계형 모델이지만 여타 다른 개념들도 복합적으로 섞여서 동작하기 때문에 여러 차이점이 존재함
기본 보기
Search
2) 기타 주요 용어 정리
•
도메인(Domain): 하나의 속성이 가질 수 있는 값의 유한한 집합
•
카디널리티(Cardinality): 하나의 Table에 포함된 Row의 수
•
차수(Degree): 하나의 Table에 포함된 Column의 수
바. 관계설정
•
1:1: 부모 테이블 하나의 행이 자식 테이블 하나의 행과 매칭
•
1:N: 테이블 A의 한 행은 테이블 B의 여러 행에 연결 될 수 있지만 테이블 B의 한 행은 테이블 A의 한 행에만 연결되는 형태
•
N:M
→ 테이블 A의 한 행이 테이블 B의 행 여러개에 연결, 그 반대의 경우도 연결된 형태
→ 다대다 관계 테이블에서는 쿼리 결과 중복된 데이터가 나올 가능성이 있기 때문에 테이블 사이를 연결해주는 연결 테이블을 만들어서 일대다의 관계로 단순하게 할 필요가 있음
3. NoSQL
가. NoSQL의 주요한 특징
•
병렬처리에 따른 수평 확장 용이
→ RDBMS: 수직적 확장 용이
•
높은 수준(나노초, ns)의 응답속도
→ RDBMS 응답속도: 마이크로초, ms
•
트랜색션을 지원하지 않거나 낮은 수준에서 지원함
•
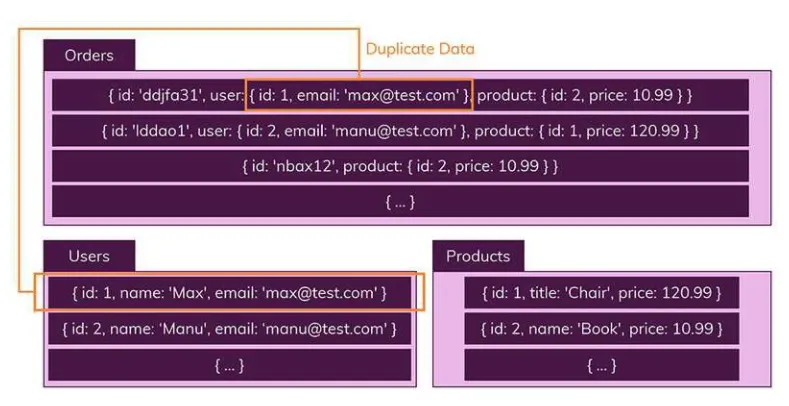
관계있는 데이터를 분리하지 않고 동일한 컬렉션에 저장
→ Orders라는 콜렉션을 만들기 위해 Users와 Products라는 콜렉션에서 필요한 데이터만 담아서 Orders 생성
→ 동일한 데이터가 Orders와 Users에 저장됨, 데이터의 무결성 보장 X
나. Sharding
•
Sharding: 큰 데이터의 집합을 작은 데이터의 집합으로 분리하는 것
→ 사전적 의미: 전체에서 작은 부분으로 분리하는 것
•
동작원리
◦
App Server에서 쿼리 수행함에 따라 mongos와 통신
→ Mongos: app server의 쿼리요청을 shading 방식으로 처리하기 위한 중개(interface)
◦
mongos에서 Config Servers 참고하여 app server의 쿼리를 실행하기 위해 필요한 shard 선택
→ Config Server: 메타 데이터(또는 설정 정보) 저장
→ Shard: 하위 데이터 집합이 저장된 인스턴스
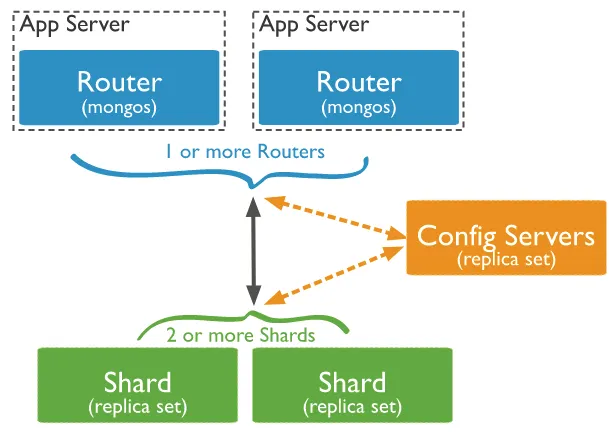
Image from https://tmjb.tistory.com/39
다. SQL vs NoSQL: how to choose?
•
How data will be queried?
→ SQL
- 서비스에서 엔티티 간 연계가 활발한 경우
- 개발하려는 서비스에서 테이블(또는 엔티티) 간 합쳐지는 쿼리(JOIN)가 많이 발생하는 경우
- 단순 조회 연산 외에도 갱신(추가, 수정, 삭제) 작업이 많이 필요한 경우
Plain Text
복사
→ NoSQL
- 엔티티 간 연계가 활발하지 않은 경우
- 개발하려는 서비스에서 테이블 간 관계가 복잡하지 않은 경우
- 단순 조회(SELECT) 연산으로 대부분의 기능을 제공할 수 있는 경우
Plain Text
복사
•
The type of data in question
→ SQL: 데이터 타입 고정될 경우
→ NoSQL: 데이터 타입 미고정, 유연성이 필요한 경우
•
The amount of data
→ SQL: 빅데이터 이하 처리 용이
→ NoSQL: 빅데이터 처리 용이
라. Redis
1) Redis
•
Redis(Remote Dictionary Server): in memmory 기반의 키-값 데이터 스토어
→ In memmory DB(NoSQL): 데이터를 서버 메모리에 저장하는 방식(디스크나 SSD에 저장하지 않음)
2) 특징
•
백업 방식
→ 복사본을 디스크에 저장
→ 작업로그도 디스크에 저장
•
3 copy
→ 레디스 클러스터를 구성해서 내구성 확보
3) 사용처
•
RDBMS의 캐시 솔루션으로 많이 사용됨
→ RDBMS에서 특정 데이터를 조회할 때, DISK에서 가져오는데 시간이 많이 걸림
→ Redis의 In-memory DB 특성 상 DISK에서 데이터를 바로 가져오는 것 보다 성능이 우월함
4. Big Data
가. Big Data란
•
페타바이트(수백 TB 이상)급의 매우 큰 데이터
나. Big Data 처리
•
빅데이터 플랫폼 활용
→ Hadoop, Spark, Hive, Hbase 등
5. 데이터베이스 서버
가. DB 서버의 접근 조건
•
웹 서비스의 클라이언트/서버 관계에서 사용자 인증을 전제하지 않음
•
하지만 RDBMS의 클라이언트/서버 관계어서는 사용자 인증을 전제함
→ 사용자 인증이 없다면 SQL 명령을 내릴 수 없음
→ 사용자별로 인증과정이 반드시 필요함
나. DB 서버의 클라이언트
•
웹 서비스의 클라이언트(웹브라우저)에서 특정 웹 페이지에 대한 요청을 보내면 웹 서버는 CGI 방식으로 다른 프로그램의 처리 결과를 받아서 브라우저에 응답함
•
CGI 방식으로 사용되는 프로그램이 DB 서버의 클라이언트가 됨
→ 자바와 servelt의 조합이 CGI 방식 프로그램의 대표적인 예
•
CGI(Common GateWay Interface): 공용 게이트웨이 인터페이스,
→ 웹 서버와 다른 프로그램과의 연계하기 위해 사용되는 인터페이스
6. ORM
가. ORM
나. ORM Pattern: Active Record
1) 특징
•
Model or Entity 안에 데이터베이스의 속성, 제약사항과 더불어 모델과 관련된 모든 조작이 포함됨
•
데이터베이스의 데이터가 어플리케이션에서 ‘Active’하게 관리됨
•
대표적인 기술: Django’s ORM, Ruby on Rails
2) 사용
•
overloading methods
→ 모델 객체 갱신 시 모델 객체의 인스턴스에서 함수 호출 ex) user.save
→ 모델 객체 조회 시 모델 객체에서 직접 함수 호출 ex) User.find
@Entity()
export class User extends BaseEntity {
@PrimaryGeneratedColumn()
id: number;
@Column()
firstName: string;
@Column()
lastName: string;
@Column()
isActive: boolean;
}
// example how to save AR entity
const user = new User();
user.firstName = "Timber";
user.lastName = "Saw";
user.isActive = true;
await user.save();
// example how to remove AR entity
await user.remove();
// example how to load AR entities
const users = await User.find({ skip: 2, take: 5 });
const newUsers = await User.find({ isActive: true });
const timber = await User.findOne({ firstName: "Timber", lastName: "Saw" });
Python
복사
•
custom methods
→ 모델 객체 내부에서 static 함수로 정의
→ custom method 호출 시 모델 객체의 static 함수 호출
import {BaseEntity, Entity, PrimaryGeneratedColumn, Column} from "typeorm";
@Entity()
export class User extends BaseEntity {
# 생략(위와 동일)
static findByName(firstName: string, lastName: string) {
return this.createQueryBuilder("user")
.where("user.firstName = :firstName", { firstName })
.andWhere("user.lastName = :lastName", { lastName })
.getMany();
}
}
const timber = await User.findByName("Timber", "Saw");
Python
복사
3) 장점
•
조작이 간단하므로 사용이 쉽다
•
사용이 쉬운 만큼 배우는데 시간이 적게 든다
4) 단점
•
DB와 어플리케이션 내 객체와의 결합이 강하므로 객체와 DB를 분리하는 작업이 어렵다
→ 특히 테스트에서 DB와 객체 간 강한 결합은 Unit 테스트에 어려움으로 이어진다
•
SQL performance가 상대적으로 떨어진다
다. ORM Pattern: Data Mapper(or Repository)
1) 특징
•
Model or Entity 안에는 데이터베이스의 속성, 제약사항만 포함됨
•
모델에 대한 조작은 repository를 통해 간접적으로 실행됨
•
대표적인 기술: SQLAlchemy, Java Hibernate
2) 사용
•
overloading methods
→ 모델 객체의 갱신, 조회 시 모두 repository의 함수 호출
@Entity()
export class User {
@PrimaryGeneratedColumn()
id: number;
@Column()
firstName: string;
@Column()
lastName: string;
@Column()
isActive: boolean;
}
const userRepository = connection.getRepository(User);
// example how to save DM entity
const user = new User();
user.firstName = "Timber";
user.lastName = "Saw";
user.isActive = true;
await userRepository.save(user);
// example how to remove DM entity
await userRepository.remove(user);
// example how to load DM entities
const users = await userRepository.find({ skip: 2, take: 5 });
const newUsers = await userRepository.find({ isActive: true });
const timber = await userRepository.findOne({ firstName: "Timber", lastName: "Saw" });
Python
복사
•
custom methods
→ custom method 호출 시 repository에서 함수 호출
import {EntityRepository, Repository} from "typeorm";
import {User} from "../entity/User";
@EntityRepository()
export class UserRepository extends Repository<User> {
findByName(firstName: string, lastName: string) {
return this.createQueryBuilder("user")
.where("user.firstName = :firstName", { firstName })
.andWhere("user.lastName = :lastName", { lastName })
.getMany();
}
}
const userRepository = connection.getCustomRepository(UserRepository);
const timber = await userRepository.findByName("Timber", "Saw");
Python
복사
3) 장점
•
DB와 어플리케이션 내 객체와의 결합이 약하므로 테스트 등 약한 결합이 요구되는 작업에 용이하다
•
SQL performance가 상대적으로 높다
→ 어떤 원리로?
4) 단점
•
기본 설정이 어렵고 활용이 어렵다
→ 데이터베이스의 추상화된 layer인만큼 직관성이 떨어지므로 사용에 어려움이 있다
•
사용이 어려운 만큼 학습 비용이 많이 든다
Reference
•
미트, 기무라 메이지, 데이터베이스 첫걸음
•
아사이 아츠시, SQL 첫걸음
•
정호영, 마스터즈 CS 10 중 DB part
•
오쿠노 미키야, 관계형 데이터베이스 실전입문
•
Key Constraints, https://prepinsta.com/dbms/key-constraints/